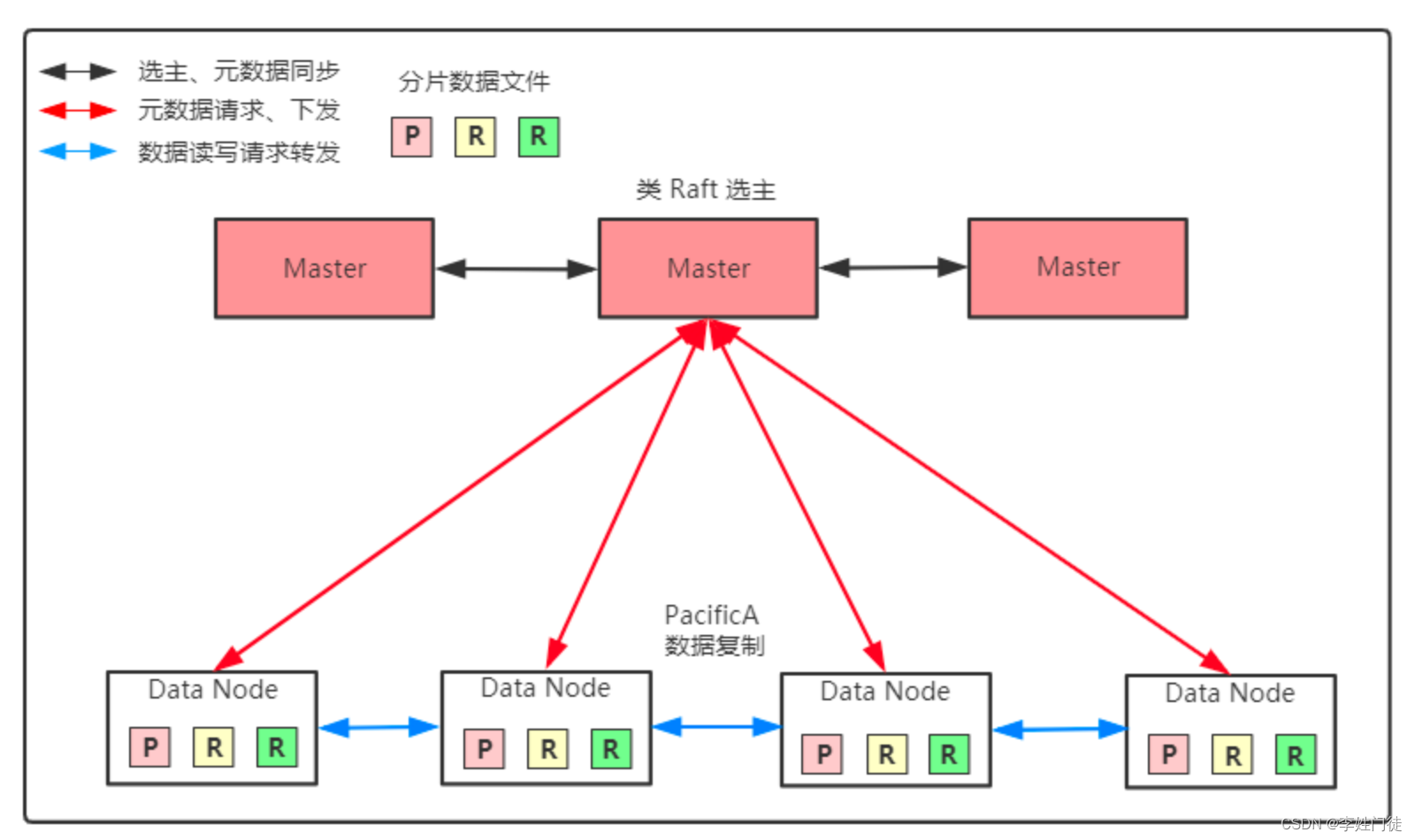
本文介绍: 查询使用的是OR逻辑,即如果查询字符串中的任何一个词项匹配文档中的一个或多个词项,则该文档就会被匹配成功。来指定匹配条件为AND逻辑,即只有查询字符串中的所有词项全部匹配文档中的词项时,才会将该文档匹配成功。查询没有进行分词处理,因此查询字符串应该是一个完整的单词或短语,而不能是一个词项的一部分。其中,第一个参数表示要查询的字段名称,第二个参数表示要查询的字符串。其中,第一个参数表示要查询的字段名称,第二个参数表示要查询的前缀字符串。其中,第一个参数表示要查询的字段名称,第二个参数表示要查询的值。
QueryBuilders.termQuery方法可以用来构建一个term查询,其基本用法如下:
其中,第一个参数表示要查询的字段名称,第二个参数表示要查询的值。
如果要查询多个条件,可以使用BoolQueryBuilder组合多个TermQueryBuilder,如下所示:
上述代码将构建一个bool查询,其中包含两个term查询,分别查询field1为value1和field2为value2的文档数据。在bool查询中,使用must表示查询条件必须同时满足,还可以使用should表示任意一个条件满足即可,也可以使用mustNot表示条件必须不满足。
range查询可以用来查询一定范围内的值。其基本用法如下:
其中,第一个参数表示要查询的字段名称,from表示起始值,to表示结束值。这里的value1和value2可以是任意值,包括数值、日期、字符串等。如果只想查询大于等于某个值或小于等于某个值,可以使用gte和lte方法,如下所示:
这里的gte表示大于等于value1,lte表示小于等于value2。
如果要查询在某个值范围内的文档,可以使用includeLower和includeUpper方法,如下所示:
match查询用于对某个字段进行文本匹配查询。它能够进行分词,并将查询字符串和分词后的文本进行比较,如果匹配则返回相应的文档。
prefix查询用于查询某个字段的前缀匹配。例如,如果要查询所有以某个词语开头的文档,可以使用prefix查询。
高亮查询
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。