1.单词统计流程(文字简单描述)

2.MR底层计算原理[重点]
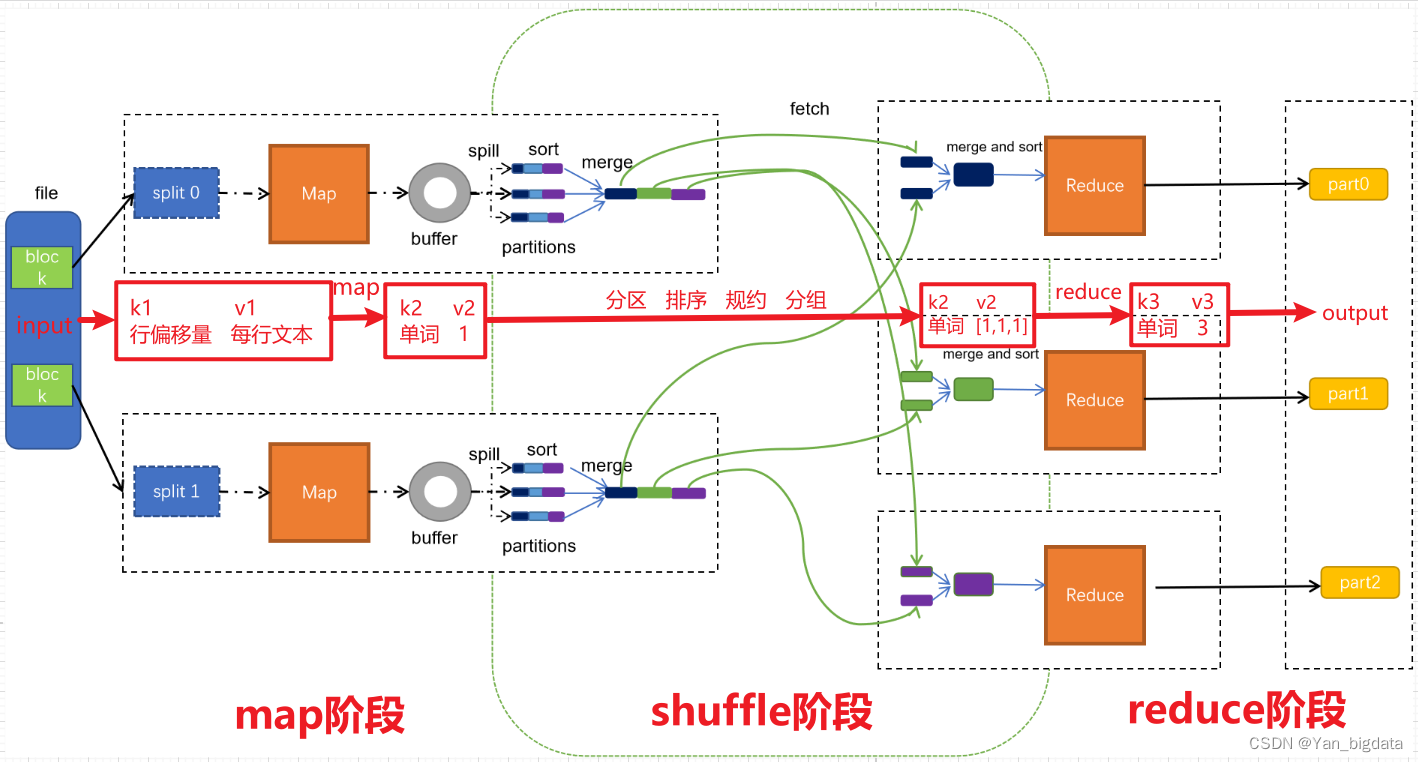
MAP阶段
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下Split size 等于 Block size。每一个切片由一个MapTask处理(当然也可以通过参数单独修改split大小)
第二阶段是对切片中的数据按照一定的规则解析成对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个,调用一次map方法。每次调用map方法会输出零个或多个键值对
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>
SHUFFLE阶段
REDUCE阶段
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。