一、 实验目的
1、学习如何建立逻辑回归分类器用来识别猫。将引导你逐步了解神经网络的思维方式,同时磨练我们对深度学习的直觉。(说明):除非指令中明确要求使用,否则请勿在代码中使用循环(for / while)。
2、理解神经网络的基础:通过实现一个简单的神经网络模型(即使它只有一个隐藏层),可以更好地理解神经网络的工作原理,包括前向传播和反向传播过程,以及如何通过调整权重和偏置来优化模型。
3、为更复杂的任务做准备:通过实现Logistic回归,可以积累更多的机器学习和深度学习经验,为后续处理更复杂的任务,如图像分类、语音识别、自然语言处理等,做好准备。
4、学习建立学习算法的一般架构,包括:
初始化参数
计算损失函数及其梯度
使用优化算法(梯度下降)
按正确的顺序将以上所有三个功能集成到一个主模型上。
5、实现具有单个隐藏层的二分类神经网络
6、使用具有非线性激活函数的神经元
7、计算交叉熵损失,实现前向和后向传播。
二、 实验步骤
用神经网络实现逻辑回归
1、安装包:导入作业所需要的包,例如numpy、h5py、matpiotlib、scipy
2、问题概述:我们获得一个包含以下内容的数据集(“data.h5”):标记为cat(y = 1)或非cat(y = 0)的m_train训练图像集标记为cat或non-cat的m_test测试图像集。
图像维度为(num_px,num_px,3),其中3表示3个通道(RGB)。 因此,每个图像都是正方形(高度= num_px)和(宽度= num_px)。
你将构建一个简单的图像识别算法,该算法可以将图片正确分类为猫和非猫
3、学习算法的一般架构:设计一种简单的算法来区分猫图像和非猫图像,使用神经网络思维方式建立logistic回归。
4、构建算法的各个部分
建立神经网络的主要步骤是:
(1)定义模型结构(例如输入特征的数量)
(2)初始化模型的参数
(3)循环:
计算当前损失(正向传播)
计算当前梯度(向后传播)
更新参数(梯度下降)
4-1、定义辅助该函数
4-2、初始化参数
4-3、前向和后向传播
4-4、优化函数
5、将所有的功能合并到模型中:将所有构件(在上一部分中实现的功能)以正确的顺序放在一起,从而得到整体的模型结构。
一层隐藏层的神经网络
1、安装包:导入作业所需要的包,例如numpy、h5py、matpiotlib、scipy
2、数据集:获取处理的数据集
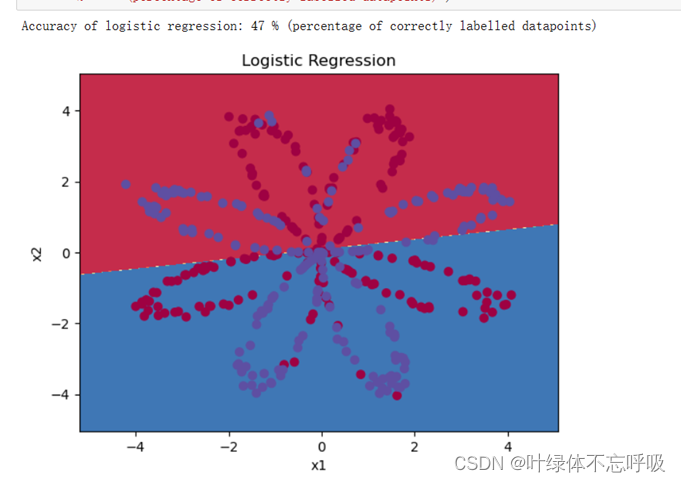
3、简单的logistic回归:在构建完整的神经网络之前,先看看逻辑回归在此问题上的表现。可以使用sklearn的内置函数来执行此操作。
4、神经网络模型:建立神经网络的一般方法是:
(1)定义神经网络结构(输入单元数,隐藏单元数等)。
(2)初始化模型的参数
(3)循环:
实现前向传播
计算损失
后向传播以获得梯度
更新参数(梯度下降)
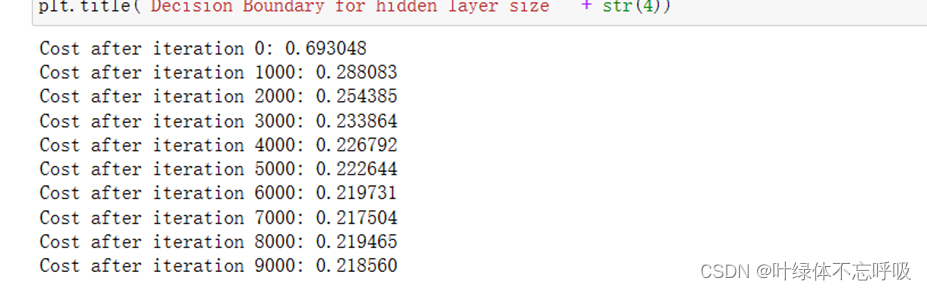
4-1、定义神经网络结构:定义三个变量(n_x,n_h,n_y)
4-2、初始化模型的参数(注意参数大小正确)
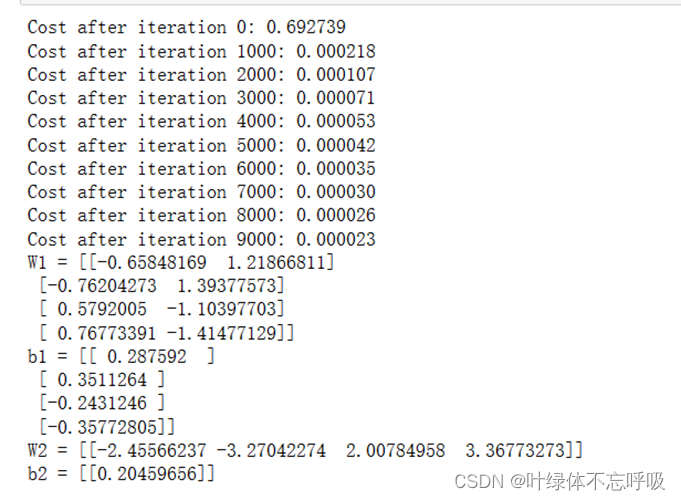
4-3、循环
4-4、在nn_model()中集成:在nn_model()中集成4.1、4.2和4.3部分中的函数。
三、 实验代码分析
1、当你想将维度为(a,b,c,d)的矩阵X展平为形状为(bcd, a)的矩阵X_flatten时的一个技巧是:
X_flatten = X.reshape(X.shape [0],-1).T # 其中X.T是X的转置
2、np.zero()用于创建一个给定形状和类型的全0数组
3、assert(w.shape == (dim, 1)):这行代码用于断言,即判断条件是否为真。它用于检查权重向量w的形状是否为(dim, 1),即一个列向量。如果条件不满足(即形状不等于(dim, 1)),则会抛出一个AssertionError错误。这个断言语句的作用是确保权重向量w的形状是正确的。
4、assert(isinstance(b, float) or isinstance(b, int)):这行代码用于断言b的类型是float或者int。其中isinstance(b, float)用于检查b是否是float类型,isinstance(b, int)用于检查b是否是int类型。如果条件不满足(即不是float类型也不是int类型),则会抛出一个AssertionError错误。这个断言语句的作用是确保偏置项b的类型是正确的,即为float或者int型。
5、A = sigmoid(np.dot(w.T, X) + b):这行代码计算了前向传播中的激活值A。使用权重向量w对特征矩阵X进行加权求和,再加上偏置项b,然后通过sigmoid函数进行激活。
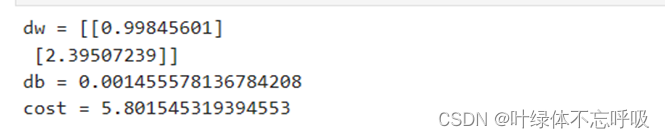
6、cost = -(1.0 / m) * np.sum(Y * np.log(A) + (1 – Y) * np.log(1 – A)):这行代码计算了损失函数的值。利用预测值A与实际标签Y进行比较,并使用损失函数计算代价。
7、dw = (1.0 / m) * np.dot(X, (A – Y).T):这行代码计算了权重矩阵w的梯度。通过误差(A-Y)与特征矩阵X的乘积再除以样本数量m来计算梯度dw。
8、db = (1.0 / m) * np.sum(A – Y):这行代码计算了偏置项b的梯度。直接将(A-Y)的平均值作为梯度db。
9、Y_prediction = np.zeros((1, m)):创建一个形状为(1, m)的全零数组,用于存储预测结果。其中m表示样本数量。
10、w = w.reshape(X.shape[0], 1):调整参数w的形状,将其变为列向量。这么做是为了与输入数据X进行矩阵乘法操作。
11、A = sigmoid(np.dot(w.T, X) + b):计算前向传播中的激活值A。使用训练好的参数w和b对输入数据X进行加权求和操作,并通过sigmoid函数进行激活。
12、Y_prediction = np.zeros((1, m)):创建一个形状为(1, m)的全零数组,用于存储预测结果。其中m表示样本数量
13、w = w.reshape(X.shape[0], 1):调整参数w的形状,将其变为列向量。这么做是为了与输入数据X进行矩阵乘法操作。
14、A = sigmoid(np.dot(w.T, X) + b):计算前向传播中的激活值A。使用训练好的参数w和b对输入数据X进行加权求和操作,并通过sigmoid函数进行激活。
15、for i in range(A.shape[1]):通过循环遍历激活值A的每一列,即遍历每个样本的预测结果。
16、if A[0, i] > 0.5:如果激活值A的当前元素大于0.5,即代表预测结果为正类。Y_prediction[0, i] = 1:将预测结果设置为1,表示正类。else::否则,如果激活值A的当前元素小于等于0.5,即代表预测结果为负类。Y_prediction[0, i] = 0:将预测结果设置为0,表示负类。通过这个循环,将概率值A转换为实际的预测结果,并将其保存在预测结果数组Y_prediction中。最后,返回Y_prediction作为最终的预测结果。
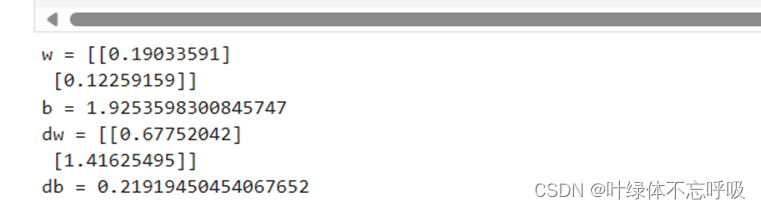
17、w, b = initialize_with_zeros(X_train.shape[0]):使用输入数据的特征数量初始化权重w和偏置项b。
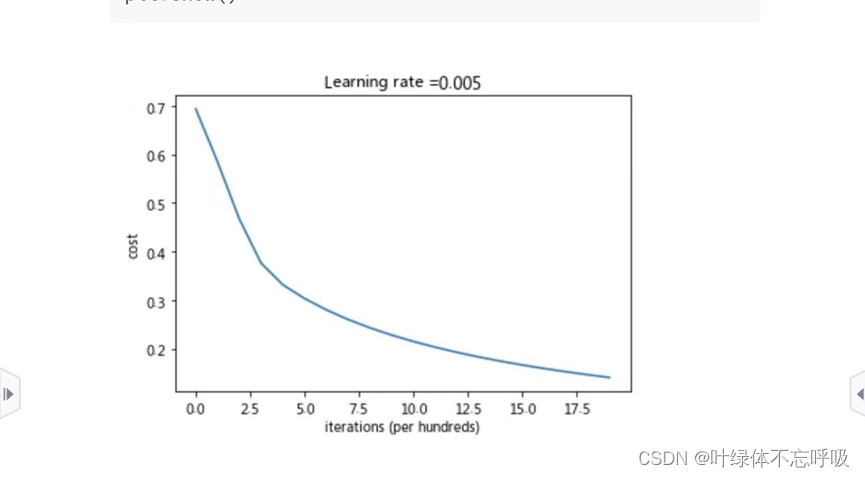
18、parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost):调用optimize函数来训练模型并得到优化后的参数、梯度以及成本列表。
19、w = parameters[“w”]和b = parameters[“b”]:从优化后的参数字典中提取最终的参数值。
20、Y_prediction_test = predict(w, b, X_test)和Y_prediction_train = predict(w, b, X_train):使用训练得到的参数对测试集和训练集数据进行预测。
21、d={“costs”:costs,“Y_prediction_test”:Y_prediction_test, “Y_prediction_train” : Y_prediction_train, “w” : w, “b” : b, “learning_rate” : learning_rate, “num_iterations”: num_iterations}:将成本列表、预测结果和参数等信息保存在一个字典d中。
22、import numpy as np:导入numpy库,用于进行数值计算和数组操作。
23、import matplotlib.pyplot as plt:导入matplotlib库中的pyplot模块,用于绘图和数据可视化。
24、from testCases_v2 import *:从testCases_v2模块中导入所有内容。testCases_v2模块包含了一些测试样例,用于验证代码的正确性。
25、import sklearn:导入scikit-learn库,用于机器学习任务。
26、import sklearn.datasets:导入sklearn库中的datasets模块,用于加载数据集。
27、import sklearn.linear_model:导入sklearn库中的linear_model模块,用于线性模型的训练和预测。
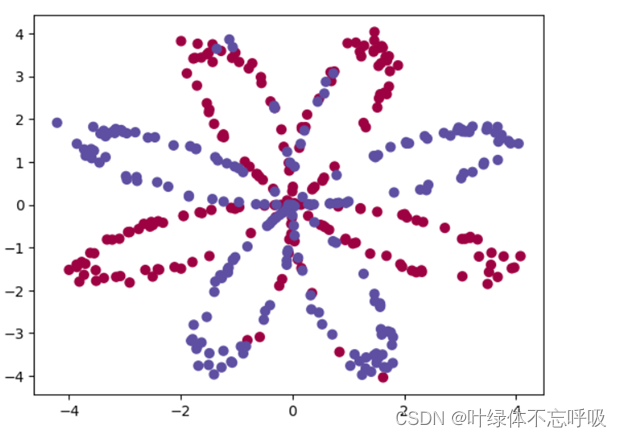
28、plt.scatter(X[0, :], X[1, :], c=Y[0, :], s=40, cmap=plt.cm.Spectral):通过plt.scatter函数绘制散点图。其中,X[0, :]表示X的第一行数据,X[1, :]表示X的第二行数据,Y[0, :]表示Y的第一行数据。c=Y[0, :]表示根据Y的数值颜色着色,s=40表示散点的大小为40,cmap=plt.cm.Spectral表示使用Spectral色彩映射方案进行颜色着色。
29、clf = sklearn.linear_model.LogisticRegressionCV():创建一个逻辑回归模型对象clf,并使用LogisticRegressionCV类进行初始化。LogisticRegressionCV是scikit-learn中的逻辑回归模型的交叉验证版本,可以自动选择最佳的正则化参数C。
30、clf.fit(X.T, Y.T[:, 0]):使用fit方法对模型进行训练。fit方法接受输入数据X和标签Y,其中X.T是输入数据的转置,Y.T[:, 0]是标签数据的第一列。逻辑回归模型将学习根据输入X预测标签Y。训练后,逻辑回归模型将会学习到最佳的权重系数和截距,以用于预测新的样本数据。
31、plot_decision_boundary(lambda x:clf.predict(x),X,Y[0, :]):调用plot_decision_boundary函数,绘制决策边界。其中,lambda函数x: clf.predict(x)用于根据输入数据x预测标签,X表示输入特征数据,Y[0, :]表示对应的标签。
plot_decision_boundary函数会先生成一组坐标点,然后通过分类器(逻辑回归模型)对每个坐标点进行预测,最后绘制出决策边界。
32、np.random.seed(2):设置随机种子,保证每次运行时产生的随机数是一致的,用于可重现性。
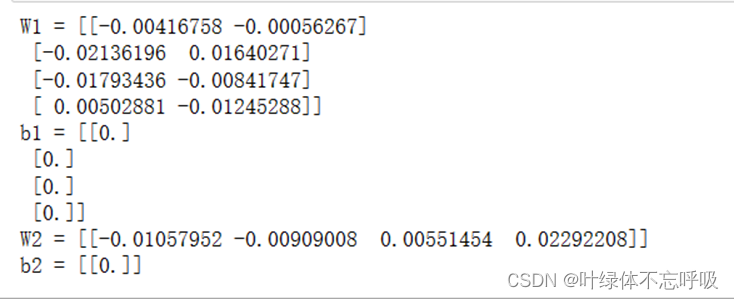
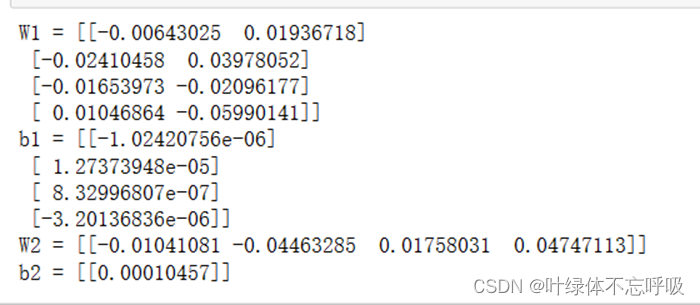
33、W1 = np.random.randn(n_h, n_x) * 0.01:初始化输入层到隐藏层的权重矩阵W1,采用标准正态分布随机初始化,并乘以0.01缩放权重的数值范围。
34、b1 = np.zeros((n_h, 1)):初始化隐藏层的偏置项b1为全零数组,大小为(n_h, 1),其中n_h表示隐藏层的单元数量。
35、W2 = np.random.randn(n_y, n_h) * 0.01:初始化隐藏层到输出层的权重矩阵W2,采用标准正态分布随机初始化,并乘以0.01缩放权重的数值范围。
36、b2 = np.zeros((n_y, 1)):初始化输出层的偏置项b2为全零数组,大小为(n_y, 1),其中n_y表示输出层的单元数量。
37、 assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))四个断言用于检查参数的形状是否正确,确保参数的维度匹配。
38、 parameters = {“W1”: W1,
“b1”: b1,
“W2”: W2,
“b2”: b2}将初始化得到的参数保存在一个字典parameters中,并返回该字典作为初始化后的参数。
39、Z1 = np.dot(W1, X) + b1:计算输入层到隐藏层的加权求和结果 Z1。通过 np.dot 函数对权重矩阵 W1 和输入数据 X 进行矩阵乘法操作,然后加上偏置项 b1 实现加权求和。
40、A1 = np.tanh(Z1):对Z1进行激活,得到隐藏层的激活值 A1。通过 np.tanh 函数对Z1进行激活操作,以实现非线性映射。
41、Z2 = np.dot(W2, A1) + b2:计算隐藏层到输出层的加权求和结果 Z2。通过 np.dot函数对权重矩阵W2和隐藏层的激活值A1进行矩阵乘法操作,然后加上偏置项b2实现加权求和。
42、A2 = sigmoid(Z2):对Z2 进行激活,得到输出层的激活值A2。通过 sigmoid 函数对Z2进行激活操作,将结果限制在0到1的范围内,表示分类的概率。
43、assert(A2.shape == (1, X.shape[1]))使用断言检查输出层的形状是否符合预期,即判断 A2 是否为一个形状为 (1, 样本数量) 的数组。
44、cache = {“Z1”: Z1,
“A1”: A1,
“Z2”: Z2,
“A2”: A2}将中间变量 Z1、A1、Z2、A2 保存在一个字典 cache 中,并返回该字典。cache 将在后续的反向传播中使用,以便计算梯度和更新参数。
45、X_assess, parameters = forward_propagation_test_case():调用前向传播测试用例函数 forward_propagation_test_case,返回测试用例中的输入数据 X_assess 和参数字典 parameters。
46、A2, cache = forward_propagation(X_assess, parameters):调用前向传播函数 forward_propagation,传入输入数据 X_assess和参数字典parameters。该函数会执行神经网络的前向传播过程,并返回输出层的激活值A2和中间变量的字典 cache。
47、logprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1 – A2), 1 – Y),
cost = -np.sum(logprobs) / m:通过np.multiply函数对A2和Y进行逐元素相乘,得到的结果是两者对应位置的元素相乘的数组。然后,将逐元素相乘的结果与np.log(A2)和np.log(1 – A2) 相加,得到一个包含各个样本的损失值的数组。这里使用np.log函数计算了交叉熵损失。接下来,通过-np.sum(logprobs)计算所有样本的损失之和。
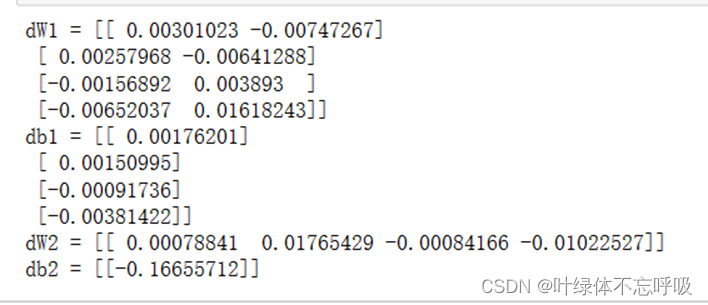
48、dZ2 = A2 – Y:计算输出层激活值A2相对于标签Y的梯度,即通过A2 – Y计算差异。
49、dW2 = np.dot(dZ2, A1.T) / m:计算隐藏层到输出层权重W2的梯度,即通过np.dot(dZ2, A1.T)计算内积,再除以样本数量m。
50、db2 = np.sum(dZ2, axis=1, keepdims=True) / m:计算隐藏层到输出层偏置项b2的梯度,即通过np.sum(dZ2, axis=1, keepdims=True)计算沿着行方向的求和,并除以样本数量m。
51、dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 – np.power(A1, 2)):计算输入层到隐藏层的梯度,通过np.dot(W2.T, dZ2)计算内积,再逐元素相乘于(1 – np.power(A1, 2)),其中np.power(A1, 2)表示A1的元素逐元素平方。
52、dW1 = np.dot(dZ1, X.T) / m:计算输入层到隐藏层权重W1的梯度,即通过np.dot(dZ1, X.T)计算内积,再除以样本数量m。
53、db1 = np.sum(dZ1, axis=1, keepdims=True) / m:计算输入层到隐藏层偏置项b1的梯度,即通过np.sum(dZ1, axis=1, keepdims=True)计算沿着行方向的求和,并除以样本数量m。
54、A2, cache = forward_propagation(X, parameters):调用前向传播函数 forward_propagation,传入输入数据X和参数字典parameters。该函数会执行神经网络的前向传播过程,计算得到输出层的激活值A2,并返回中间变量的字典cache。
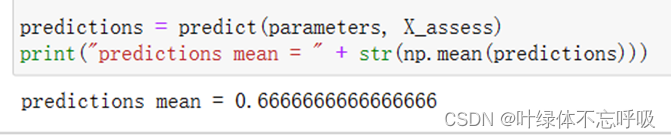
55、predictions = (A2 > 0.5):根据输出层的激活值 A2,将大于 0.5 的部分设置为 True,否则为 False。这样可以对样本进行分类,得到一个布尔类型的数组 predictions,根据该数组中的值可以判断样本的预测类别。
四、 运行结果
问题概述:构建一个简单的图像识别算法,该算法能够将图片正确分类为猫和非猫
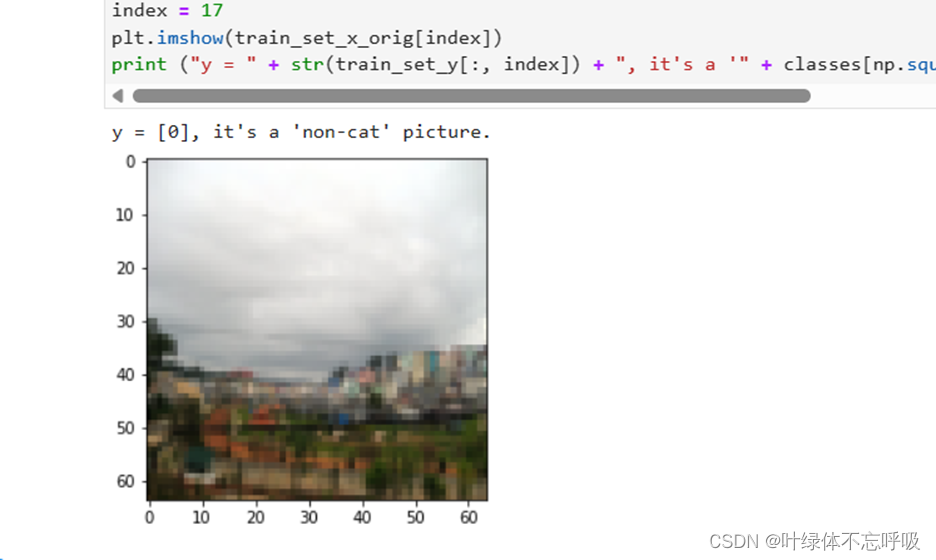

练习结果:m_train(训练集示例数量)
m_test(测试集示例数量)
num_px(=训练图像的高度=训练图像的宽度)
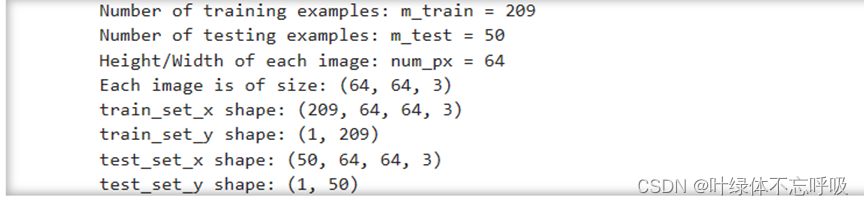
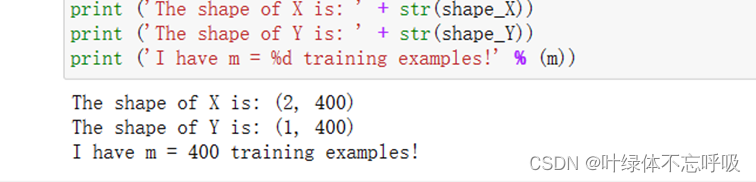
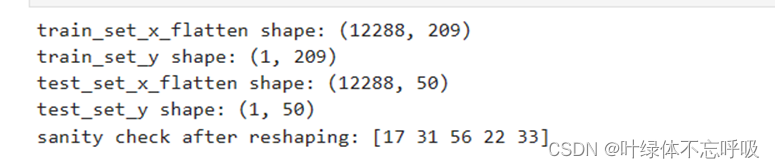
练习结果:重塑训练和测试数据集,以便将大小(num_px,num_px,3)的图像展平为单个形状的向量(num_pxnum_px3, 1)。
练习结果:调用sigmoid函数结果

练习结果:初始化参数结果