本文介绍: MongoDB复制集原理
复制集高可用
复制集选举
MongoDB 的复制集选举使用 Raft 算法(https://raft.github.io/)来实现,选举成功的必要条件是大多数投票节点存活。在具体的实现中,MongoDB 对 raft 协议添加了一些自己的扩展,这包括:
一个复制集最多可以有 50 个成员,但只有 7 个投票成员。这是因为一旦过多的成员参与数据复制、投票过程,将会带来更多可靠性方面的问题。
当复制集内存活的成员数量不足大多数时,整个复制集将无法选举出主节点,此时无法提供写服务,这些节点都将处于只读状态。此外,如果希望避免平票结果的产生,最好使用奇数个节点成员,比如 3 个或 5 个。当然,在 MongoDB 复制集的实现中,对于平票问题已经提供了解决方案:
自动故障转移
在故障转移场景中,我们所关心的问题是:
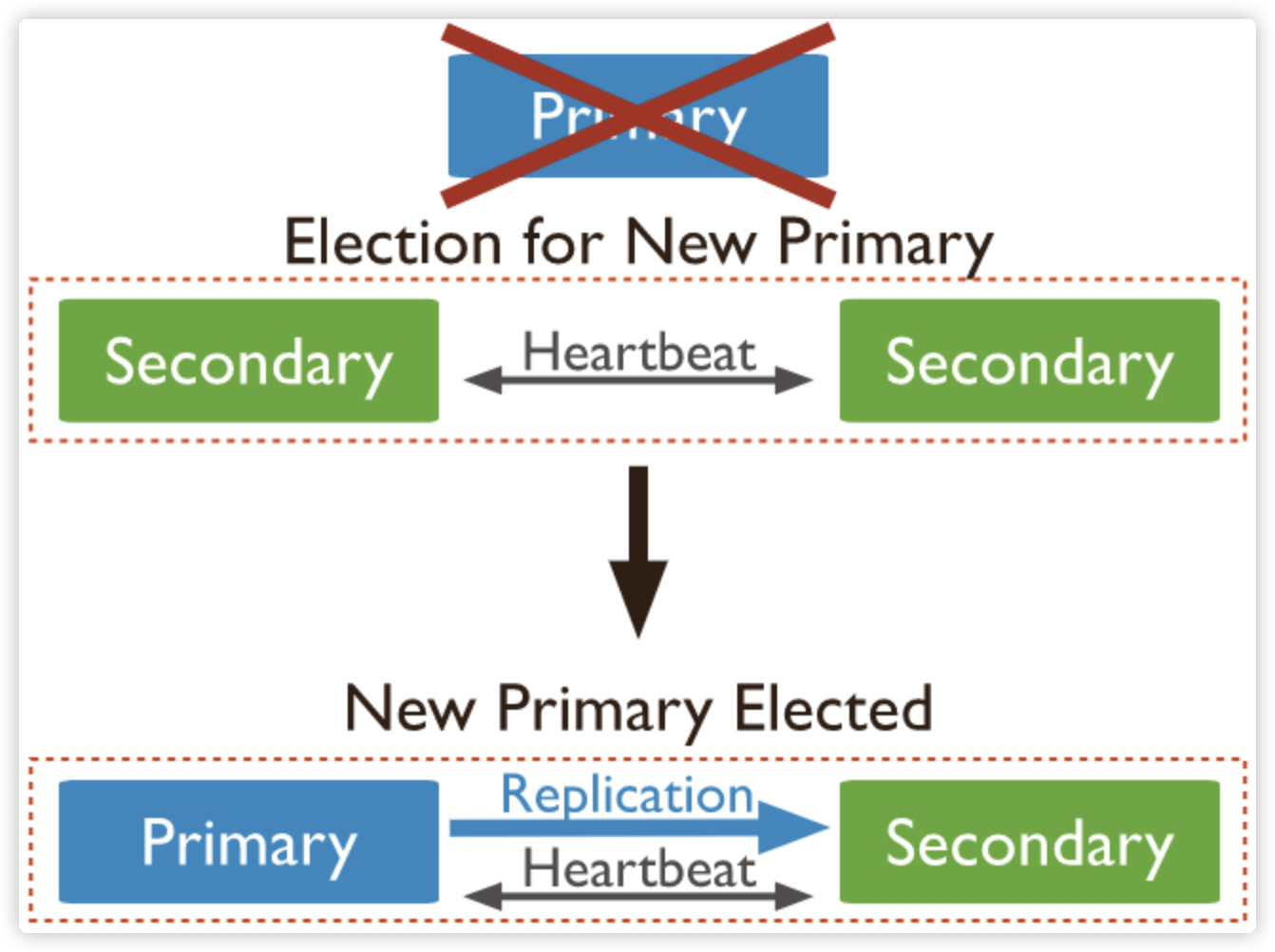
一个影响检测机制的因素是心跳,在复制集组建完成之后,各成员节点会开启定时器,持续向其他成员发起心跳,这里涉及的参数为 heartbeatIntervalMillis,即心跳间隔时间,默认值是 2s。如果心跳成功,则会持续以 2s 的频率继续发送心跳;如果心跳失败,则会立即重试心跳,一直到心跳恢复成功。
另一个重要的因素是选举超时检测,一次心跳检测失败并不会立即触发重新选举。实际上除了心跳,成员节点还会启动一个选举超时检测定时器,该定时器默认以 10s 的间隔执行,具体可以通过 electionTimeoutMillis 参数指定:
在 MongoDB 的实现中,选举超时检测的周期要略大于 electionTimeoutMillis 设定。该周期会加入一个随机偏移量,大约在 10~11.5s,如此的设计是为了错开多个备节点主动选举的时间,提升成功率。
复制集数据同步机制
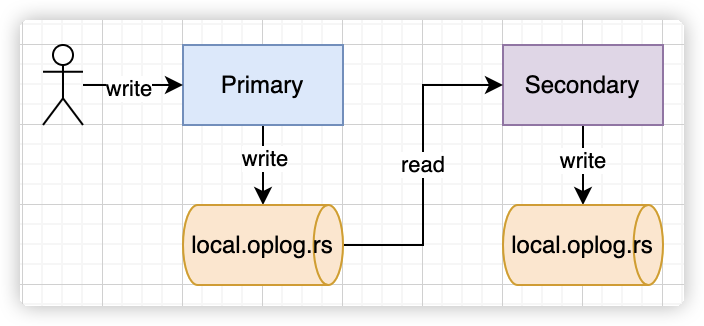
什么是 oplog
幂等性
复制延迟
数据回滚
同步源选择
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。