本文介绍: 编者按:2023年是微软亚洲研究院建院25周年。借此机会,我们特别策划了“智启未来”系列文章,邀请到微软亚洲研究院不同研究领域的领军人物,以署名文章的形式分享他们对人工智能、计算机及其交叉学科领域的观点洞察及前沿展望。希望此举能为关注相关研究的同仁提供有价值的启发,激发新的智慧与灵感,推动行业发展。
编者按:2023年是微软亚洲研究院建院25周年。借此机会,我们特别策划了“智启未来”系列文章,邀请到微软亚洲研究院不同研究领域的领军人物,以署名文章的形式分享他们对人工智能、计算机及其交叉学科领域的观点洞察及前沿展望。希望此举能为关注相关研究的同仁提供有价值的启发,激发新的智慧与灵感,推动行业发展。

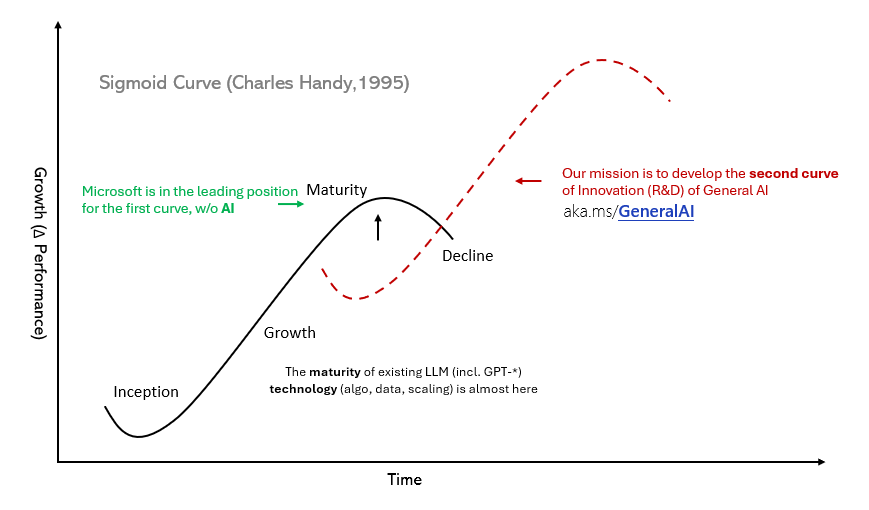
“Transformer 网络架构、‘语言’模型(Next-Token Prediction,或自回归模型)学习范式,规模法则(Scaling Law),以及海量的数据和计算资源,共同构成了当前人工智能基础大模型范式迁移的核心技术要素,也将人工智能的基础创新推向了第一增长曲线的顶峰。在探索人工智能基础创新的第二增长曲线时,我们希望直击人工智能第一性原理,通过革新基础网络架构和学习范式,构建能够实现效率与性能十倍、百倍提升,且具备更强涌现能力的人工智能基础模型,为人工智能的未来发展奠定基础。”
从人工智能的发展历程来看,GPT 系列模型(例如 ChatGPT 和 GPT-4)的问世无疑是一个重要的里程碑。由它所驱动的人工智能应用已经展现出高度的通用性和可用性,并且能够覆盖多个场景和行业——这在人工智能的历史上前所未有。
然而,人工智能的科研工作者们不会满足于此。从某种意义上来说,大模型只是人工智能漫长研究道路上一个精彩的“开局”。但当我们满怀雄心壮志迈向下一个里程碑时,却发现仅仅依赖现有的技术和模型已经难以应对新的挑战,我们需要新的突破和创新。
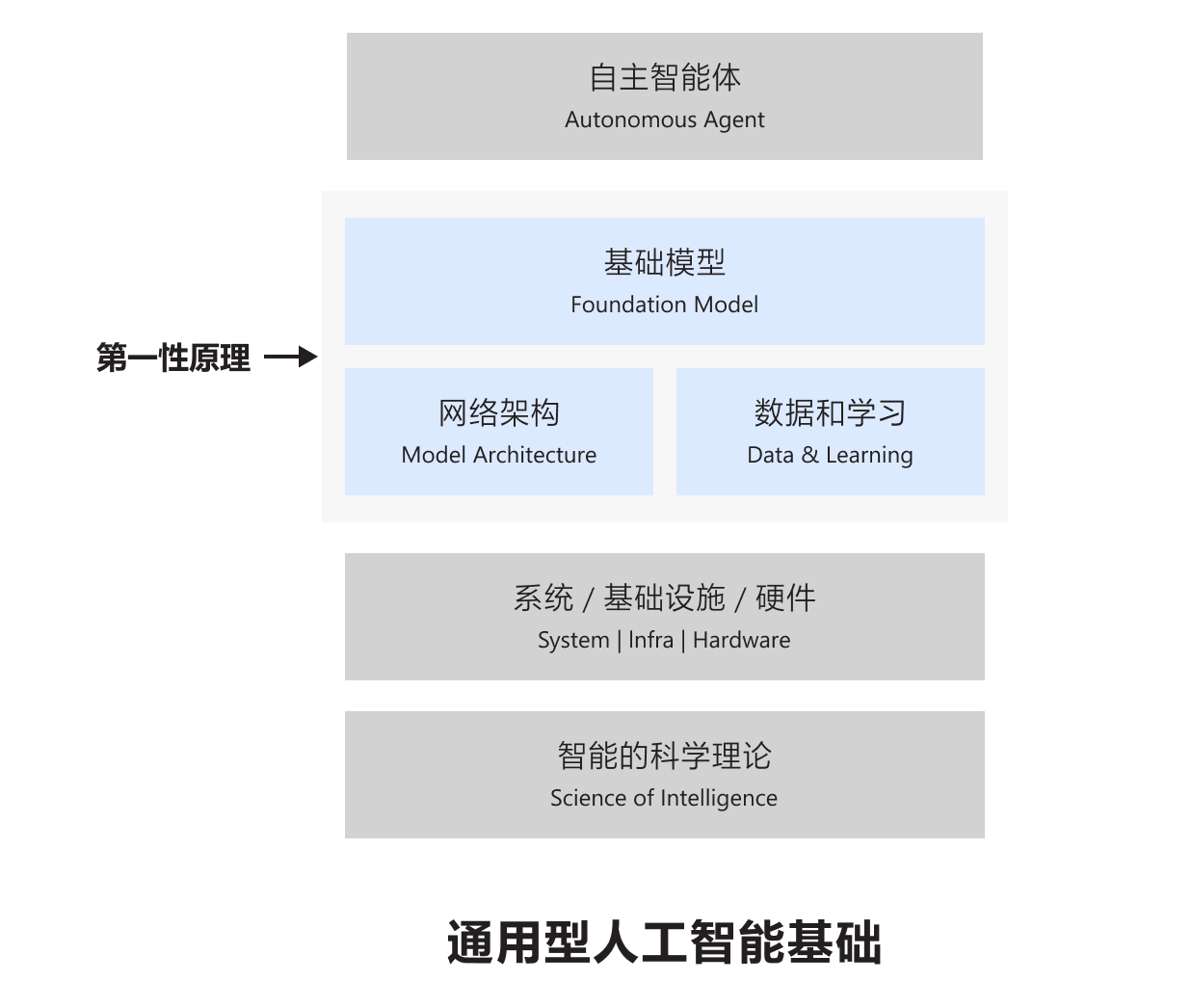
基础模型是人工智能的第一性原理
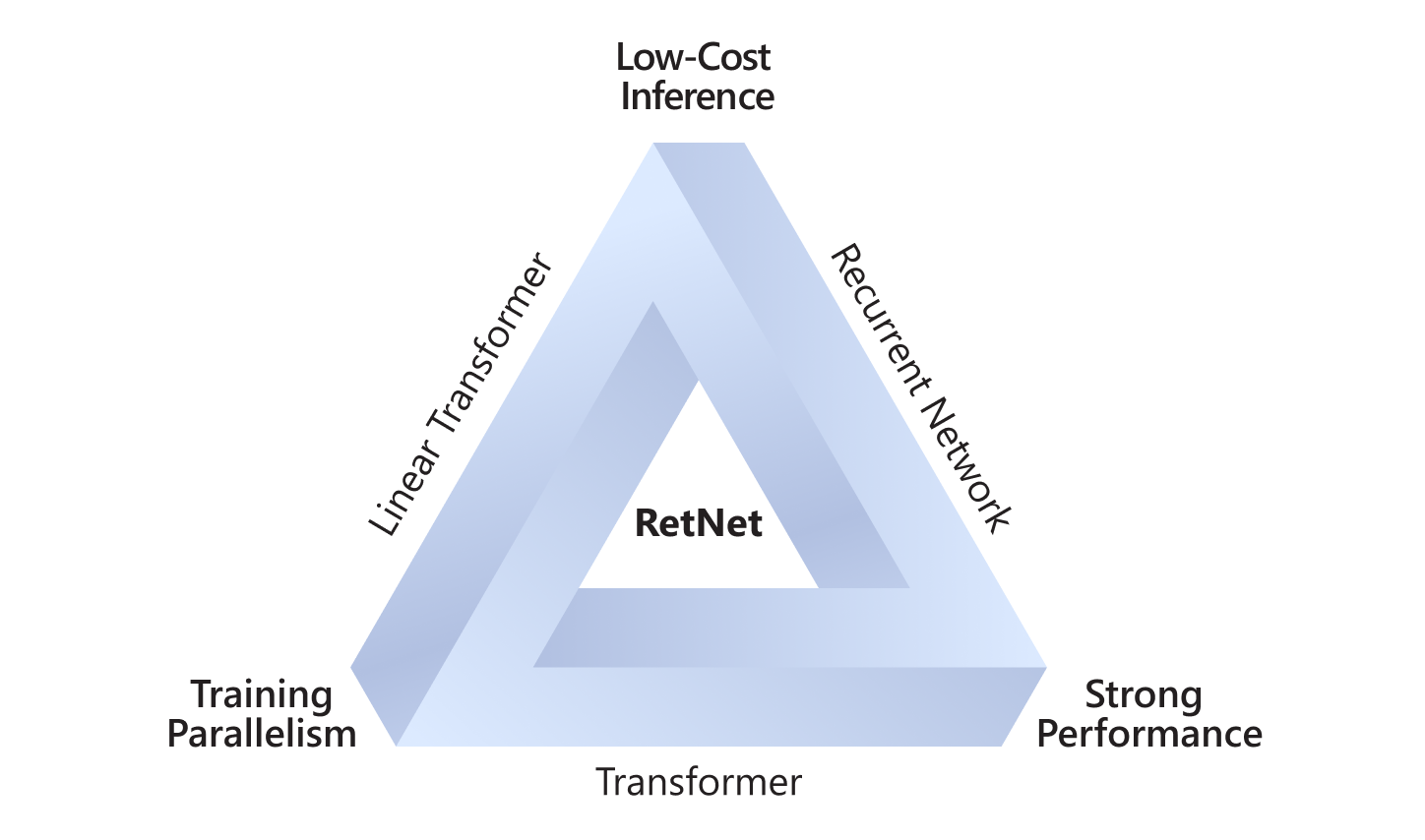
推理效率是新一代基础模型网络架构革新的关键驱动力
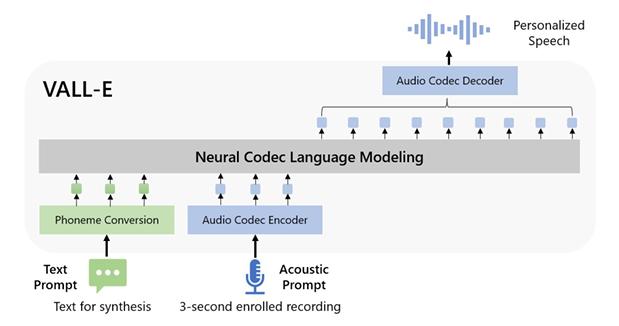
推动多模态大语言模型演进,迈向多模态原生


专注颠覆式创新,持续推进通用型人工智能基础研究第二增长曲线
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。





