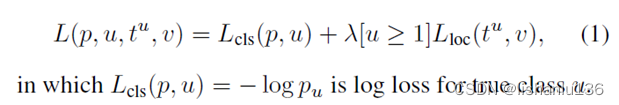1、算法概述
先说R-CNN的不足之处:
1、训练方式不是端到端的,必须先微调CNN网络,然后用CNN网络得到的特征训练SVMs,最后学习bounding–box回归器。
2、训练起来耗时且耗磁盘空间,用于训练SVMs和bounding–box的区域候选框的特征必须提取好后存储在磁盘中。
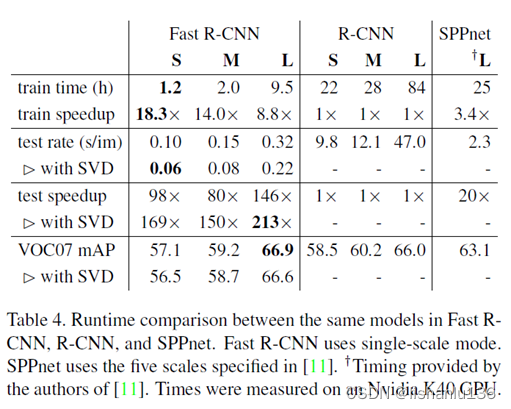
3、检测速度很慢,通过重复提取每个区域候选框的特征进行SVM分类加回归,用VGG16的backbone,即使在GPU上推理速度也要47s/image。
同年的SPPNet针对R-CNN也做了改进,除了将用于提取特征的CNN网络替换成ZF5,主要改进点就是用SPP(空间金字塔池化)层替换了网络最后一个池化层,这使得原本R-CNN的2000次CNN前向传播用于提取候选框区域特征得以仅通过一次就可以全部做完,这一改进大大减少了训练和推理时间。但它还是没有解决上面提到的R-CNN第1、第2两个不足点。
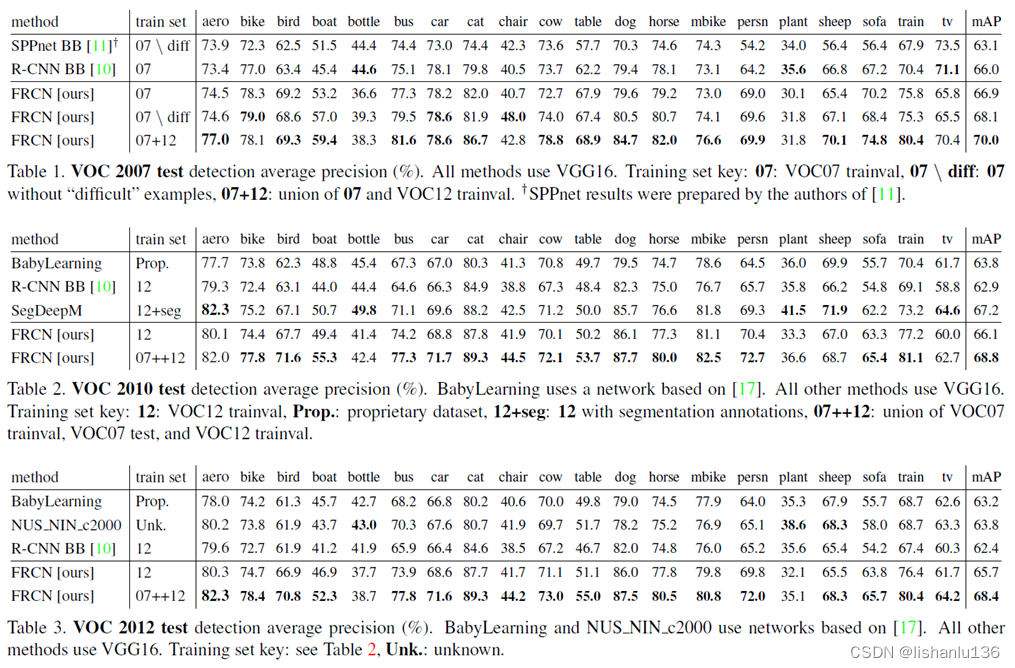
Fast R-CNN相对于之前的R-CNN工作做了如下改进:1、将CNN网络由AlexNet替换成了VGG16,能提取到更深层次特征;2、利用多任务损失函数,使得训练一步到位;3、训练阶段网络全部层都可以更新(相对于SPPNet而言,论文中说SPPNet在SPP层之前的卷积层无法更新,我在知乎上搜到的回答如下,回答来自知乎@可以啊,其实论文2.3节也解释了原因);4、不需要额外的磁盘空间用于存储特征。

2、Fast R-CNN细节
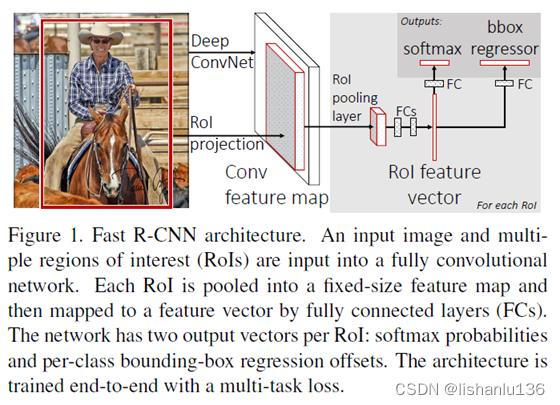
Fast R-CNN的结构如上图所示,网络接收的输入为一整张图片和一组区域候选框坐标,图片经过几组连续的conv+pooling层后得到特征图,然后,针对每个区域候选框,都将通过感兴趣区域池化层(ROI Pooling Layer)从特征图中提取一个固定长度的特征向量。每个特征向量被送到全连接层,最终连接到两个分支作为网络输出层:一个产生softmax概率估计,类别数为K个对象类加一个“背景”类;另一个为K个对象类输出的四个实数预测。每组4个值为K个类对应的预测box位置(反映在原图中需解码)。
2.1The RoI pooling layer
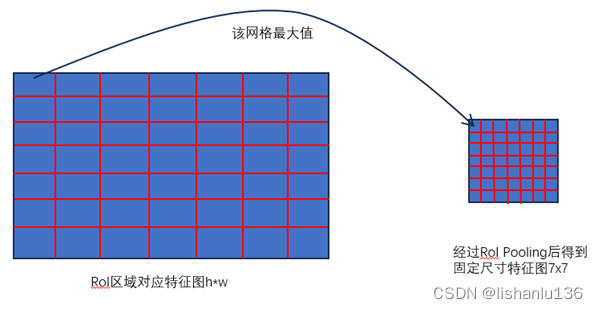
RoI池化层使用最大池化将任何有效感兴趣区域内的特征转换成具有固定尺寸HxW (例如,7x7)的小特征图。假设某个区域候选框对应特征图上的RoI区域窗口为(r,c,h,w),(r,c)代表矩形左上点,(h,w)代表矩形高,宽。RoI最大池化的工作原理是将h * w大小的RoI窗口划分为H * W个网格,每个网格的大小近似为h/H * w/W,然后将每个网格中的值最大池化到相应的输出网格单元中。RoI Pooling层可看作是单个尺度的SPP层(single–level SPP),如下图所示:
2.2 Fine-tuning for detection
在微调之前,先调整网络结构,将VGG16的最后一层maxpooling层替换成RoIpooling层,设置输出的固定尺寸为H=W=7;调整输出层为softmax和bounding–box回归,softmax类别为K+1,bounding-box输出为4K;调整输入为图片加上图片对应的区域候选框坐标。
样本采样采用分层采样,Fast R-CNN使用了一个训练过程,共同优化softmax分类器和bounding-box回归器,而不是在三个单独的阶段训练softmax分类器、SVM和回归器推理阶段。