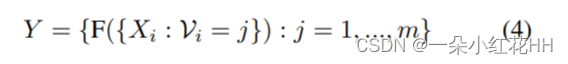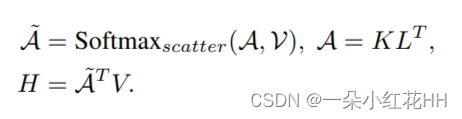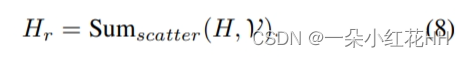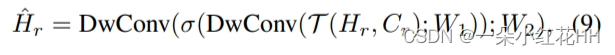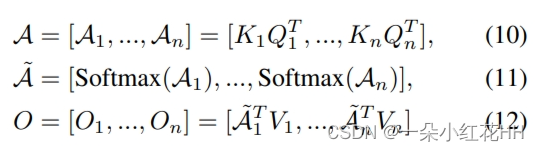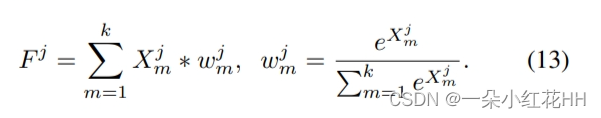VoxSet
Voxel Set Transformer: A Set-to-Set Approach to 3D Object Detection from Point Clouds
论文网址:VoxSet
论文代码:VoxSet
简读论文
这篇论文提出了一个称为Voxel Set Transformer(VoxSeT)的3D目标检测模型,主要有以下几个亮点:
总的来说,这篇论文通过集合自注意力的方式,将点云处理建模为一个集合到集合的转换问题,提供了一个新的基于transformer的检测器框架,值得学习和参考。
摘要
Transformer 在许多 2D 视觉任务中表现出了良好的性能。然而,由于点云是一个长序列并且在3D空间中分布不均匀,因此在大规模点云数据上计算自注意力是很麻烦的。为了解决这个问题,现有的方法通常通过将点分组为相同大小的簇来本地计算自注意力,或者对离散表示执行卷积自注意力。然而,前者会导致随机点丢失,而后者通常具有狭窄的注意力范围。在本文中,我们提出了一种新颖的基于体素的架构,即Voxel Set Transformer(VoxSeT),通过集合到集合的转换来检测点云中的 3D 对象。 VoxSeT 建立在基于体素的集合注意力(VSA)模块之上,该模块通过两个交叉注意力减少每个体素中的自注意力,并对一组潜在代码引起的隐藏空间中的特征进行建模。借助VSA模块,VoxSeT可以管理大范围内任意大小的体素化点簇,并以线性复杂度并行处理它们。所提出的 VoxSeT 将 Transformer 的高性能与基于体素的模型的效率相结合,可以作为卷积和基于点的主干网的良好替代方案。
引言
3D 点云的对象检测已受到广泛关注,因为它为自动驾驶、机器人和虚拟现实等许多应用提供了支持。与 2D 图像不同,3D 点云在连续空间中自然稀疏且分布不均匀,阻碍了 CNN 层的直接应用。为了解决这个问题,一些方法首先将点云转换为离散表示,然后应用CNN模型来提取高维特征。另一类方法对连续空间中的点云进行建模,其中通过交错分组和聚合步骤提取多尺度特征。
除了上述两种方案之外,基于Transformer的模型最近在处理点云数据方面引起了极大的兴趣,因为Transformer中使用的自注意力对于输入组件的排列和基数是不变的,这使得 Transformer 成为点云处理的合适选择。然而,Transformer 模型的主要局限性在于自注意力计算是二次的。每个token都必须使用前一层中的所有其他令牌进行更新,这使得自注意力对于长序列点云来说变得棘手。 Point Transformer 在 PointNet 架构上构建Transformer,该架构将点云数据分层分组到不同的集群中,并计算每个集群中的自注意力。 CT3D 提出了一个两阶段点云检测器,其中提取 3D RoIs 以对第一阶段中的原始点进行分组,并将Transformer应用于第二阶段中的分组点。

然而,由于点云的分布极其不均匀,每个簇中的点数量差异很大。为了使自注意力能够并行运行,当前的方法通过随机丢弃点或填充虚拟点来平衡每个集群中的token数量(见图1(a))。这导致检测结果不稳定和冗余计算。此外,每次将n个点分组到m个簇的操作都会花费O(nm)的复杂度,这是相对密集的。或者,Voxel Transformer 在离散体素网格上执行自注意力,如图 1(b) 所示。它以卷积方式计算自注意力,因此与具有 O(n) 复杂度的稀疏卷积一样高效。然而,由于卷积注意力是逐点操作,为了节省内存,卷积核的注意力域通常很小,从而阻碍了体素Transformer对长程依赖性进行建模。值得一提的是,尽管 Group-free 和 3DETR 通过在一组减少的种子点上计算自注意力,提出了一种很有前途的解决方案,但该解决方案仅适用于点云相对密集的室内场景并集中。考虑到室外场景的点云通常稀疏、大规模(例如> 20k)且分布不均匀,种子点的规模和覆盖范围仍然是一个问题。
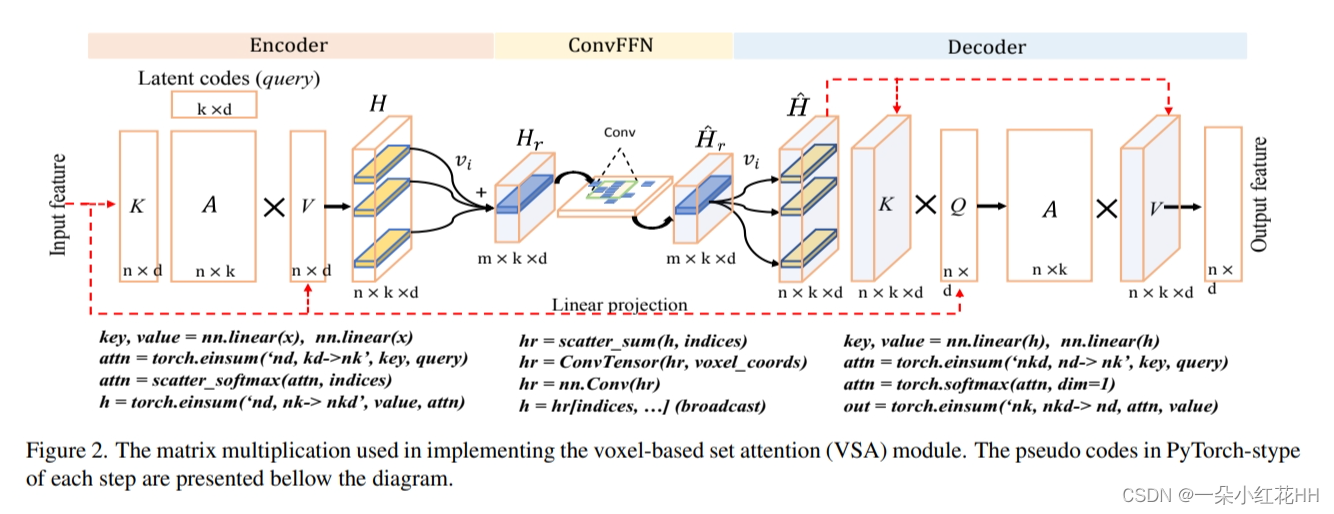
为了解决上述问题,本文引入了基于体素的集合注意力(VSA)模块。对于每个 VSA,将整个场景划分为不重叠的 3D 体素,并即时高效地计算输入点的体素索引。使用这些体素来确定注意力区域,类似于 SwinTransformer 中的窗口注意力。与图像不同,LiDAR具有不规则的结构,并且产生的注意力组具有不同的长度,这阻碍了模型的并行化。
受induced set Transformer的启发,本文为每个体素分配一组可训练的“潜在代码”。这些潜在代码为点云构建了一个固定长度的瓶颈,通过该瓶颈,来自体素内输入点的信息可以被压缩到静态隐藏空间。该公式基于以下关键观察:自注意力矩阵通常是低秩的,因此可以将密集的完全自注意力分解为两个连续的交叉注意力模块。如图 1© 所示,VSA 首先通过关注输入点的投影特征(即键和值)将用作查询的潜在代码转换为隐藏空间。变换后的隐藏特征对每个体素中输入点的上下文信息进行编码,并通过卷积前馈网络进行丰富,其中跨体素的特征在空间域中交换其信息。之后,隐藏特征与输入仔细融合,产生输入分辨率的输出特征。通过利用潜在代码,可以对所有体素中执行的交叉注意力进行向量化,使 VSA 成为高度并行的模块。给定 n 维输入特征和 k 个潜在代码,VSA 的复杂度为 O(nkd),并且可以用一般的矩阵乘法来实现。
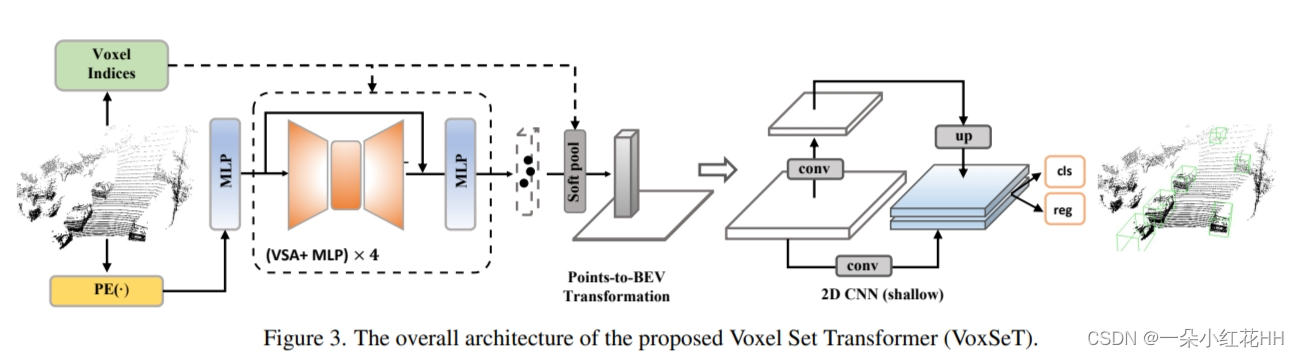
通过 VSA,本文提出了一种voxel set Transformer (VoxSeT),通过在集合到集合的转换过程中学习点云特征来检测 3D 对象。 VoxSeT 由 VSA 模块、MLP 层和用于鸟瞰 (BEV) 特征提取的浅层 CNN 组成。为了验证所提出模型的有效性,本文在两个 3D 检测基准 KITTI 和 Waymo 开放数据集上进行了实验。 VoxSeT 实现了与当前最先进技术竞争的性能。此外,所提出的 VSA 模块可以无缝地采用基于点的检测器,例如 PointRCNN ,并展示了相对于集合抽象模块的优势。
总之,本文首先发明了一种基于体素的集合注意力模块,它可以对任意大小的令牌簇的远程依赖性进行建模,绕过当前基于分组和基于卷积的注意力模块的限制。然后,提出了一个voxel set transformer,通过利用transformer在大规模序列数据上的优势来有效地学习点云特征。本文的工作为 3D 点云数据处理的当前卷积和基于点的主干提供了一种新颖的替代方案。
相关工作
基于点云的3D目标检测
早期的点云 3D 对象检测方法可以分为两类。第一类方法将点云转换为更紧凑的表示,例如鸟瞰(BEV)图像、正面视图范围图像和体积特征。严等人开发了一种稀疏卷积主干,通过将点云编码为 3D 稀疏张量来有效地处理点云。朗等人通过将体素特征堆叠为“支柱”并使用2D CNN进行处理,进一步加快了检测率。另一类方法通过采用 PointNet架构来处理连续空间中的点云。通过交错分组和采样操作分阶段提取多尺度中的逐点特征。施等人和杨等人,建议从 PointNet 输出生成 3D RoIs,并将 RoIs 应用到逐点特征分组以进一步细化。齐等人提出了一种深度投票方法,对物体表面的点进行聚类,以检测点不足的物体。与紧凑表示不同,逐点特征保留了原始点云的更多细节和细粒度结构。基于这一事实,一些方法在点和体素空间中采用混合表示来实现更可靠的检测输出。
本文提出的架构很大程度上是由基于体素的方法推动的。本文将点云划分为体素网格并在本地执行自注意力,赋予模型归纳偏差和计算效率。