本文介绍: map task的计算结果会根据分区器(默认是hashPartitioner)来决定写入到哪一个磁盘小文件中去。ReduceTask会去Map端拉取相应的磁盘小文件。.产生的磁盘小文件的个数:M(map task的个数)*R(reduce task的个数)产生磁盘小文件的个数:C(core的个数)*R(reduce的个数)产生磁盘小文件的个数: 2*M(map task的个数)
三、Spark Master HA
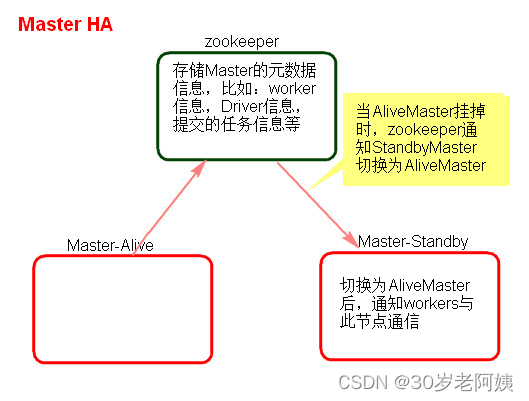
1、Master的高可用原理
Standalone集群只有一个Master,如果Master挂了就无法提交应用程序,需要给Master进行高可用配置,Master的高可用可以使用fileSystem(文件系统)和zookeeper(分布式协调服务)。
fileSystem只有存储功能,可以存储Master的元数据信息,用fileSystem搭建的Master高可用,在Master失败时,需要我们手动启动另外的备用Master,这种方式不推荐使用。
zookeeper有选举和存储功能,可以存储Master的元素据信息,使用zookeeper搭建的Master高可用,当Master挂掉时,备用的Master会自动切换,推荐使用这种方式搭建Master的HA。
2、Master高可用搭建
1)、在Spark Master节点上配置主Master,配置spark–env.sh
![]()
2)、发送到其他worker节点上
3)、找一台节点(非主Master节点)配置备用 Master,修改spark–env.sh配置节点上的MasterIP
4)、启动集群之前启动zookeeper集群
5)、启动spark Standalone集群,启动备用Master
6)、打开主Master和备用Master WebUI页面,观察状态
3、注意点
4、测试验证
四、Spark Shuffle
1、SparkShuffle概念
2、HashShuffleManager
1)、普通机制
普通机制示意图
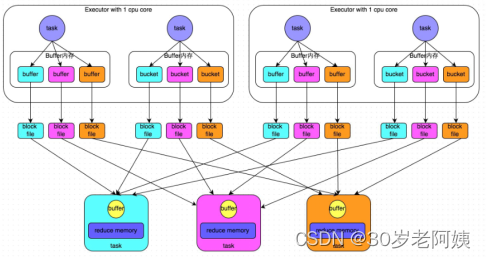
执行流程
总结
存在的问题
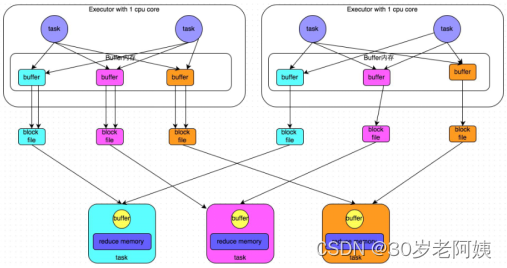
2)、合并机制
合并机制示意图
总结
3、SortShuffleManager
1)、普通机制
普通机制示意图

执行流程
总结
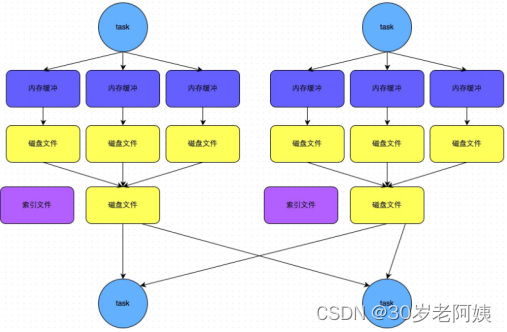
2)、bypass机制
bypass机制示意图
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




