一、网页分析
进入到腾讯文档首页,按F12调出开发者工具,选择要爬取的在线文档。
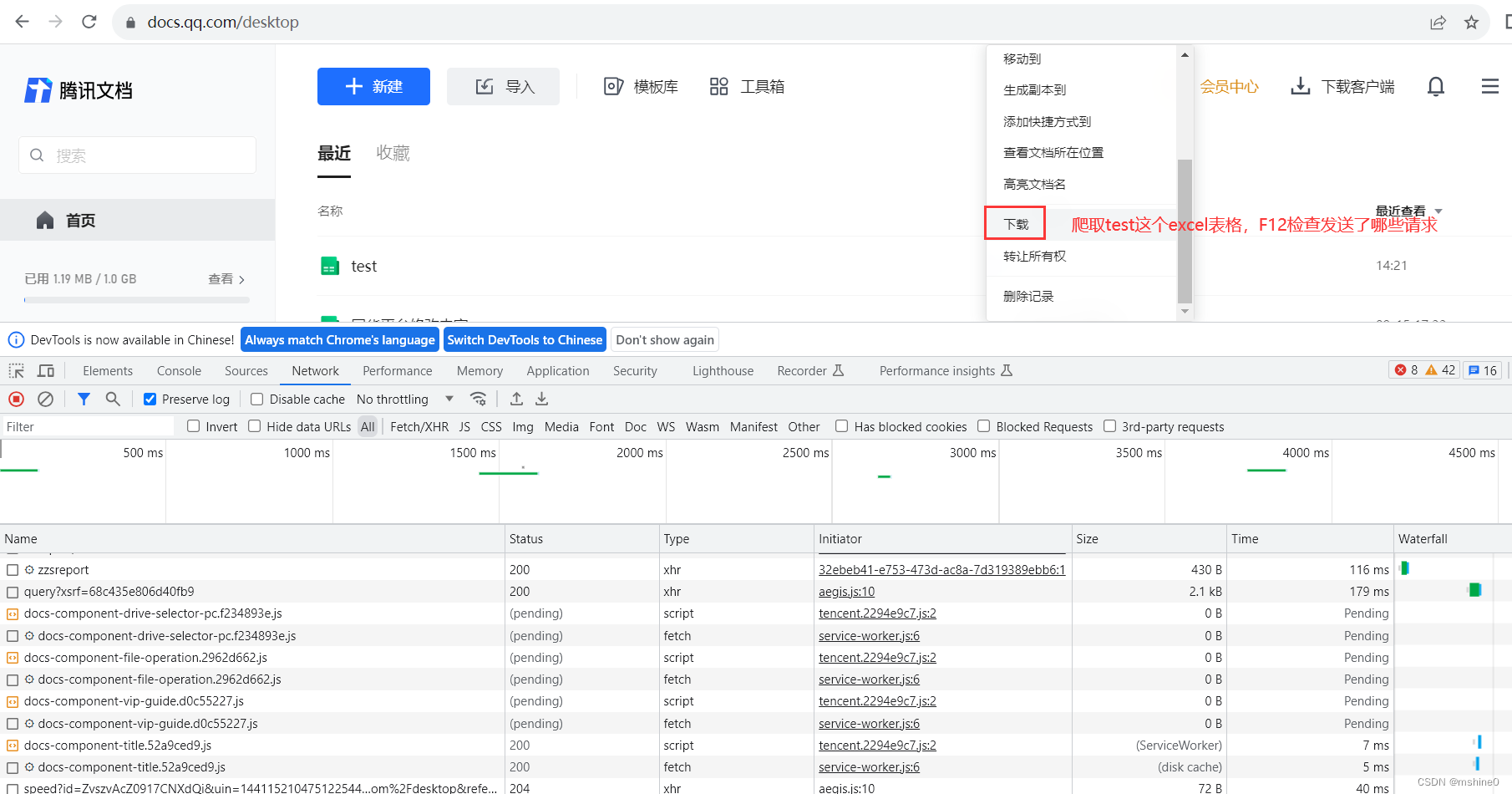
过滤掉一些静态文件加载的请求,我们只看ajax请求。

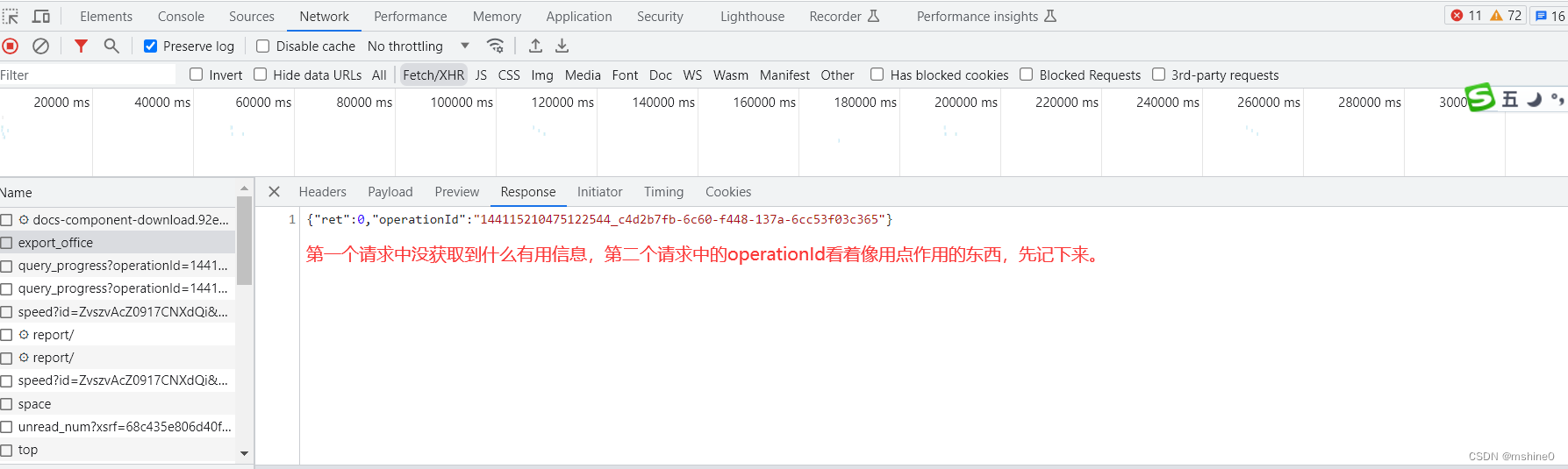

将file_url粘贴到浏览器地址栏中访问,发现直接将要爬取的url下载到了本地,所以这个file_url很有用。

这个file_url是我们通过对https://docs.qq.com/v1/export/query_progress?operationId=144115210475122544_c4d2b7fb-6c60-f448-137a-6cc53f03c365这个url发送get请求得到的。

在这个请求中有一个operationId,这个参数应该是动态的,有前面网页分析时,我们发现是第二个请求中获取的。
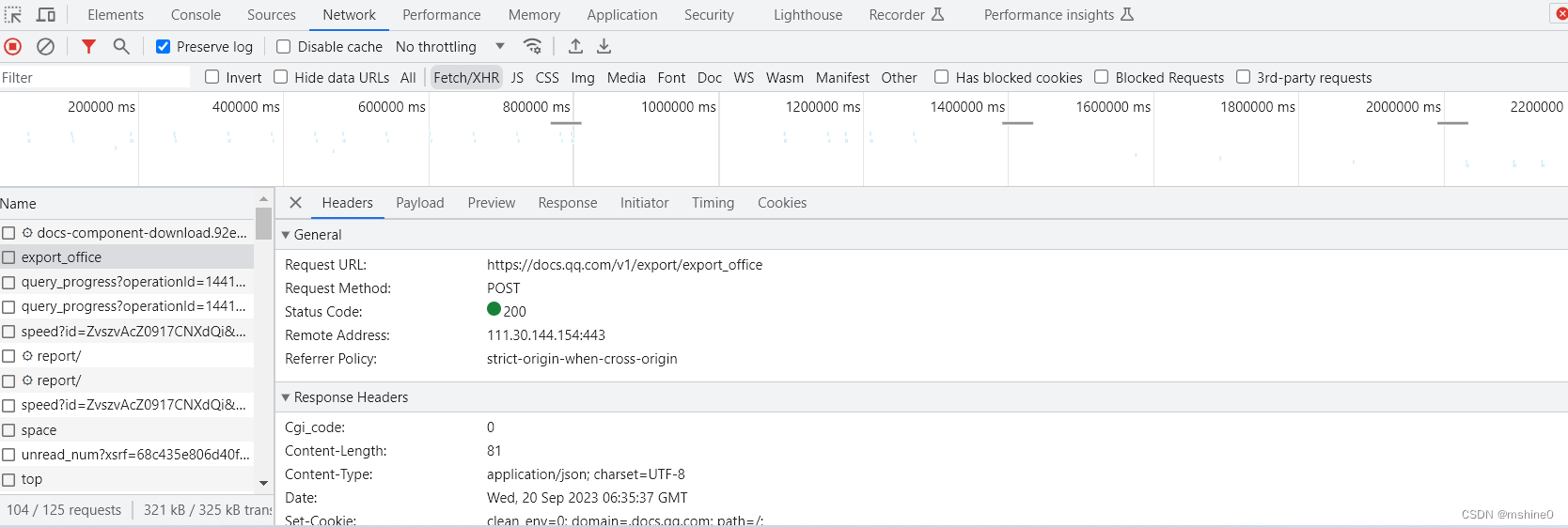
第二个请求是一个post请求,既然是Post请求,那它有携带哪些参数发请求呢?携带的参数是固定的?还是不固定的?
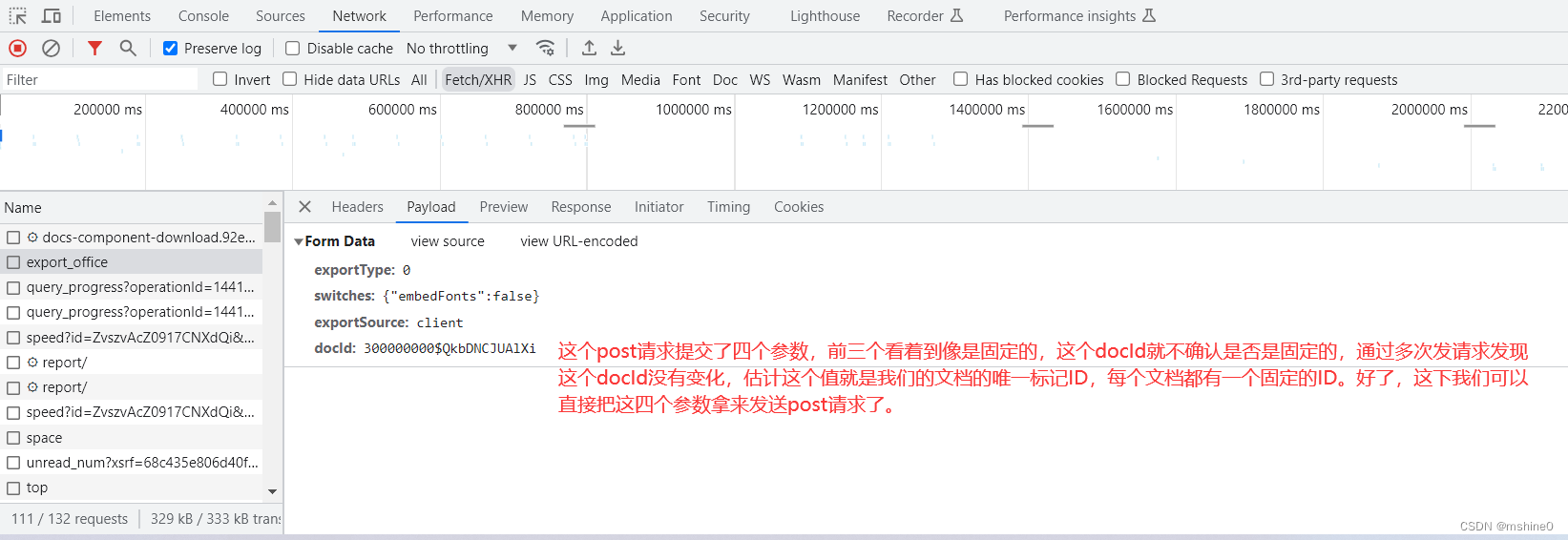
通过以上代码我们动态获取到了operationId,带着这个参数我们接下来去获取文档的下载地址file_url这个参数。前面有说过对https://docs.qq.com/v1/export/query_progress?operationId=144115210475122544_c4d2b7fb-6c60-f448-137a-6cc53f03c365这个url发送了两次get请求才获取到了包含有file_url这个参数的结果,在实际测试中我发现有时要发送第三次请求才能获得。多次实验最多需要三次获取,如果你三次还没获取到,可以自己写循环多获取几次试试。
二、数据存储
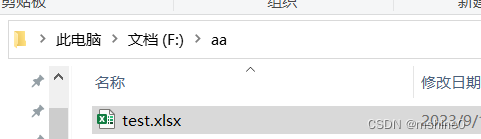
好了,现在拿到了文档下载地址file_url,我们可以把数据可视化放到excel中。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[软件工具]文档页数统计工具软件pdf统计页数word统计页数ppt统计页数图文打印店快速报价工具](https://img-blog.csdnimg.cn/direct/09dfbaff3e9a47a9a551dd65fef5d482.jpeg)


![[word] word中怎么插入另外一个word文档 #媒体#职场发展](https://img-blog.csdnimg.cn/img_convert/36ffef6b3060628ccf540a56f6069cb0.png)

