简介
APScheduler的全称是Advanced Python Scheduler。它是一个轻量级的 Python 定时任务调度框架。APScheduler 支持三种调度任务:固定时间间隔,固定时间点(日期),Linux 下的 Crontab命令。同时,它还支持异步执行、后台执行调度任务。
安装APScheduler
pip install APScheduler
使用APScheduler 步骤
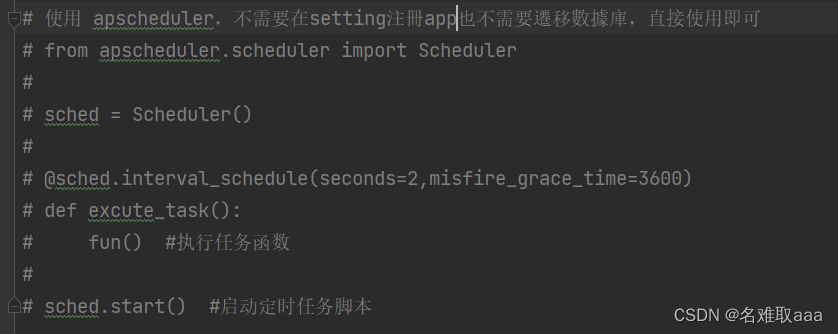
APScheduler 使用起来还算是比较简单。运行一个调度任务只需要以下三部曲
簡單示例
from apscheduler.scheduler import Scheduler
sched = Scheduler()
@sched.interval_schedule(seconds=2,misfire_grace_time=3600)
def excute_task():
fun() #执行任务函数
sched.start() #启动定时任务脚本
python manage.py runserver 8000
基础组件
APScheduler 有四种组件,分别是:调度器(scheduler),作业存储(job store),触发器(trigger),执行器(executor)。
-
任务持久化仓库,默认保存任务在内存中,也可将任务保存都各种数据库中,任务中的数据序列化后保存到持久化数据库,从数据库加载后又反序列化。
-
负责处理作业的运行,它们通常通过在作业中提交指定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
schedulers(调度器)
提供 7种调度器,能够满足我们各种场景的需要。例如:后台执行某个操作,异步执行操作等。调度器分别是:
- BlockingScheduler
调度器在当前进程的主线程中运行,也就是会阻塞当前线程。 - BackgroundScheduler
调度器在后台线程中运行,不会阻塞当前线程。 - AsyncIOScheduler
结合 asyncio 模块(一个异步框架)一起使用 - GeventScheduler
程序中使用 gevent(高性能的Python并发框架)作为IO模型,和 GeventExecutor 配合使用。 - TornadoScheduler
程序中使用 Tornado(一个web框架)的IO模型,用 ioloop.add_timeout 完成定时唤醒。 - TwistedScheduler
配合 TwistedExecutor,用 reactor.callLater 完成定时唤醒 - QtScheduler
你的应用是一个 Qt 应用,需使用QTimer完成定时唤醒。
triggers(触发器)
APScheduler 有三种内建的 trigger
date 触发器
date 是最基本的一种调度,作业任务只会执行一次。它表示特定的时间点触发。它的参数如下:
| 参数 | 说明 |
|---|---|
| run_date (datetime 或 str) | 作业的运行日期或时间 |
| timezone (datetime.tzinfo 或 str) | 指定时区 |
date 触发器使用示例如下:
from datetime import datetime
from datetime import date
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print(text)
scheduler = BackgroundScheduler()
# 在 2017-12-13 时刻运行一次 job_func 方法
scheduler .add_job(job_func, 'date', run_date=date(2017, 12, 13), args=['text'])
# 在 2017-12-13 14:00:00 时刻运行一次 job_func 方法
scheduler .add_job(job_func, 'date', run_date=datetime(2017, 12, 13, 14, 0, 0), args=['text'])
# 在 2017-12-13 14:00:01 时刻运行一次 job_func 方法
scheduler .add_job(job_func, 'date', run_date='2017-12-13 14:00:01', args=['text'])
scheduler.start()
interval 触发器
| 参数 | 说明 |
|---|---|
| weeks (int) | 间隔几周 |
| days (int) | 间隔几天 |
| hours (int) | 间隔几小时 |
| minutes (int) | 间隔几分钟 |
| seconds (int) | 间隔多少秒 |
| start_date (datetime 或 str) | 开始日期 |
| end_date (datetime 或 str) | 结束日期 |
| timezone (datetime.tzinfo 或str) | 时区 |
interval 触发器使用示例如下:
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
# 每隔两分钟执行一次 job_func 方法
scheduler .add_job(job_func, 'interval', minutes=2)
# 在 2017-12-13 14:00:01 ~ 2017-12-13 14:00:10 之间, 每隔两分钟执行一次 job_func 方法
scheduler .add_job(job_func, 'interval', minutes=2, start_date='2017-12-13 14:00:01' , end_date='2017-12-13 14:00:10')
scheduler.start()
cron 触发器
在特定时间周期性地触发,和Linux crontab格式兼容。它是功能最强大的触发器。
我们先了解 cron 参数:
| 参数 | 说明 |
|---|---|
| year (int 或 str) | 年,4位数字 |
| month (int 或 str) | 月 (范围1-12) |
| day (int 或 str) | 日 (范围1-31 |
| week (int 或 str) | 周 (范围1-53) |
| day_of_week (int 或 str) | 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun) |
| hour (int 或 str) | 时 (范围0-23) |
| minute (int 或 str) | 分 (范围0-59) |
| second (int 或 str) | 秒 (范围0-59) |
| start_date (datetime 或 str) | 最早开始日期(包含) |
| end_date (datetime 或 str) | 最晚结束时间(包含) |
| timezone (datetime.tzinfo 或str) | 指定时区 |
cron 触发器使用示例如下:
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
def job_func(text):
print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
# 在每年 1-3、7-9 月份中的每个星期一、二中的 00:00, 01:00, 02:00 和 03:00 执行 job_func 任务
scheduler .add_job(job_func, 'cron', month='1-3,7-9',day='0, tue', hour='0-3')
scheduler.start()
作业存储(job store)
添加 job
有两种添加方法,其中一种上述代码用到的 add_job(), 另一种则是scheduled_job()修饰器来修饰函数。
这个两种办法的区别是:第一种方法返回一个 apscheduler.job.Job 的实例,可以用来改变或者移除 job。第二种方法只适用于应用运行期间不会改变的 job。
import datetime
from apscheduler.schedulers.background import BackgroundScheduler
@scheduler.scheduled_job(job_func, 'interval', minutes=2)
def job_func(text):
print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3])
scheduler = BackgroundScheduler()
scheduler.start()
移除 job
移除 job 也有两种方法:remove_job() 和 job.remove()。
remove_job() 是根据 job 的 id 来移除,所以要在 job 创建的时候指定一个 id。
job.remove() 则是对 job 执行 remove 方法即可
scheduler.add_job(job_func, 'interval', minutes=2, id='job_one')
scheduler.remove_job(job_one)
job = add_job(job_func, 'interval', minutes=2, id='job_one')
job.remvoe()
获取 job 列表
通过 scheduler.get_jobs() 方法能够获取当前调度器中的所有 job 的列表
修改 job
如果你因计划改变要对 job 进行修改,可以使用Job.modify() 或者 modify_job()方法来修改 job 的属性。但是值得注意的是,job 的 id 是无法被修改的。
scheduler.add_job(job_func, 'interval', minutes=2, id='job_one')
scheduler.start()
# 将触发时间间隔修改成 5分钟
scheduler.modify_job('job_one', minutes=5)
job = scheduler.add_job(job_func, 'interval', minutes=2)
# 将触发时间间隔修改成 5分钟
job.modify(minutes=5)
关闭 job
默认情况下调度器会等待所有正在运行的作业完成后,关闭所有的调度器和作业存储。如果你不想等待,可以将 wait 选项设置为 False。
scheduler.shutdown()
scheduler.shutdown(wait=false)
执行器(executor)
执行器顾名思义是执行调度任务的模块。最常用的 executor 有两种:ProcessPoolExecutor 和 ThreadPoolExecutor
下面是显式设置 job store(使用mongo存储)和 executor 的代码的示例。
from pymongo import MongoClient
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.jobstores.mongodb import MongoDBJobStore
from apscheduler.jobstores.memory import MemoryJobStore
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
def my_job():
print 'hello world'
host = '127.0.0.1'
port = 27017
client = MongoClient(host, port)
jobstores = {
'mongo': MongoDBJobStore(collection='job', database='test', client=client),
'default': MemoryJobStore()
}
executors = {
'default': ThreadPoolExecutor(10),
'processpool': ProcessPoolExecutor(3)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults)
scheduler.add_job(my_job, 'interval', seconds=5)
try:
scheduler.start()
except SystemExit:
client.close()
安装Django_apscheduler
pip install django-apscheduler
使用Django_apscheduler步骤
- 創建app
python manage.py startapp test
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'django_apscheduler',
'apps.test' # 注意,我这里是在外层包了一个apps的文件夹
]
from django.urls import path
from apps.test import views
urlpatterns = [
]
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('apps.test.urls')),
]
- 执行迁移
python manage.py migrate
没有其他表结构不必运行 python manage.py makemigrations
会创建两张表:django_apscheduler_djangojob/django_apscheduler_djangojobexecution
通过进入后台管理能方便管理定时任务。

django_apscheduler_djangojob 表保存注册的任务以及下次执行的时间
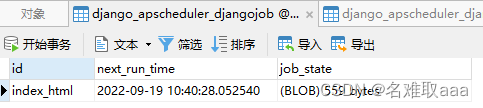
django_apscheduler_djangojobexecution 保存每次任务执行的时间和结果和任务状态

这里注意 status為executed是執行,missed 则是表示撞车的场景, 为避免这种场景需要在 周期的长度以及是否进行强制结束进行选择
from django.shortcuts import render
# Create your views here.
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job,DjangoResultStoreMixin
# 实例化调度器
scheduler = BackgroundScheduler()
# 开启定时工作
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 设置定时任务,选择方式为interval,时间间隔为10s
# 另一种方式为每天固定时间执行任务,对应代码为:
# @register_job(scheduler, 'cron', day_of_week='mon-fri', hour='9', minute='30', second='10',id='task_time')
@register_job(scheduler, "interval", seconds=10,id='test_job', replace_existing=True) # replace_existing=解决第二次启动失败的问题
def my_job():
# 这里写你要执行的任务
pass
# register_events(scheduler) 最新的django_apscheduler已经不需要这一步
scheduler.start()
最好為job加上id ,不加也可以
注意: 需要加上replace_existing=True 否則會報以下錯誤,即id重複
raise ConflictingIdError(job.id)
apscheduler.jobstores.base.ConflictingIdError: 'Job identifier (index_html) conflicts with an existing job'
提示:也可以不寫在Django工程目录下的urls.py文件中(主urls.py)或者子應用的urls.py 中,百度說可以寫在view.py 中或其他隨便哪個文件中,但是我沒試成功過,
- 運行django項目(運行server)
python manage.py runserver 8000
例子
在urls.py 中寫入
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job
scheduler = BackgroundScheduler()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 时间间隔3秒钟打印一次当前的时间
@register_job(scheduler, "interval", seconds=3, id='test_job')
def test_job():
print("我是apscheduler任务")
# per-execution monitoring, call register_events on your scheduler
register_events(scheduler)
scheduler.start()
print("Scheduler started!")
運行結果:
打印的Scheduler started!在最上面,一運行就出現
APScheduler中两种调度器的区别及使用过程中要注意的问题
APScheduler中有很多种不同类型的调度器,BlockingScheduler与BackgroundScheduler是其中最常用的两种调度器。区别主要在于BlockingScheduler会阻塞主线程的运行,而BackgroundScheduler不会阻塞。所以,我们在不同的情况下,选择不同的调度器:
-
BlockingScheduler: 调用start函数后会阻塞当前线程。当调度器是你应用中唯一要运行的东西时(如上例)使用
-
BackgroundScheduler: 调用start后主线程不会阻塞。当你不运行任何其他框架时使用,并希望调度器在你应用的后台执行。
BlockingScheduler的例子
from apscheduler.schedulers.blocking import BlockingScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
sched = BlockingScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
運行結果:

可见,BlockingScheduler调用start函数后会阻塞当前线程,导致主程序中while循环不会被执行到。
BackgroundScheduler的例子
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
運行結果:

可见,BackgroundScheduler调用start函数后并不会阻塞当前线程,所以可以继续执行主程序中while循环的逻辑。
通过这个输出,我们也可以发现,调用start函数后,job()并不会立即开始执行。而是等待3s后,才会被调度执行。
如何让job在start()后就开始运行
其实APScheduler并没有提供很好的方法来解决这个问题,但有一种最简单的方式,就是在调度器start之前,就运行一次job(),如下
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
if __name__=='__main__':
job()
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
運行結果:

这样虽然没有绝对做到让job在start()后就开始运行,但也能做到不等待调度,而是刚开始就运行job
如果job执行时间过长会怎么样
如果执行job()的时间需要5s,但调度器配置为每隔3s就调用一下job(),会发生什么情况呢?我们写了如下例子
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
time.sleep(5)
if __name__=='__main__':
sched = BackgroundScheduler(timezone='MST')
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
運行結果:

可见,3s时间到达后,并不会“重新启动一个job线程”,而是会跳过该次调度,等到下一个周期(再等待3s),又重新调度job()。
为了能让多个job()同时运行,我们也可以配置调度器的参数max_instances,如下例,我们允许2个job()同时运行
from apscheduler.schedulers.background import BackgroundScheduler
import time
def job():
print('job 3s')
time.sleep(5)
if __name__=='__main__':
job_defaults = { 'max_instances': 2 }
sched = BackgroundScheduler(timezone='MST', job_defaults=job_defaults)
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
運行結果:

每个job是怎么被调度的
通过上面的例子,我们发现,调度器是定时调度job()函数,来实现调度的。
那job()函数会被以进程的方式调度运行,还是以线程来运行呢?
为了弄清这个问题,我们写了如下程序:
from apscheduler.schedulers.background import BackgroundScheduler
import time,os,threading
def job():
print('job thread_id-{0}, process_id-{1}'.format(threading.get_ident(), os.getpid()))
time.sleep(50)
if __name__=='__main__':
job_defaults = { 'max_instances': 20 }
sched = BackgroundScheduler(timezone='MST', job_defaults=job_defaults)
sched.add_job(job, 'interval', id='3_second_job', seconds=3)
sched.start()
while(True):
print('main 1s')
time.sleep(1)
運行結果:

可见,每个job()的进程ID都相同,但线程ID不同。所以,job()最终是以线程的方式被调度执行
BlockingScheduler定时任务及其他方式的实现
#BlockingScheduler定时任务
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
首先看看周一到周五定时执行任务
# 输出时间
def job():
print(datetime.now().strtime("%Y-%m-%d %H:%M:%S"))
# BlockingScheduler
scheduler = BlockingScheduler()
scheduler.add_job(job, "cron", day_of_week="1-5", hour=6, minute=30)
schduler.start()
scheduler.add_job(job, 'cron', hour=1, minute=5)
hour =19 , minute =23 这里表示每天的19:23 分执行任务
hour ='19', minute ='23' 这里可以填写数字,也可以填写字符串
hour ='19-21', minute= '23' 表示 19:23、 20:23、 21:23 各执行一次任务
#每300秒执行一次
scheduler .add_job(job, 'interval', seconds=300)
#在1月,3月,5月,7-9月,每天的下午2点,每一分钟执行一次任务
scheduler .add_job(func=job, trigger='cron', month='1,3,5,7-9', day='*', hour='14', minute='*')
# 当前任务会在 6、7、8、11、12 月的第三个周五的 0、1、2、3 点执行
scheduler .add_job(job, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3')
#从开始时间到结束时间,每隔俩小时运行一次
scheduler .add_job(job, 'interval', hours=2, start_date='2018-01-10 09:30:00', end_date='2018-06-15 11:00:00')
#自制定时器
from datetime import datetime
import time
# 每n秒执行一次
def timer(n):
while True:
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
time.sleep(n)
timer(5)
BackgroundScheduler定时任务及其他方式的实现
启动异步定时任务
import time
from apscheduler.schedulers.background import BackgroundScheduler
from django_apscheduler.jobstores import DjangoJobStore, register_events, register_job
try:
# 实例化调度器
scheduler = BackgroundScheduler()
# 调度器使用DjangoJobStore()
scheduler.add_jobstore(DjangoJobStore(), "default")
# 'cron'方式循环,周一到周五,每天9:30:10执行,id为工作ID作为标记
# ('scheduler',"interval", seconds=1) #用interval方式循环,每一秒执行一次
@register_job(scheduler, 'cron', day_of_week='mon-fri', hour='9', minute='30', second='10',id='task_time')
def test_job():
t_now = time.localtime()
print(t_now)
# 监控任务
register_events(scheduler)
# 调度器开始
scheduler.start()
except Exception as e:
print(e)
# 报错则调度器停止执行
scheduler.shutdown()
原文地址:https://blog.csdn.net/m0_69082030/article/details/126939574
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_11315.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!