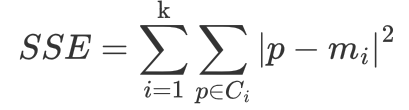本文介绍: 这段代码在每一次主循环中执行 K-Means 算法的一次迭代,同时绘制数据点、聚类中心以及数据点与聚类中心之间的关系。显示数据点与聚类中心之间的连线: 使用 pygame.draw.line 显示每个数据点与其所属簇的聚类中心之间的连线。绘制数据点和聚类中心: 使用 pygame.draw.circle 绘制数据点和聚类中心。计算每个数据点的分配: 计算每个数据点到各个聚类中心的距离,将其分配到距离最近的聚类中心。更新聚类中心: 根据每个簇的数据点,更新聚类中心为该簇内数据点的平均位置。
使用 Pygame 模块演示了 K-Means 聚类算法的基本原理。让我逐步解释它的实现:
初始化和基本设置
Pygame 初始化: 通过 pygame.init() 初始化 Pygame。
定义颜色和屏幕大小: 定义了一些颜色常量(WHITE, BLACK, RED, GREEN, BLUE)和屏幕的宽度和高度。
创建 Pygame 窗口: 使用 pygame.display.set_mode 创建窗口,设置窗口标题。
生成随机数据点和初始聚类中心
生成随机数据点: 使用 random.randint 在屏幕范围内生成随机数据点,存储在 points 列表中。
生成初始聚类中心: 使用 random.randint 生成初始的聚类中心,存储在 clusters 列表中。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。