本文介绍: Text Encoder将文字叙述转化为多个向量;Generation Model,输入噪音和text Encoder生成的向量,生成一个中间产物(中间产物有不同的形式)把中间产物(图中的中间产物是图片的压缩版本)输入Decoder,将图片还原为原始图像。
一、图像生成常见模型
前提:一张好的图像的资讯量是远超一句文句所能提供的。
差异:在图像中许多文字中没有提供的信息是需要机器进行大量的脑补才能产生的,这也是图片生成(或语音生成)与文字生成的不同之处,而这种不同体现在模型的设计上。
对比:



二、常见图像生成模型

1. VAE

说明:
2. Flow-based Generative Model
 说明:
说明:
1)训练Encoder,输入一张图片输出一个向量,并保证这个向量是Invertible可逆的(大小与输入图像一致);
2)多个向量组成Normal Distribution,输入Encoder得出生成图像;
3. Diffusion Model

4. GAN

三、浅谈Diffusion Model

1. Diffusion Model原理



2. Text-to-Image 文生图


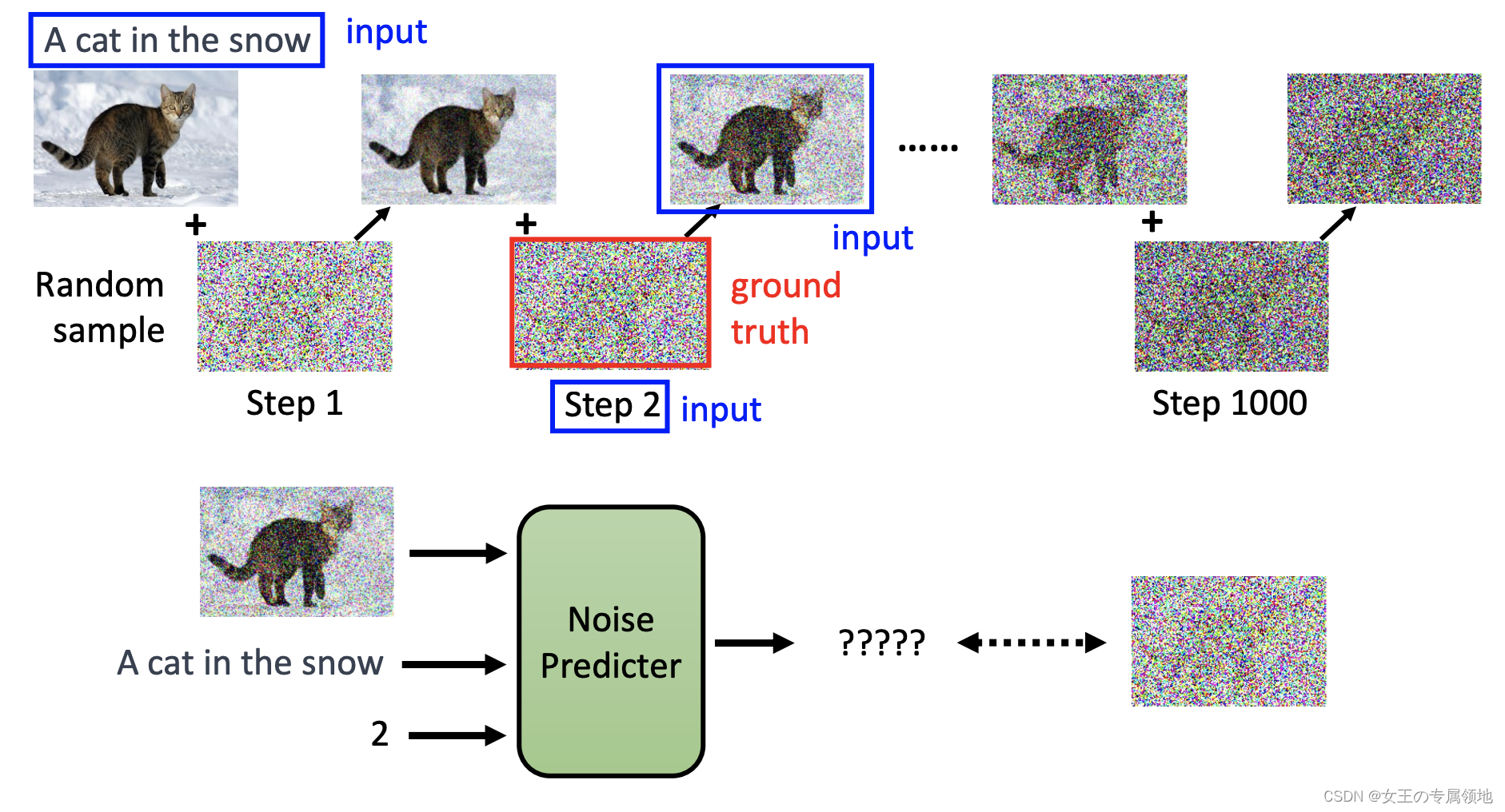
四、Stable Diffusion、DALL-E、Imagen 背后共同的套路
1. 观察Stable Diffusion、DALL-E、Imagen



2. 总结套路

模块 1:Text Encoder
模块2:Generation Model


模块3:Decoder


五、拓展学习
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)
