




从 简单汇编基础 到 Swift 不简单的 a + 1
作为iOS开发,程序崩溃犹如家常便饭,秉着没有崩溃也要制造崩溃的原则
每天都吃的很饱
但学艺不精的经常有这样的困扰,每次崩溃都定位到一堆。类似
movq $0x0, 0xc7a(%rip) 的天书里面
初识汇编
虽然不知道movq是什么意思,但知道move
move 的意思,没错是 飘逸
至于q,不管 q不q 的,哎e呢?
汇编语言
汇编语言:(assembly language) 是一种用于 电子计算机、微处理器、微控制器,或其他可编程器件的低级语言 – 维基百科
简单来说,平时写的代码都是高级语言,计算机不理解高级语言,就像吃饭不吃塑料包装一样,吃的是里面的东西
汇编语言是二进制指令的 文本形式,计算机会把代码转换为汇编语言,汇编语言通过机器指令 还原成 二进制代码,也就是所谓的 0,1,计算机就可以执行了。
每一个 CPU的机器指令不同,所以对应的汇编语言也不同。
寄存器
为什么需要了解寄存器?
因为汇编语言 的数据存储 与寄存器和内存 息息相关
一般来说,数据是放在内存中的,CPU 计算的时候就去内存里拿数据,但是
CPU 的运算速度 > 内存的运算速度
就仿佛
吃饭的速度 > 食堂大妈打菜的速度
受不了,大妈受得了吗?
所以CPU 自带了一级,二级缓存,相当于大妈让她儿子给送饭
问题是这个中间层还是慢且不稳定
CPU 缓存的数据地址是 不固定的,意味着点了份 西红柿盖浇饭,让店员给送到座位上,店员找了半个小时,发现坐在别人店里。
所以CPU 有了寄存器,来存储频繁使用的数据。CPU 通过寄存器 跟 内存 间接交换数据
寄存器都有自己的名称(如 rax ,rdx等)
说坐在C区21号,店员还不是分分钟把饭塞到嘴里,质问:喂,还要饭吗?
所以CPU 会去 指定名称的 寄存器拿数据,这样速度就不快了嘛
天下武功,唯快不破。
所以为什么需要寄存器,因为读写速度够快
内存
说到底,寄存器依旧是一个暂存区,只是一个中间站,真正存储数据,操作数据的还是内存。
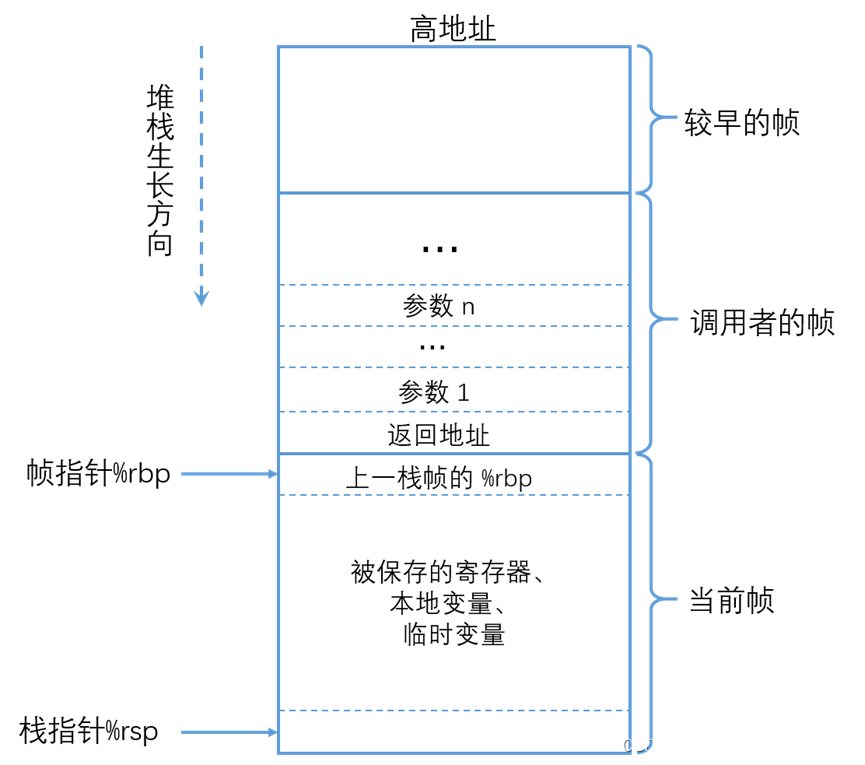
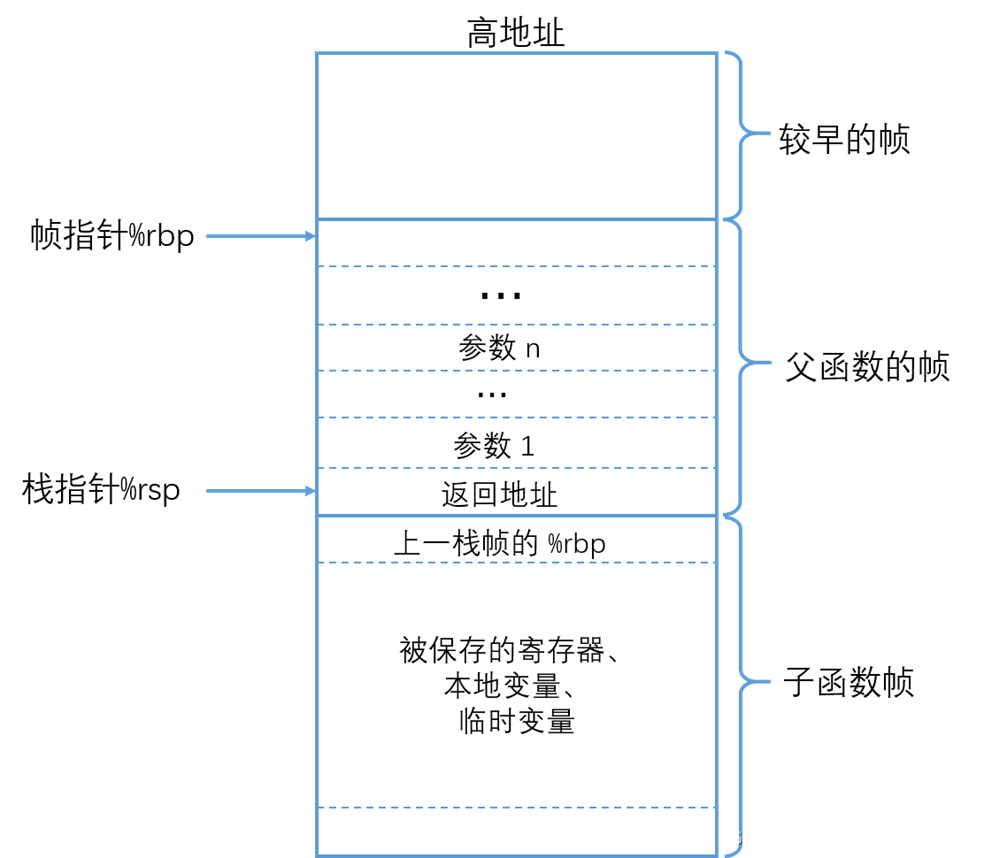
以下是内存分布图:

简单介绍一下堆栈
• 堆 heap
o 分配方式:alloc,速度相对栈比较慢,容易产生内存碎片
o 管理方式: 程序员,ARC下面,堆区的分配和释放基本也是系统操作
o 地址分布:从低到高,非连续
o 大小:取决于计算机系统的有效的虚拟空间
o 作用:动态分配内存,存储变量,延长生命周期
• 栈 stack
o 一端进行插入和删除操作的特殊线性表
o 分配方式: 系统,速度比较快
o 管理方式: 系统,不受程序员控制
o 地址分布:从高到低,连续
o 大小:栈顶的地址和容量是系统决定
o 生命周期:出了作用域就会释放
o 入栈出栈:先进后出,类似羽毛球筒,先放入的羽毛球,总是最后才能拿到
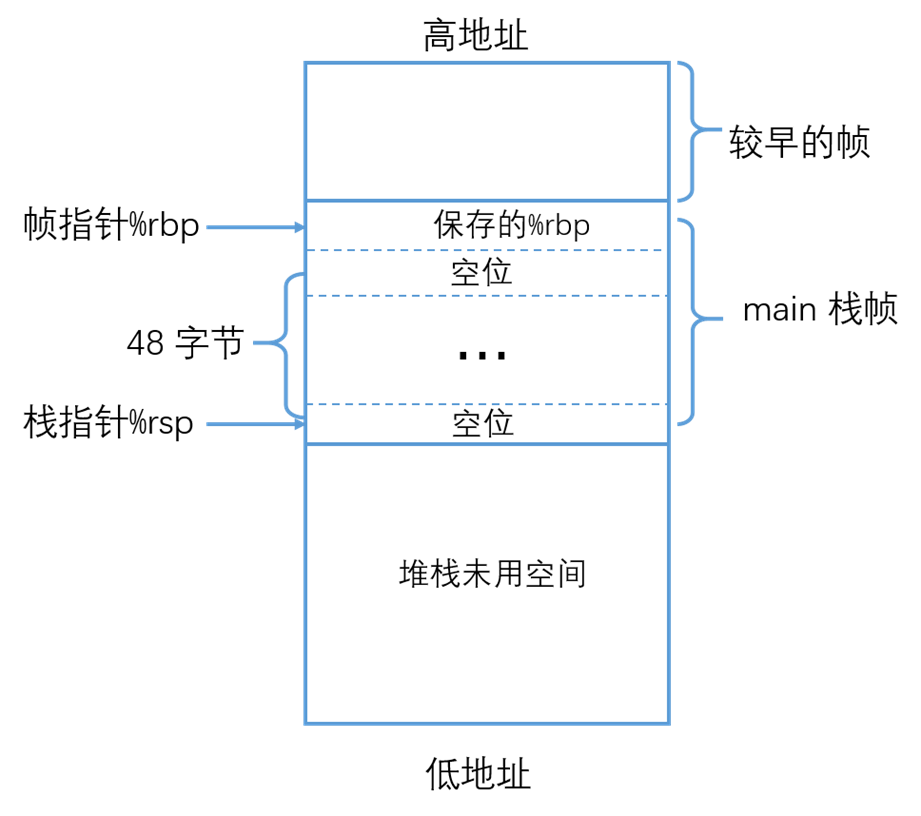
在Linux 下,iterm2 敲下ulimit -a,可以看到栈分配的默认大小为 8192 ,也就是 8M
–t: cpu time (seconds) unlimited
-f: file size (blocks) unlimited
–d: data seg size (kbytes) unlimited
–s: stack size (kbytes) 8192
复制代码
汇编语言
因为是iOS开发,所以就只稍微了解了 AT&T 汇编 的皮毛
虽然看起来会枯燥一点,但是理解这些比较常用的寄存器,对汇编代码的理解就会有质的飞跃
之前是门外汉
现在好歹算个半个汇编人
iOS 模拟器、MAC OS、Linux : AT&T汇编 ;
iOS 真机: ARM 汇编
复制代码
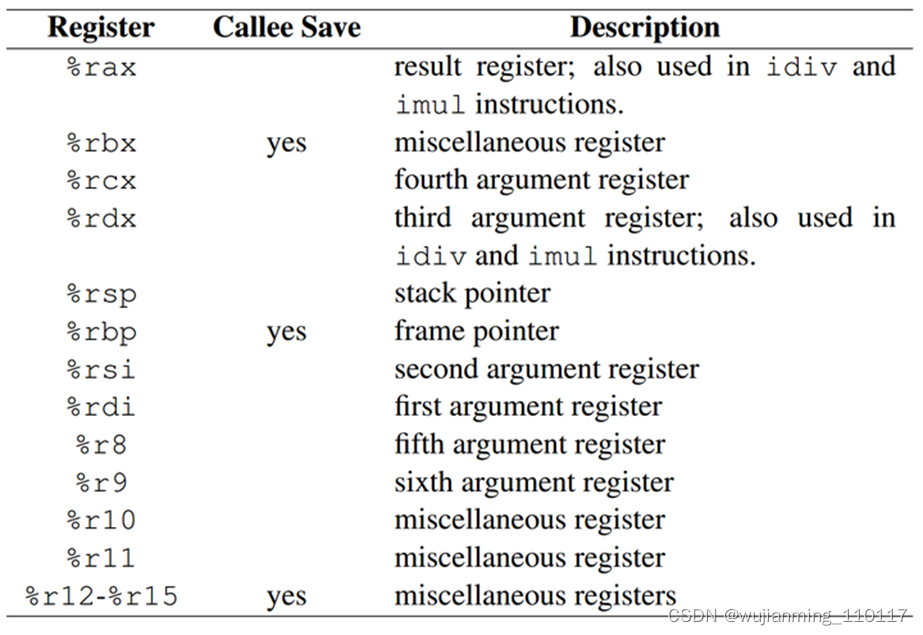
x86-64 中,AT&T 中常用的 寄存器有 16种:
• %rax、%rbx、%rcx、%rdx、%rsi、%rdi、%rbp、%rsp
• %r8、%r9、%r10、%r11、%r12、%r13、%r14、%r15
常用寄存器
AT&T 常用寄存器介绍:
%rax:常作为函数返回值。 一般来说,为了向后兼容,64位的寄存器会兼容32的寄存器,32和64可以一起使用
64位: 8个字节 ,以 r 开头; 32位: 4个字节,以e 开头,看图

在64位的寄存器 rax中,为了兼容分配了较低的32位,也就是4个字节 给了 eax。基本上,汇编出现的eax 就是 代表rax,eax是 rax 的一部分,其他 部分寄存器同理
%rdi、%rsi、%rdx、%rcx、%r8、%r9: 常作为函数参数
r8,r9 这种32位的表示法,通常在后面加d,如r8d,r9d
%rip: 指令指针,存储CPU 即将执行的指令地址
• 解释一下rip
即将执行: 下一条执行
指令地址: 开头的那一串 0x100…