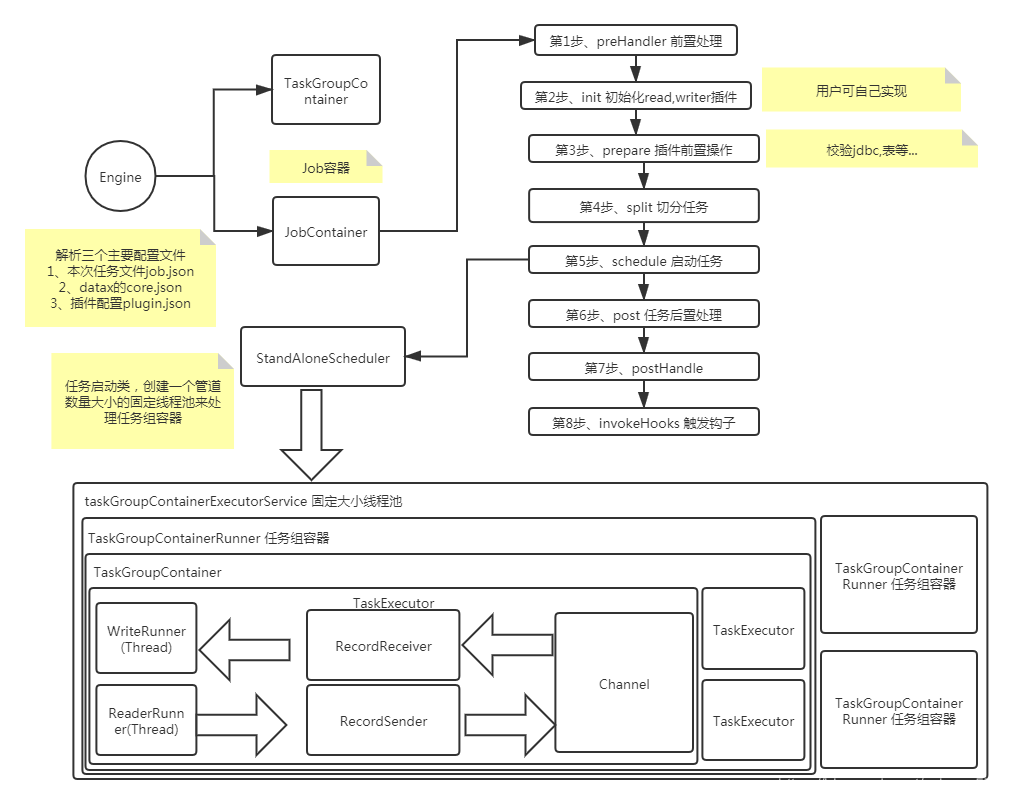
Hive默认使用MapReduce作为执行引擎,即Hive on MapReduce。实际上,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark。因此,Hive on Spark也会比Hive on MapReduce快。由于Hive on MapReduce的缺陷,所以企业里基本上很少使用了。通过SparkSQL,加载Hive的配置文件,获取到Hive的元数据信息;获取到Hive的元数据信息之后可以拿到Hive表的数据;