首页
web
php
html
css
vue
小程序
mysql
python
android
java
chatgpt
linux
大数据
redis
隐私协议
登录
网页内容
价格
价格
免费
付费
会员免费
会员折扣
永久会员免费
发布日期
发布日期
更新日期
评论数量
随机展示
热度排行
python
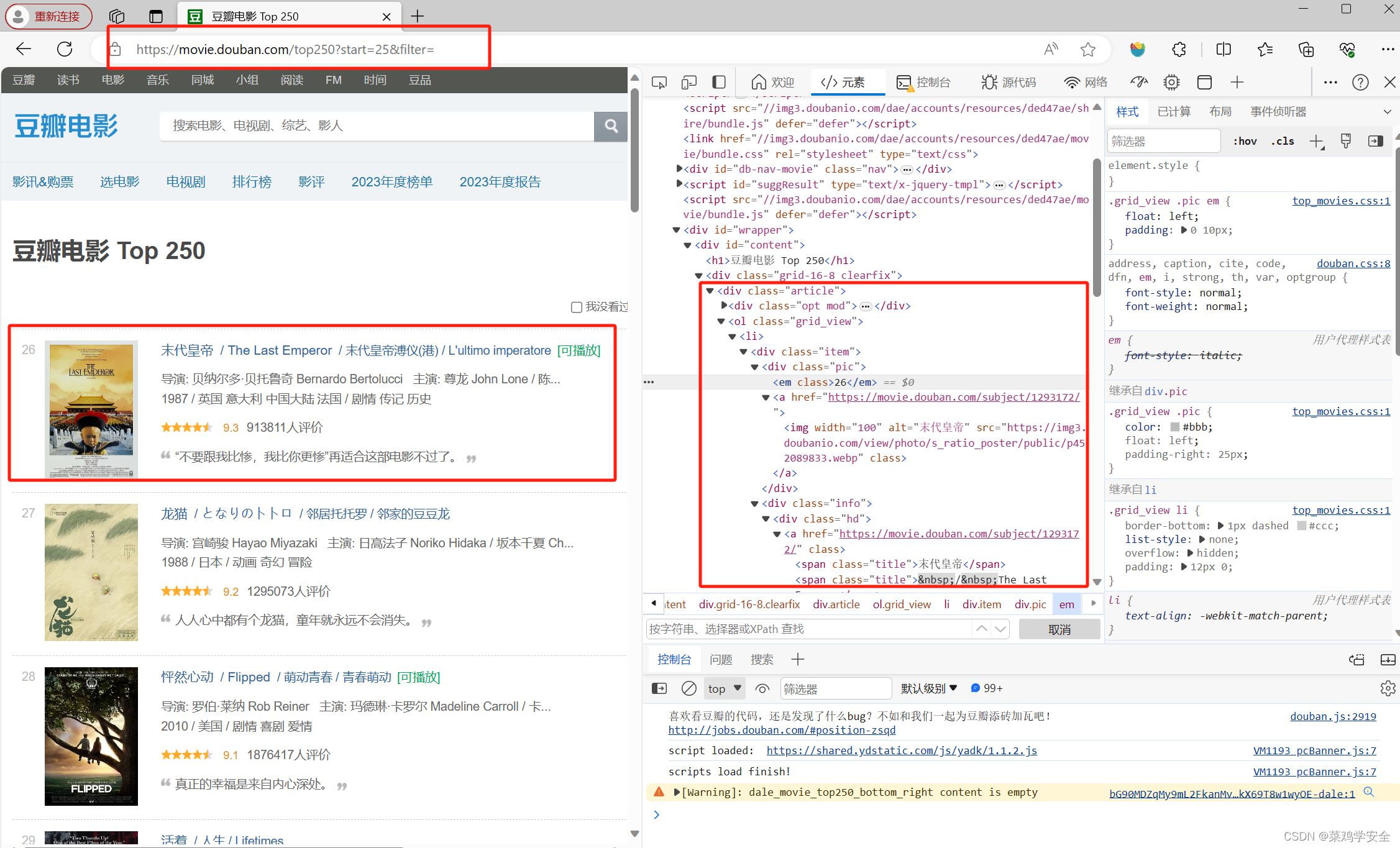
python爬虫小练习——爬取豆瓣电影top250
本文介绍: python爬虫小练习——爬取豆瓣电影top250,爬取网页内容,解析网页内容,...
python
Python—-网络爬虫
本文介绍: get()是获取网页最常用的方式,在调用requests.get()函数后,返回...
爬虫
使用ASIRequest库进行Objective-C网络爬虫示例
本文介绍: 这个例子中,我们首先创建一个ASIHTTPRequest对象,并指定要请求的UR...
爬虫
resty-http库爬虫程序代码示例
本文介绍: 然后,它执行了一个HTTP GET请求,获取了网页内容,并将获取的网页内容打印出...
爬虫
基于ChatGPT等大模型快速爬虫提取网页内容
本文介绍: 本文将介绍一种基于ChatGPT等大模型快速爬虫提取网页内容的方法。传统的爬虫方...
首页
我的
顶部
全部
ajax
android
apache
bash
centos
chatgpt
css
dedecms
django
echarts
elementui
ffmpeg
golang
html
java
jquery
layui
linux
mysql
news
nginx
node.js
nodejs
npm
objective-c
pandas
php
pip
python
redis
spring
swift
thinkphp
tomcat
typescript
uniapp
vue
webview
wordpress
xcode
互联网
大数据
小程序
数据库
正则
爬虫
缓存
全部
android
css
html
html
java
java
linux
linux
mysql
mysql
python
python
redis
spring
vue
vue
互联网
安装
首页
web
►
php
html
css
vue
小程序
mysql
python
android
java
chatgpt
linux
大数据
redis
隐私协议