本文介绍: Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
Kafka用法总结
一、Kafka是什么
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域。
二、消息队列
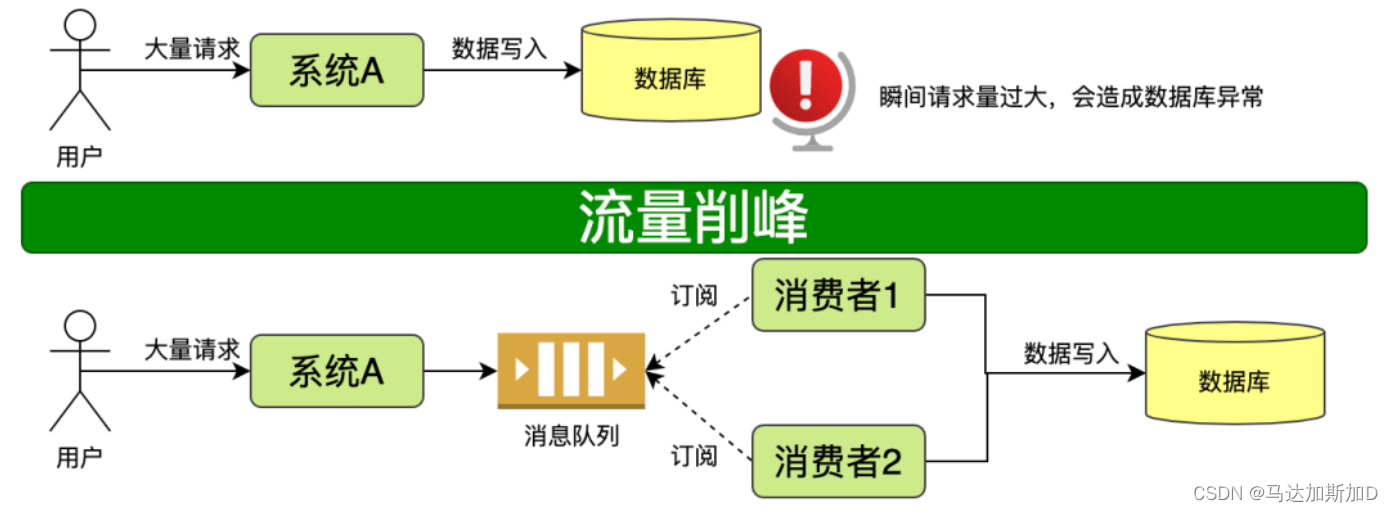
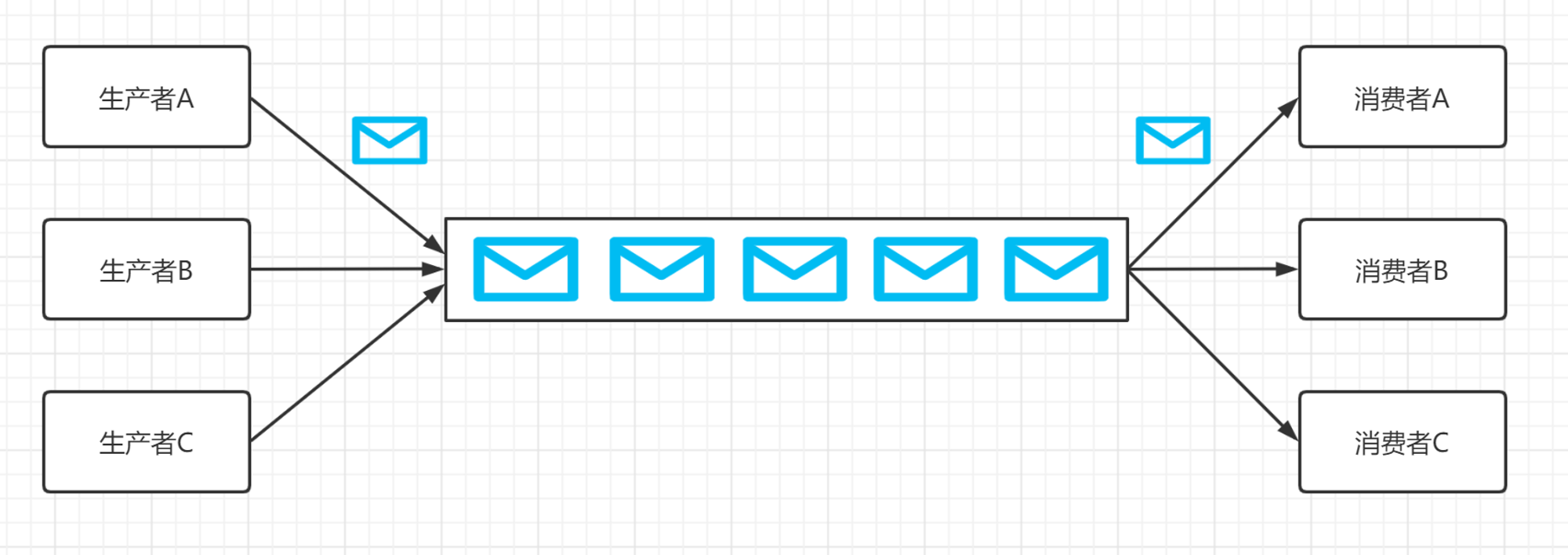
消息队列(Message queue)是一种进程间通信或同一进程的不同线程间的通信方式。把数据放到消息队列的叫做生产者,把数据从生产队列取出的叫做消费者。
消息队列目前有两种模式,点对点模式 和 发布/订阅模式
1、点对点模式

消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
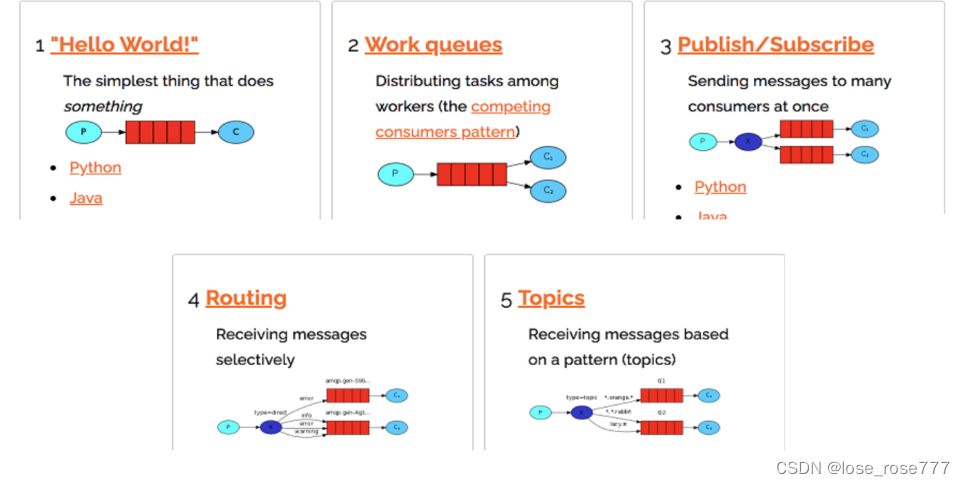
2、发布/订阅模式

三、Kafka架构

四、安装部署
五、使用
1、创建topic
2、查看topic
3、查看topic详情

4、发送消息

5、消费消息

6、修改分区数

7、删除topic
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。
![[MFC] MFC消息机制的补充](https://img-blog.csdnimg.cn/direct/4e6d632d6c144126a691d901337a1749.png)