背景
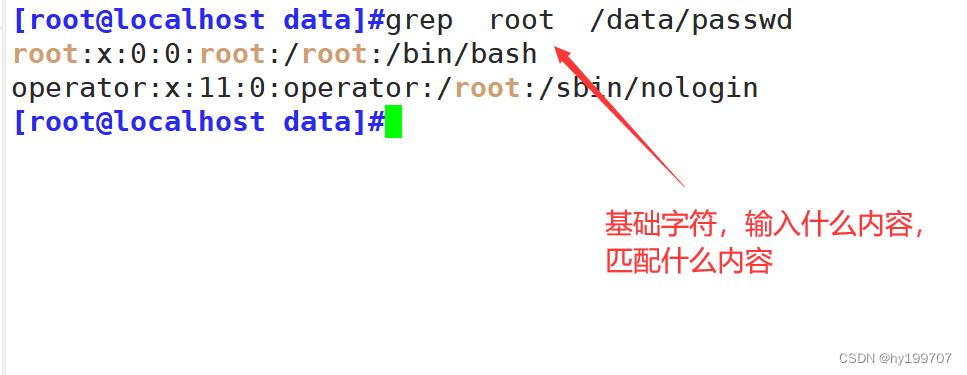
爬取某天气网站数据,使用 Selenium 能够得到渲染数据后的页面源代码。特定日期的真实数据肯定只有1份,展示在页面表格中,但是源代码中提供了3个都有数据的 Table,而其中2个Table 的数据是通过 math.random 生成后填充,然后通过 css 样式设置了隐藏。
为了拿到真实数据,要么直接提取包含真实数据的 Table,要么剔除2个伪数据 Table,然后才能进一步提取 tr 以及 td 标签内的文本。鉴于使用了Scrapy框架,函数之间传递的是 HtmlResponse, 所以我们采用剔除2个伪数据 Table的方式,保留网页源代码其余部分,而没有提取真实数据再封装或者改用String 传递。
不管哪种方式,关键是要找出真数据 Table 和 伪数据 Table 之间的差异。
经过反复对比,我们发现用伪造数据填充的2个 Table, 都有在 class 中设置了 position : absolute 属性,所以可以用正则表达式来匹配出全部Table,然后直接将这2个 Table,替换为空。
实现
2步走方案
其实最开始是打算一步到位的,但是实在搞不定1步到位的正则表达式,所以决定还是先用笨办法,拿到结果再看怎么优化。所以用了2步,
1步到位方案
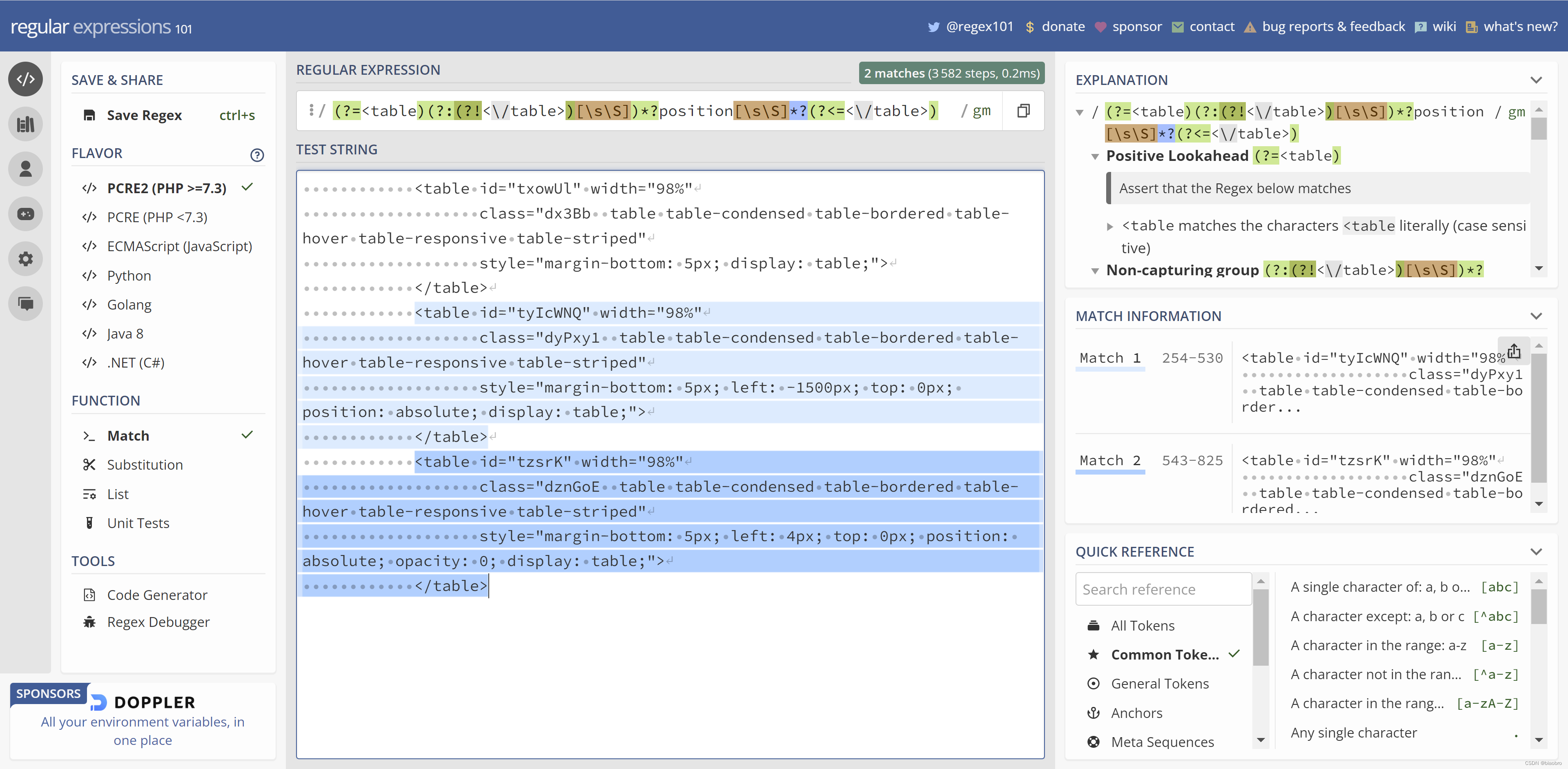


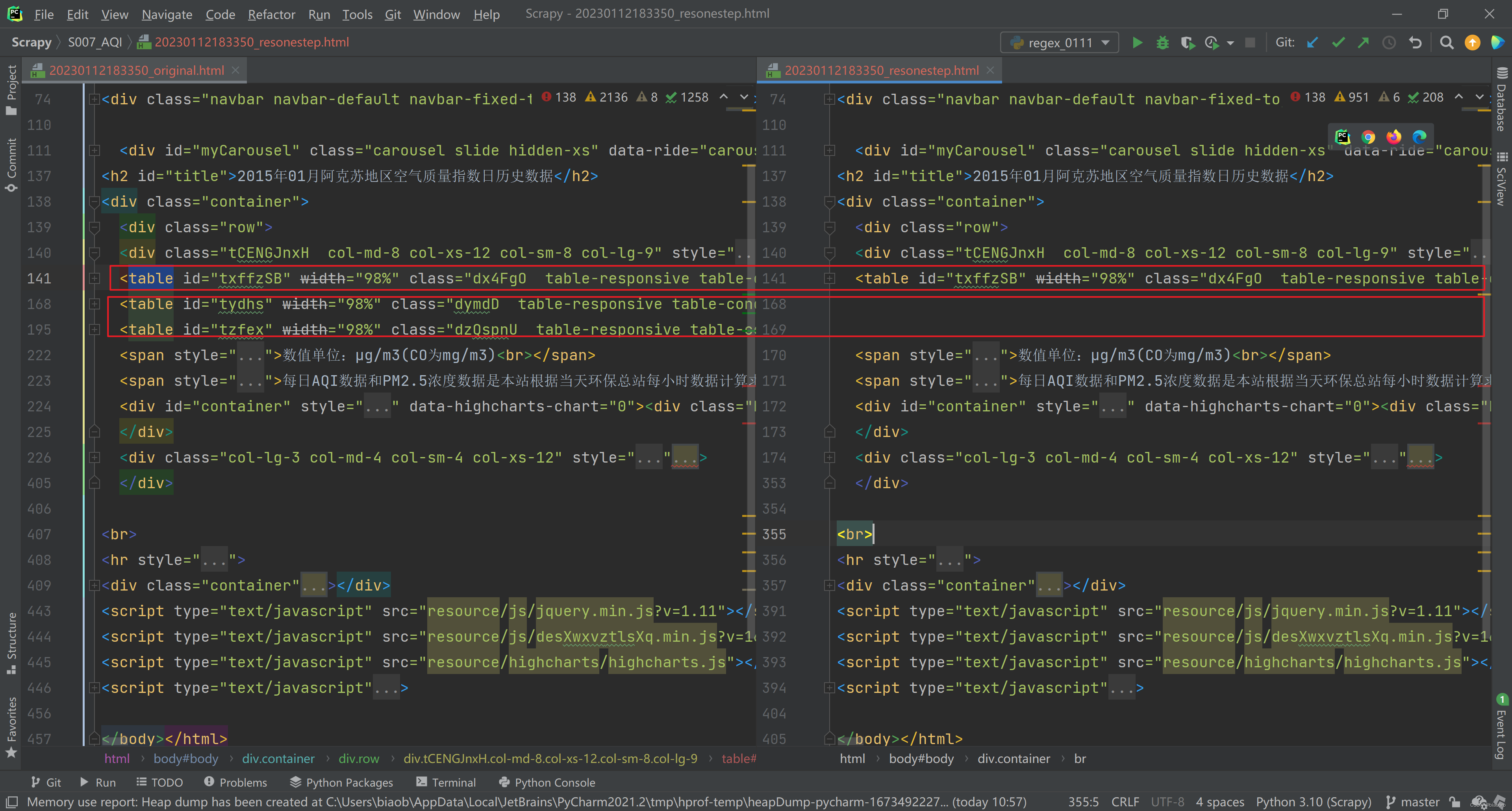
方案对比
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。