前言
考虑到文生视频开始爆发,比如11月份就是文生视频最火爆的一个月
- 11月3日,Runway的Gen-2发布里程碑式更新,支持4K超逼真的清晰度作品(runway是Stable Diffusion最早版本的开发商,Stability AI则开发的SD后续版本)
- 11月16日,Meta发布文生视频模型Emu Video
- 11月18日,字节跳动半路杀出发布PixelDance
- 11月21日,开发并维护Stable Diffusion后续版本的Stability AI终于发布了他们自家的生成式视频模型Stable Video Diffusion(SVD)

加之不止一个B端客户找到七月,希望帮其做文生视频的应用,故我司第一项目组准备在AIGC模特之后,做文生视频项目,最终把文生3D、文生数字人都串起来
当然,我司还是三大项目组
- 除了已经对外发布的AIGC模特生成系统外,文生图 视频 3D 数字人,都在第一项目组
- 论文审稿GPT(目前正在迭代第二版),包括后续的AI agent商用项目,在第二项目组
- 企业多文档的知识库问答(目前正在解决各种已知问题中),则在第三项目组
第一部分 文生视频的iPhone时刻:Runway先后发布Gen-1、Gen-2
1.1 Gen-1:对现有的3D动画和手机视频进行AI编辑
今2023年2月,之前开发stable diffusion最初版本的Runway提出了首个AI编辑模型Gen-1,Gen-1可以在原视频的基础上,编辑出咱们想要的视频。无论是粗糙的3D动画,还是用手机拍出来的摇摇晃晃的视频,Gen-1都可以升级出一个不可思议的效果(当然,其背后原因是Gen1 trained jointly on images and videos)
比如用几个包装盒,Gen-1就可以生成一个工厂的视频,化腐朽为神奇,就是这么简单

1.1.1 Gen-1何以做到:给图像模型增加时间线,且对图像和视频做联合训练
Gen-1对应的论文为:Structure and Content-Guided Video Synthesis with Diffusion Models,顺带说一嘴,有的文章会把这篇论文混淆成Gen2的论文,但实际上,runway只对外发布了Gen-1的论文,2的论文还没对外发,大家注意
如下图所示,我们可以基于潜在视频扩散模型(latent video diffusion models),通过给定下图中间部分的原始输入图像,然后既可以通过如下图上面部分的文字引导生成视频,也可以通过如下图下面部分的图像引导生成视频

怎么做到的呢?
- 首先,视频之所以可以通过文字引导生成,离不开文字引导图像生成的那一系列前置工作(Text–conditioned models, such as DALL-E2 and Stable Diffusion,enable novice users to generate detailed imagery given only a text prompt as input)。毕竟潜在扩散模型提供了在感知压缩空间高校合成图像的方法
- 其次,通过引入带有时间线的预训练图像模型(temporal layers into a pre–trained image model),且在图像和视频上做联合训练「即在一个大规模的无字幕视频,和配对的文本图像的数据集上进行训练( trained on a large-scale dataset of uncaptioned videos and paired text–image data)」,从而将潜在扩散模型扩展到视频生成
且Gen1提出了一个可控的结构和内容感知的视频扩散模型(We propose a controllable structure and content-aware video diffusion model),且在推理阶段可以修改由示例图像或文本引导的视频(Editing is performed entirely at inference time without
additional per-video training or pre-processing)且选择用单眼深度估计的技术来表示结构(单眼深度估计是一种计算机视觉技术,它旨在从仅使用单个摄像机拍摄的二维图像中推断出场景的三维深度信息),且由预先训练的神经网络预测嵌入表示内容(We opt to represent structure with monocular depth estimates and content with embeddings predicted by a pre-trained neural network)
- 然后在视频生成的过程中提供了几种控制模式
首先,类似于image synthesis models,训练我们的模型,使得其可以推断视频的内容,例如他们的外观或风格,及匹配用户提供的图像或文本提示
第二,受到扩散过程的启发,我们将information obscuring process应用到structure representation,以选择模型对给定结构的坚持程度(we apply an information obscuring process to the structure representation to enable selecting of how strongly the model adheres to the given structure)
最后,我们还对推理过程进行了调整,通过自定义指导方法,以及受classifier-free guidance的启发,以控制生成的剪辑的时间一致性(to enable control over temporal consistency in generated clips),相当于做到了时间、内容、结构三者在一致上的统一对齐
1.1.2 Gen1的训练过程、推理过程的详解
咱们模型的目标是保留视频结构的同时(结构一般指视频的几何、动力学的特征,比如对象的形状、位置以及他们的时间变化),编辑视频的内容(内容一般指的是视频外观及其语义的特征,比如对象的颜色、样式以及场景的光亮度)
为了实现这一目标,我们需要学习视频的生成模型
,基于结构表示
、内容表示
,从而通过输入的视频推断出其结构表示
,然后根据编辑视频的描述文本
进行修改(modify it based on a text prompt c describing the edit),如下图所示
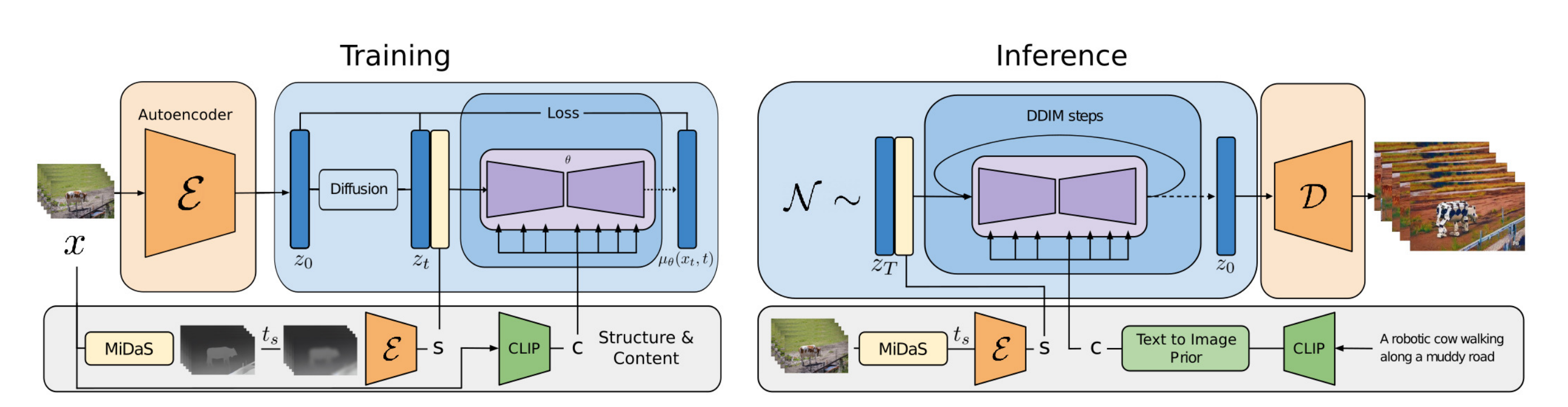
- 在上图左侧的训练过程中,输入的视频x用一个固定的编码器E编码到
,并扩散到
另一边,通过对“使用MiDaS获得的depth maps”进行编码,来提取一个结构表示,并通过使用CLIP对其中一个帧进行编码,来提取内容表示
(We extract a structure representation s by encoding depth maps obtained with MiDaS, and a content representation c by encoding one of the frames with CLIP. )
然后,在、以及通过交叉注意块提供的
- 在上图右侧的推理过程中,输入视频的结构
1.1.2.1 对潜在扩散模型的回顾
扩散模型的正向扩散过程被定义为
将符合正太分布的噪声缓慢添加到每个样本,得到
,该正向扩散过程模拟一个马尔科夫链,噪声的方差为
,而
至于逆向过程则根据以下公式定义
其中,方差是固定的,只需学习其中的均值
即可,我们需要优化目标的损失函数即为
最终转化为
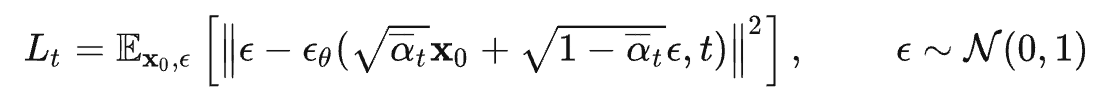
友情提醒,如果你对上述扩散模型DDPM的推导有任何疑问,可参见此文的第二部分《AI绘画能力的起源:从VAE、扩散模型DDPM、DETR到ViT/Swin transformer》,对关于DDPM的每一步骤的推导都非常详尽
1.1.2.2 时空潜在扩散(Spatio-temporal Latent Diffusion)
- 引入时间层来扩展图像架构,且这些时间层仅对视频输入有效,另自动编码器保持固定并独立处理视频中的每一帧
we extend an image architecture by introducing temporal layers, which are only active for video inputs. All other layers are shared between the image and video model. The autoencoder remains fixed and processes each frame in a video independently. - UNet主要由两个模块组成:残差块和transformer块,通过添加跨时间的一维卷积和跨时间的一维自注意力将它们扩展到视频(we extend them to videos by adding both 1D convolutions across time and 1D self–attentions across time)
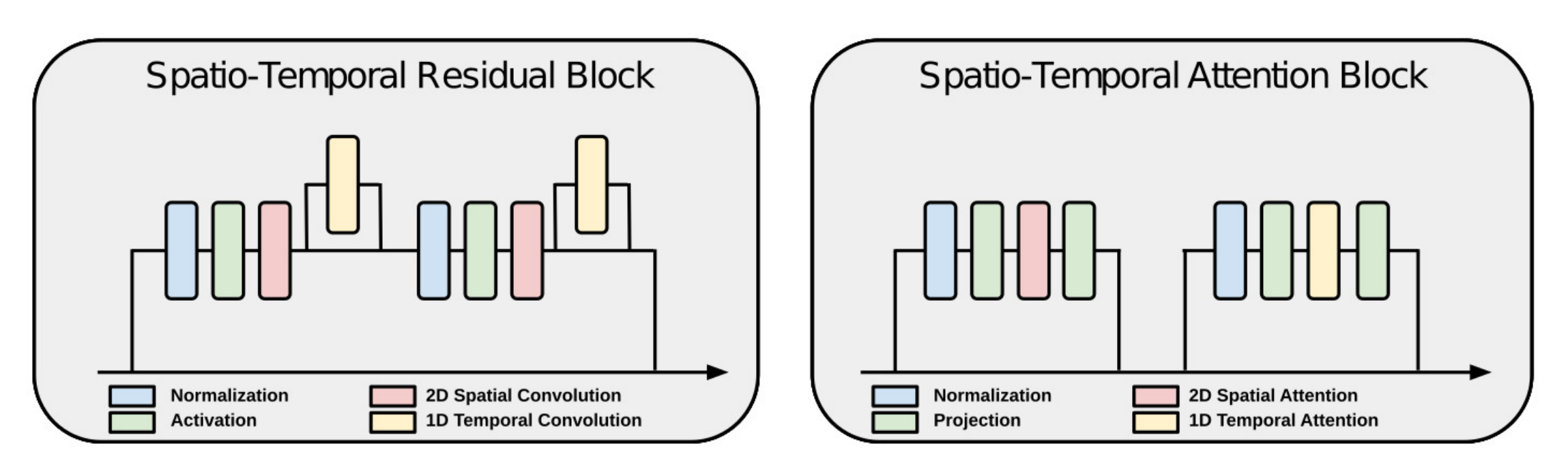
在每个残差块中,如上图左侧所示,在每个2D卷积之后引入一个时间卷积(In each residual block, we introduce one temporal convolution after each 2D convolution)
同样的,如上图右侧所示,在每个2D transformer块后,我们都包含一个temporal 1D transformer block, which mimics its spatial counterpart along the time axis,且将learnable positional encodings of the frame index输入到temporal transformer blocks中 - 最终实现时,将图像视为只有单帧的视频,以统一处理这两种情况
批量大小为b、帧数为n、通道数为c、空间分辨率为w ✖️ h,即形状为b × n × c × h × w的分批张量,被重新排列为w × h (i.e. shape b × n × c × h × w) is rearranged to (b · n) × c × h × w for spatial layers, to (b · h · w) × c × n for temporal convolutions, and to (b · h · w) × n × c for temporal self–attention
//待更
1.1.2.3 结构与内容的表示(Representing Content and Structure)
扩散模型非常适合对等条件分布进行建模,由于大规模配对的视频-文本数据集比较缺乏,所以只能限制在无字幕的视频数据上进行训练
- 总之,我们的目标是根据用户提供的编辑视频的文本提示来编辑视频,但还是面临一个问题:即我们没有视频三元组的训练数据、编辑prompt、和生成的输出,也没有成对的视频和文本字幕(Thus, while our goal is to edit an input video based on a text prompt describing the desired edited video, we have neither training data of triplets with a video, its edit prompt and the resulting output, nor even pairs of videos and text captions)
- 因此,我们必须从训练视频
本身导出结构和内容的表示,即
、
,从而损失函数为
- 相反,在推理过程中,结构
和内容
分别来自输入视频
和文本提示
, edited version x of y通过对以
、
为条件的生成模型进行采样获得的
内容表示层面上
- 为了从文本输入x和视频输入x都可以推断出内容表示(content representation),我们利用CLIP的image embeddings来表示 represent content.
对于视频输入,我们在训练期间随机选择一个输入帧,类似于可以训练一个先验模型,该模型允许从text embeddings中采样image embeddings,这种方法可以通过图像输入而非文本来指定编辑This approach enables - 待更..

// 待更
1.2 Gen-2获得了史诗级的升级——可以从头开始生成视频
很多同学还没来得及体验Gen-1,没想到在2023年3月份,runway很快又推出了Gen-2的内测版本,并于6月份正式对外发布(这是runway对Gen-2介绍的页面:https://research.runwayml.com/gen2),相比Gen-1,Gen-2获得了史诗级的升级——可以从头开始生成视频。如果说去年发布的stable diffusion/midjourney是文生图的代表,那Gen2便是文生视频的第一个代表
- Gen-2刚开始发布时还只能生成4秒钟的视频,每个用户的免费试用额度为105秒,即可以生成约26个Gen2视频
- 到了8月份,生成视频的最大长度便从4s提升到了18s
- 9月,新增导演模式,可以控制镜头的位置和移动速度
1.2.1 基于Gen-2生成视频的8种模式
1.2.2 Gen-2在23年11月的更新:生成视频4K超高清且涂哪动哪
23年11月3日,Runway的Gen-2发布里程碑式更新,支持4K超逼真的清晰度作品
且11月21日,上线“涂哪动哪”的运动笔刷新功能,直接标志出生成模型可控性上的一个重要里程碑

// 待更
第二部分 Meta发布生成式视频模型:Emu Video
11月16日,Meta发布文生视频模型Emu Video,该模型既支持灵活的图像编辑(例如把「兔子」变成「吹小号的兔子」,再变成「吹彩虹色小号的兔子」),也支持根据文本和图像生成高分辨率视频(例如让「吹小号的兔子」欢快地跳舞)

- 灵活的图像编辑由一个叫「Emu Edit」的模型来完成。它支持通过文字对图像进行自由编辑,包括本地和全局编辑、删除和添加背景、颜色和几何转换、检测和分割等等。此外,它还能精确遵循指令,确保输入图像中与指令无关的像素保持不变
比如给鸵鸟穿裙子
- 高分辨率的视频则由一个名叫「Emu Video」的模型来生成。Emu Video 是一个基于扩散模型的文生视频模型,能够基于文本生成 512×512 的 4 秒高分辨率视频。且有人工评估表明,与 Runway 的 Gen-2 以及 Pika Labs 的生成效果相比,Emu Video 在生成质量和文本忠实度方面的得分可能更高。以下是它的生成效果:

如机器之心所述,在官方博客中,Meta 展望了这两项技术的应用前景,包括让社交媒体用户自己生成动图、表情包,按照自己的意愿编辑照片和图像等等。关于这点,Meta 在之前的 Meta Connect 大会上发布 Emu 模型时也提到过(参见:Meta 版 ChatGPT 来了:Llama 2 加持,接入必应搜索,小扎现场演示)
2.1 Emu Edit :精确的图像编辑
2.1.1 相比InstructPix2Pix的优势:更准确的执行指令
Emu Edit对应的论文为《Emu Edit: Precise Image Editing via Recognition and Generation Tasks》,其项目地址则为:https://emu-edit.metademolab.com/
如该论文中所说,如今每天都有数百万人使用图像编辑。然而,流行的图像编辑工具要么需要相当多的专业知识,使用起来很耗时,要么非常有限,仅提供一组预定义的编辑操作,如特定的过滤器。好在如今基于指令的图像编辑(Instruction-based image editing)试图让用户使用自然语言指令来解决这些限制。例如,用户可以向模型提供图像并指示其「给鸸鹋穿上消防员服装」这样的指令

然而,虽然像 InstructPix2Pix 这类基于指令的图像编辑模型可以用来处理各种给定的指令,但它们通常很难准确地解释和执行指令
instructable – pix2pix引入了一个可指导的图像编辑模型,他们通过同时利用GPT-3和Prompt-to-Prompt来开发这个模型,以生成一个用于基于指令的图像编辑的大型合成数据集,并利用该数据集来训练一个可指令的图像编辑模型
与使用合成数据集的InstructPix2Pix不同,Mag-icBrush通过要求人类使用在线图像编辑工具,开发了一个人工标注的指令引导的图像编辑数据集。然后在此数据集上微调instructable – pix2pix可以提高图像编辑能力
此外,这些模型的泛化能力有限,通常无法完成与训练时略有不同的任务,例如下图,当让小兔子吹彩虹色的小号,其他模型要么把兔子染成彩虹色,要么是直接生成彩虹色的小号

为了解决这些问题,Meta 引入了 Emu Edit,这是首个在多样化的任务上训练而成的图像编辑模型,Emu Edit 可以根据指令进行自由形式的编辑,包括本地和全局编辑、删除和添加背景、颜色改变和几何变换、检测和分割等任务。
与当今许多生成式 AI 模型不同,Emu Edit 可以精确遵循指令,确保输入图像中与指令无关的像素保持不变。例如,下图左侧,用户给出指令「将草地上的小狗移除」,移除物体后的图片几乎看不出来有什么变化,再比如下图右侧,移除图片中左下角的文本,再给图片换个背景,Emu Edit 也能处理得很好:


2.1.2 成功的两个关键:多任务训练、通过交叉注意力融合任务嵌入向量和时间步嵌入
为了训练这个模型,Meta 开发了一个包含 1000 万个合成样本的数据集,每个样本都包含一个输入图像、对要执行任务的描述以及目标输出图像,而在训练方法上主要有两个关键
- 首先,我们将模型训练为跨16个不同的图像编辑任务的多任务。这些任务跨越基于区域的编辑任务、自由形式的编辑任务和计算机视觉任务,都被制定为生成任务
且为每个任务开发了独特的数据管理pipeline,Meta发现,在所有任务上训练单个模型,比在每个任务上独立训练专家模型产生更好的结果。且随着训练任务数量的增加,Emu Edit的性能也会增加 - 其次,为了有效地处理各种各样的任务,引入了学习任务嵌入(learned task embeddings)的概念,用于引导生成过程朝着正确的生成任务方向发展
Second, to process this wide array of tasks effectively,we introduce the concept of learned task embeddings,which are used to steer the generation process toward the correct generative task.具体来说,对于每个任务,都学习一个独特的任务嵌入向量,并通过交叉注意力交互将其集成到模型中,并将其添加到时间步嵌入中(we learn a unique task embedding vector, and integrate it into the model through cross–attention interactions, and by adding it to the timestep embeddings)
我们证明,学习到的任务嵌入显著增强了我们的模型从自由形式的指令中准确推断出适当的编辑类型并执行正确编辑的能力
在这个过程中,我们保持模型权重不变,并仅更新一个任务嵌入以适应新任务。我们的实验表明,Emu Edit可以快速适应新的任务,如超分辨率
下面重点解释一下学习任务嵌入( Learned Task Embedding)
为了引导生成过程走向正确的发展方向,我们为数据集中的每个任务学习一个嵌入向量
- 在训练期间,给定我们数据集中的一个样本,我们使用任务索引
,从嵌入表中获取任务的嵌入向量
,并与模型权重联合优化它(we use the task index, i, to fetch the task’s embedding vector, vi, froman embedding table, and optimize it jointly with the modelweights)
- 具体而言,我们通过交叉注意交互将任务嵌入到U-Net中,并将其添加到时间步长嵌入中(We do so by introducing the task embedding vias an additional condition to the U-Net, ϵθ. Concretely,we integrate the task embedding into the U-Net via cross–attention interactions, and by adding it to the timestep em-beddings)
// 待更
2.2 Emu Video:先生成图像,再通过图像和文本生成视频
2.2.1 EMU VIDEO:Factorizing Text-to-Video Generation by Explicit Image Conditioning
大型文生图模型在网络规模的图像-文本对上经过训练,可生成高质量的多样化图像,然问题是
- 虽然这些模型可以通过使用视频-文本对进一步适用于文本 – 视频(T2V)生成,但视频生成在质量和多样性方面仍然落后于图像生成
与图像生成相比,视频生成更具挑战性,因为它需要建模更高维度的时空输出空间,而能依据的仍然只是文本提示。此外,市面上现有的视频-文本数据集的规模通常比图像 – 文本数据集小一个数量级 - 视频生成的主流模式是使用扩散模型一次生成所有视频帧。与此形成鲜明对比的是,在 NLP 中,长序列生成被表述为一个自回归问题:以先前预测的单词为条件预测下一个单词
因此,后续预测的条件信号(conditioning signal)会逐渐变强。研究者假设,加强条件信号对高质量视频生成也很重要,因为视频生成本身就是一个时间序列
因此,Meta 的研究者提出了 EMU VIDEO,其论文为《EMU VIDEO:Factorizing Text-to-Video Generation by Explicit Image Conditioning》,其项目地址为https://emu-video.metademolab.com/,通过显式的中间图像生成步骤来增强基于扩散的文本到视频生成的条件
具体来说,他们将文生视频问题分解为两个子问题:
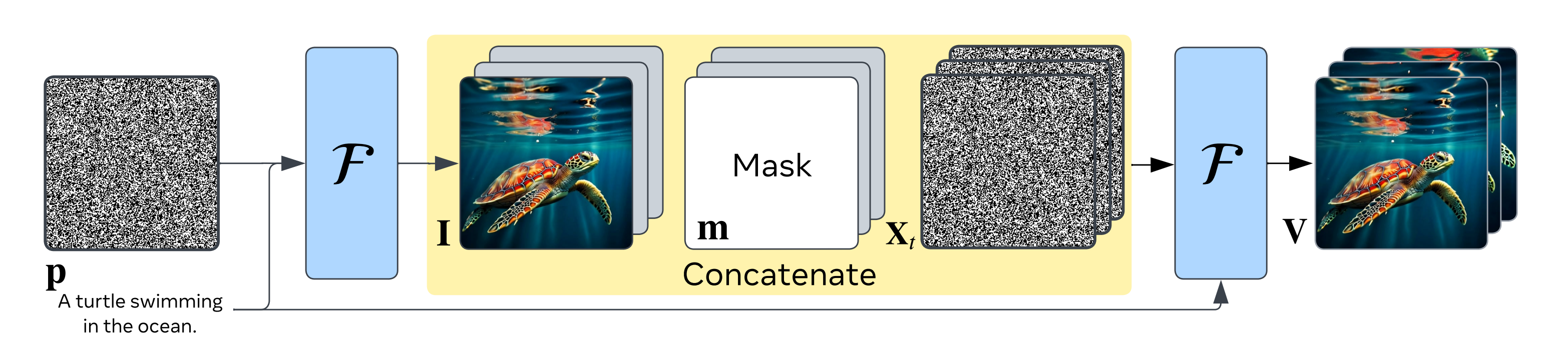
- 根据输入的文本提示
,生成图像
- 然后使用更强的条件:生成的图像和文本来生成视频
直观地说,给模型一个起始图像和文本会使视频生成变得更容易,因为模型只需预测图像在未来将如何演变即可
且,为了以图像约束模型,他们暂时对图像进行补零,并将其与一个二进制掩码(指示哪些帧是被补零的)以及带噪声的输入连接起来
那用什么样的文本到图像模型来做初始化呢?我们将文本到图像的U-Net架构用于我们的模型,并使用预训练的T2l模型初始化所有空间参数。该模型同时使用冻结的T5-XL和冻结的CLIP文本编码器从文本提示符中提取特征。U-Net中单独的cross–attention层负责每个文本特征。在初始化之后,模型包含2.7B被冻结的空间参数,以及1.7B被学习的时间参数
The model uses both a frozen T5-XL [15]and a frozen CLIP [58] text encoder to extract features fromthe text prompt. Separate cross–attention layers in the U-Net attend to each of the text features. After initialization,our model contains 2.7B spatial parameters which are kept frozen, and 1.7B temporal parameters that are learned由于视频 – 文本数据集比图像 – 文本数据集要小得多,研究者还使用权重冻结的预训练文本 – 图像(T2I)模型初始化了他们的文本 – 视频模型
且他们确定了关键的设计决策 —— 改变扩散噪声调度和多阶段训练(adjusted noiseschedules for diffusion, and multi-stage training) —— 该方法支持直接生成 512px 的高分辨率视频,不需要先前方法中使用的一些深度级联模型(without requiring a deep cascade of models as inprior work)
再说一下更多细节
- 我们用预训练的文本到图像模型初始化F,以确保它能够在初始化时生成图像
由于是从预训练的T2I模型初始化并保持冻结状态的,因此我们的模型保留了从大型图像-文本数据集中学习到的概念和风格多样性,并使用它来生成i。这不需要额外的训练成本,而不像Imagen video那样对图像和视频数据进行联合微调以保持这种风格
Since the spatial layers are initialized from a pretrained T2I model and kept frozen, our model retains the conceptual and stylistic diversity learned from large image-text datasets, and uses it to generate I. This comes at no additional training cost unlike approaches [Imagen video] that do joint finetuning on image and video data to maintain such style当然,许多直接的T2V方法[比如Align your latents: High-resolution video synthesis with latent diffusion models,再比如Make-a-video: Text-to-video generation without text-video data]也从预训练的T2I模型初始化,并保持空间层冻结。然而,它们没有采用我们基于图像的因子分解,因此不能保留T2I模型的质量和多样性
Many direct T2V ap-proaches [7, 68] also initialize from a pretrained T2I modeland keep the spatial layers frozen. However, they do notemploy our image-based factorization and thus do not re-tain the quality and diversity in the T2I model接下来,我们只需要训练F来解决第二步,即推断以文本提示和起始帧为条件的视频
我们通过对起始帧I进行采样,并要求模型同时使用文本提示pxw和图像I调节来预测T帧,从而使用视频-文本对来训练F- 由于使用潜在扩散模型,所以首先使用按帧应用的图像自动编码器将视频V转换为潜在空间X∈R T ×C×H×W,这降低了空间维度
再之后,利用自动编码器的解码器,可以将潜空间转换回像素空间(The latent space can be converted back to the pixel spaceusing the autoencoder’s decode)
视频的T帧被独立去噪,以产生去噪输入Xt,扩散模型被训练去噪(The T frames of the videoare noised independently to produce the noised input Xt,which the diffusion model is trained to denoise)- 我们使用预训练的T2I模型初始化潜在扩散模型F
像「上文1.1.2.2 时空潜在扩散(Spatio-temporal Latent Diffusion)」所述的一样,我们添加了新的可学习的时间参数:
原始的空间卷积层和注意力层被独立应用到每个T帧上,并保持冻结预训练的T2I模型已经是文本条件,结合上面描述的图像条件,F同时是文本和图像条件
The pretrained T2I model is already text conditioned and combined with the image conditioning described above,Fis conditioned on both text and image
最终如此操作带来的好处是
- 与直接用文本生成视频的方法不同,他们的分解方法在推理时会显式地生成一张图像,这使得他们能够轻松保留文生图模型的视觉多样性、风格和质量,如下图所示
这使得 EMU VIDEO 即使在训练数据、计算量和可训练参数相同的情况下,也能超越直接 T2V 方法

- 且比如通过多阶段的训练方法,文生视频的生成质量可以得到大幅提高

2.2.2 如何延长生成视频的时长
从展示的 demo 中可以看到,EMU VIDEO 已经可以支持 4 秒的视频生成。在论文中,他们还探讨了增加视频时长的方法
作者表示,通过一个小的架构修改,他们可以在 T 帧上约束模型并扩展视频。因此,他们训练 EMU VIDEO 的一个变体,以「过去」16 帧为条件生成未来 16 帧。在扩展视频时,他们使用与原始视频不同的未来文本提示,效果如图 7 所示。他们发现,扩展视频既遵循原始视频,也遵循未来文本提示。

第三部分 PixelDance
11月18日,字节就半路杀出发布PixelDance
- 生成有高度一致性且有丰富动态性的视频,让视频内容真正地动起来,是目前视频生成领域中的最大挑战
- 在这方面,最新的研究成果 PixelDance 迈出了关键性的一步,其生成结果的动态性显著优于目前现有的其它模型,引起了业界的关注
3.1 PixelDance的两种视频生成模式
在官网(https://makepixelsdance.github.io)中,PixelDance 给出了两种不同的视频生成模式。
- 第一种是基础模式(Basic Mode),用户只需要提供一张指导图片+文本描述,PixelDance 就可以生成有高度一致性且有丰富动态性的视频,其中指导图片可以是真实图片,也可以利用现有的文生图模型生成。
从展示的结果来看,真实风格、动画风格、二次元风格、魔幻风格,PixelDance 通通都可以解决,人物动作、脸部表情、相机视角控制、特效动作,Pixeldance 也都可以很好的完成
- 第二种是高级魔法模式(Magic Mode),给了用户更多发挥想象力和创造力的空间。在这种模式下,用户需要提供两张指导图片+文本描述,可以更好地生成更有难度的各种炫酷特效镜头

除此之外,官网还展示了完全使用 PixelDance 制作的 3 分钟故事短片
- 使用 PixelDance 能按照用户预想的一个故事,制作每一个场景和对应的动作。不管是真实场景(如埃及、长城等),还是虚幻场景(如外星球),PixelDance 都能生成细节丰富、动作丰富的视频,甚至各种特效镜头也不在话下
- 并且,主人公北极熊先生的黑色礼帽和红色领结形象,在不同的场景中都得到了很好的保持。长视频生成再也不是简单的拼凑弱相关的短视频片段了
而达到这样拔群的视频生成效果,并没有依赖复杂的数据集和大规模的模型训练,PixelDance 在公开的 WebVid-10M 数据集上仅用 1.5B 大小的模型就达到了上述效果。
3.2 论文解读:Make Pixels Dance: High-Dynamic Video Generation
在相应的论文《Make Pixels Dance: High-Dynamic Video Generation》中(论文地址:https://arxiv.org/abs/2311.10982,demo 地址:https://makepixelsdance.github.io),作者指出了视频生成难以做出好效果的原因:相比于图片生成,视频生成具有特征空间显著更大、动作多样性显著更强的特点。这就导致了现有的视频生成方法难以学到有效的时域动作信息,生成的视频虽然图片质量较高,但动态性非常有限。
如国内媒体机器之心所说,针对上述问题,PixelDance 提出了基于文本指导 + 首尾帧图片指导的视频生成方法,使得模型更充分地关注和学习视频的动态信息。
其中,首帧图片指导为整个视频内容提供了框架和素材。此外,通过将上一个视频片段的尾帧拿来作为下一个视频片段的首帧指导,可以生成更长的视频。文本描述提供了对视频动作的描述。尾帧图片指导为视频生成过程提供了结束状态的信息。作者提出了适配的方法,使得模型能接收比较粗糙的图片作为指导,这使得用户可以使用基本的图片编辑工具获得尾帧图片指导。
官网的信息显示,目前还在积极地迭代模型效果中,未来 2-3 个月内就会放出人人可以试用的模型。目前,作者也提供了途径支持大家发送想要测试的样例,目前官网中已经放出了一些用户的测试样例:

如此看来,有了 PixelDance,只要有天马行空的想象力,人人都可以成为「百万特效大师」
// 待更
第四部分 Stable Video Diffusion (SVD)
4.1 Stability AI发布生成式视频模型Stable Video Diffusion(SVD)
11月21日,开发并维护stable diffusion后续版本的Stability AI终于发布了他们自家的生成式视频模型Stable Video Diffusion(SVD),支持文本到视频、图像到视频生成


SVD基于Stable Diffusion 2.1,用约6亿个样本的视频数据集预训练了基础模型
4.2 论文解读:Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
SVD对应的论文为:《Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets》

// 待更
参考文献
- 视频生成新突破:PixelDance,轻松呈现复杂动作与炫酷特效
- 一句话拍大片,导演末日来了?Runway发布文字生成视频模型Gen-2,科幻日系二次元统统拿捏
- 2023年11月 runway Gen2的更新
Gen-2颠覆AI生成视频!一句话秒出4K高清大片,网友:彻底改变游戏规则
文本生视频工具又迎来重大更新,Runway Gen-2 到底有多强? - Meta版ChatGPT来了:Llama 2加持,接入必应搜索,小扎现场演示,介绍了文生图模型Emu
- Meta生成式AI连放大招:视频生成超越Gen-2,动图表情包随心定制
- 斯坦福美女博士创业项目爆火!AI视频生成出道即顶流,半年融资5500万美元
- ..
创作、修改、晚上记录
- 11.28日,一字一句读runway的Gen1论文,完善本文的第一部分
算新增一个新的研究方向:文生视频
我(们)将围绕文生视频,逐一发布一系列解读博客、公开课、课程、商用项目/解决方案等 - 11.29日,开始读Meta发布的Emu Edit论文、EMU VIDEO论文,完善本文的第三部分
- ..
原文地址:https://blog.csdn.net/v_JULY_v/article/details/134655535
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_11721.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!