本文介绍: 基于网络结构的链路预测算法被广泛的应用于信息推荐系统中。算法不考虑用户和产品的内容特征,把它们看成抽象的节点,利用用户对产品的选择关系构建二部图。为用户评估它从未关注过的产品,预测用户潜在的消费倾向。
资源下载地址:https://download.csdn.net/download/sheziqiong/88490254
资源下载地址:https://download.csdn.net/download/sheziqiong/88490254
分类技术—二分网络上的链路预测
一、实验内容
基于网络结构的链路预测算法被广泛的应用于信息推荐系统中。算法不考虑用户和产品的内容特征,把它们看成抽象的节点,利用用户对产品的选择关系构建二部图。为用户评估它从未关注过的产品,预测用户潜在的消费倾向。
二、设计与分析
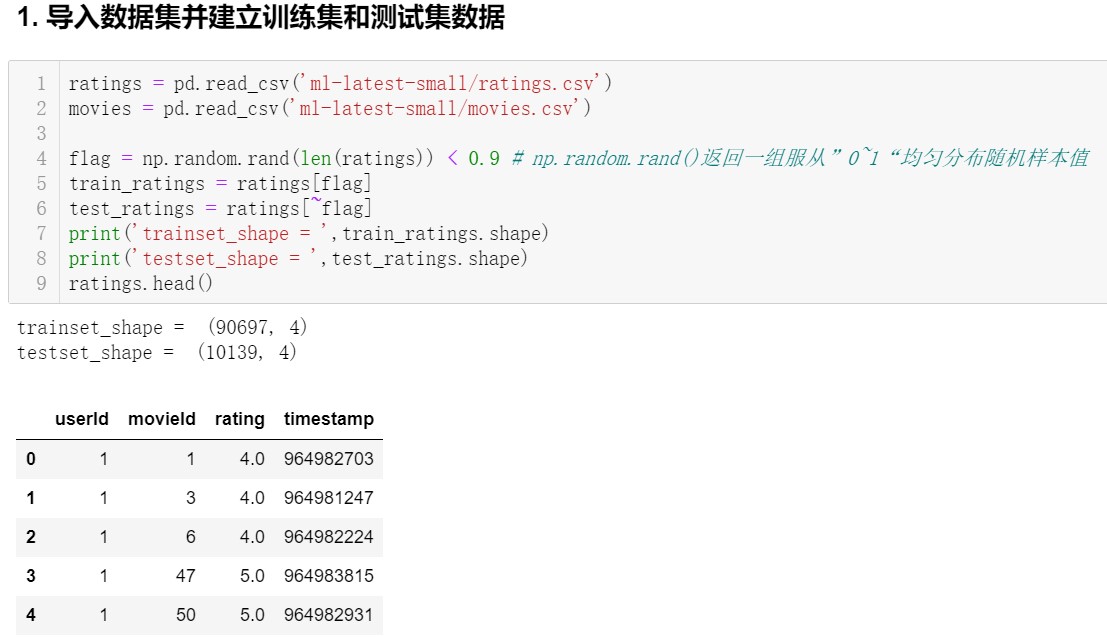
实验给定的数据类型为.csv,则使用 Pandas 库进行数据处理。
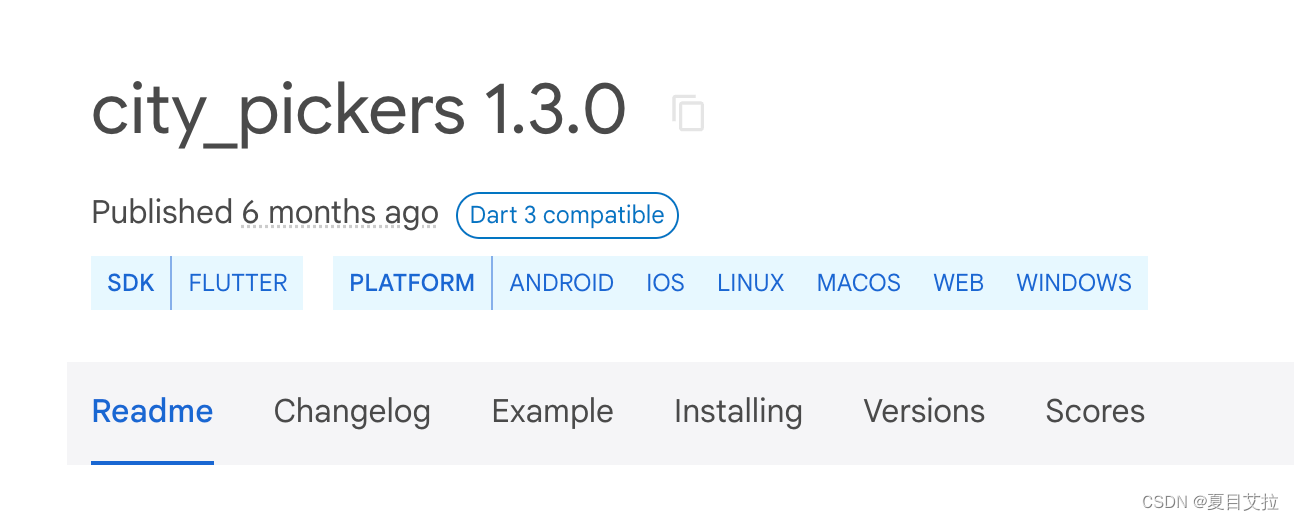
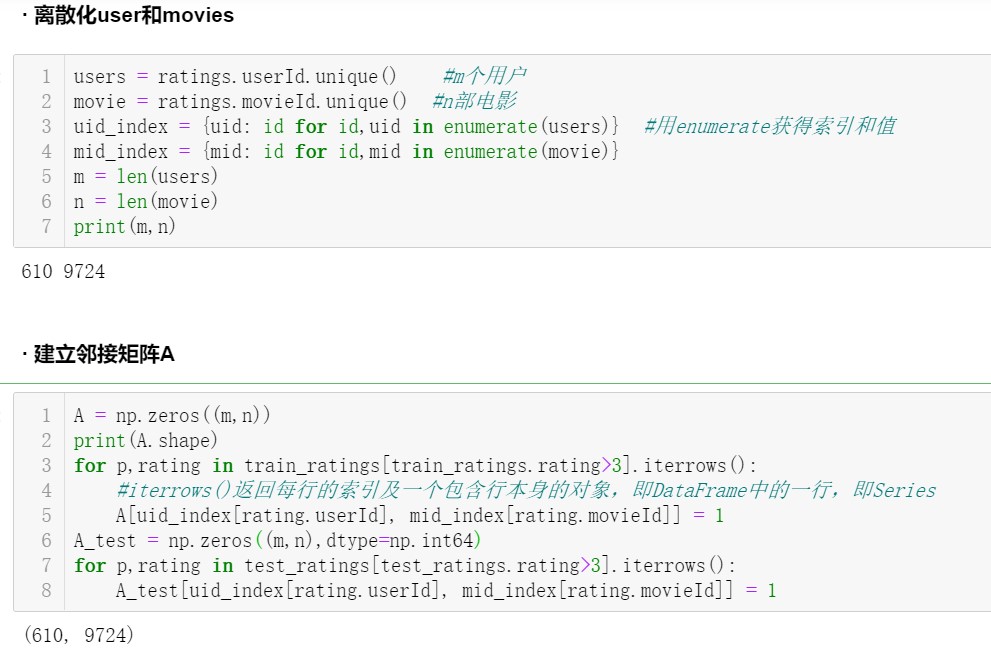
由训练集数据构建矩阵 A,该矩阵是一个 m*n 的矩阵,其中 m 为用户人数,n 为影片数量。矩阵中的值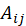 表示用户 i 对电影 j 喜爱与否,若
表示用户 i 对电影 j 喜爱与否,若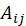 =1,则表示用户 i 喜爱电影 j,反之则不喜爱。
=1,则表示用户 i 喜爱电影 j,反之则不喜爱。
每一用户对其看过的电影都有打分,我们设定分值 3 为阈值,大于 3 分的即表示喜爱(即将不喜爱与未评价的电影不区分对待,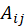 值都等于 0)。
值都等于 0)。
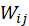 反映的是电影 j 与电影 i 的兴趣
反映的是电影 j 与电影 i 的兴趣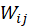 表示电影 j 愿意分配给电影 i 的
表示电影 j 愿意分配给电影 i 的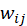 值的
值的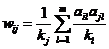
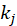 表示产品的度(即有多少用户喜爱电影 j),
表示产品的度(即有多少用户喜爱电影 j), 表示每一个用户,
表示每一个用户,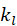
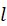 喜爱多少部电影)。很显然,电影 j 与电影 i 的兴趣
喜爱多少部电影)。很显然,电影 j 与电影 i 的兴趣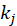 和
和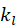 成反比。形式化解释如下:
成反比。形式化解释如下: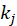 很大),那么电影 j 就可能是一个泛化的热门电 影,用户喜爱电影 j 就并不意味着他有强烈的喜爱电影 i 的倾向。
很大),那么电影 j 就可能是一个泛化的热门电 影,用户喜爱电影 j 就并不意味着他有强烈的喜爱电影 i 的倾向。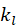 很大),那么他喜爱电影 j,就并不意味着他对电影 j 非常专注,相应的推荐度也就不那么高。
很大),那么他喜爱电影 j,就并不意味着他对电影 j 非常专注,相应的推荐度也就不那么高。完成实验任务一:向用户做出电影推荐
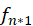 表示该用户选择的电影的选择矩阵,则
表示该用户选择的电影的选择矩阵,则 为一个 n*1 的列
为一个 n*1 的列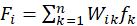 表示电影 i 对用户的吸引程度,将用户所有未选择(没看过)的电影按照 F 中
表示电影 i 对用户的吸引程度,将用户所有未选择(没看过)的电影按照 F 中完成实验任务二——模型准确性预测
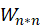 与喜爱矩阵 A 的转置
与喜爱矩阵 A 的转置 做矩阵相乘再转置
做矩阵相乘再转置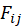 表示由
表示由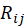 位,则计算其相对
位,则计算其相对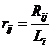
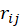 越小。对所有用户的
越小。对所有用户的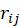 求
求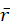 来
来三、实现详细
导入数据集,并随机分为两部分
构建“用户—电影”喜爱矩阵 A
根据喜爱矩阵 A 计算资源分配矩阵 W

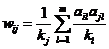 ,这种
,这种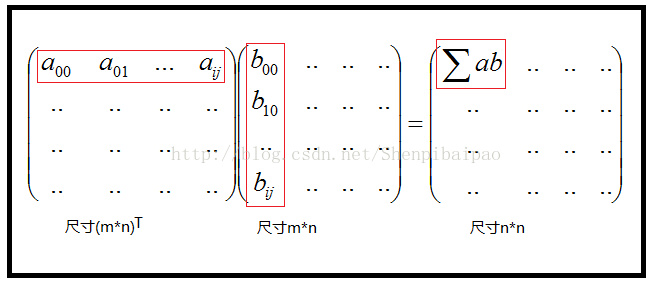
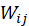 的计算
的计算完成实验任务一—做出推荐
完成实验任务二—模型准确性预测

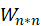 与喜爱矩阵 A 的转置
与喜爱矩阵 A 的转置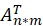 做矩阵相乘再转置
做矩阵相乘再转置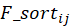 值表示对于用户 i,电影 j 在所有电影中的吸引度排名名次。
值表示对于用户 i,电影 j 在所有电影中的吸引度排名名次。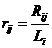 计算平均推荐相对
计算平均推荐相对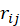 ,再计算该人的平均相对
,再计算该人的平均相对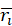 ,
,
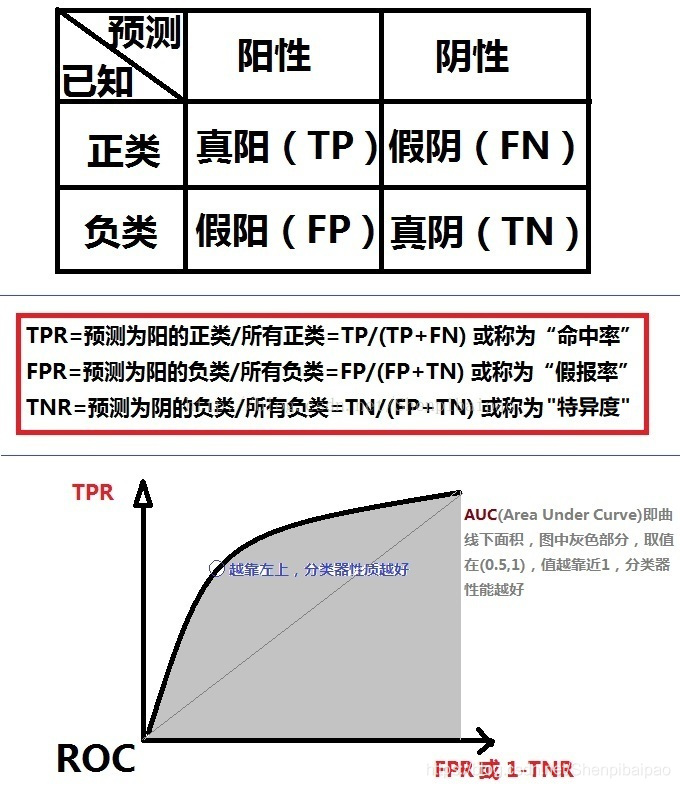
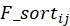 的关系我们
的关系我们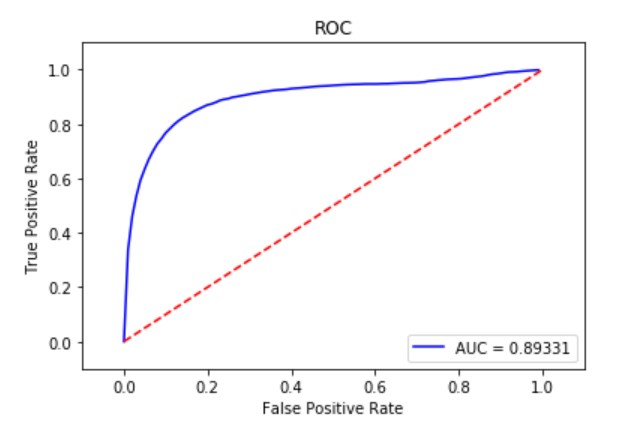
四、实验结果

五、结论
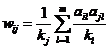 ,这就是我们要训练的模型。
,这就是我们要训练的模型。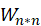 与喜爱矩阵 A 的转置
与喜爱矩阵 A 的转置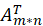 做矩阵相乘再转置
做矩阵相乘再转置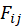 表示由我们分配模型计算出来的 j 电影对 i 用户的吸引程度,
表示由我们分配模型计算出来的 j 电影对 i 用户的吸引程度, ,并计算出 r 的
,并计算出 r 的声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。