本文介绍: Python实现综合CEEMDAN分解与基于麻雀优化算法的SSA-BiLSTM-Attention预测模型

往期精彩内容:
时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型-CSDN博客
前言
1 风速数据CEEMDAN分解与可视化
1.1 导入数据
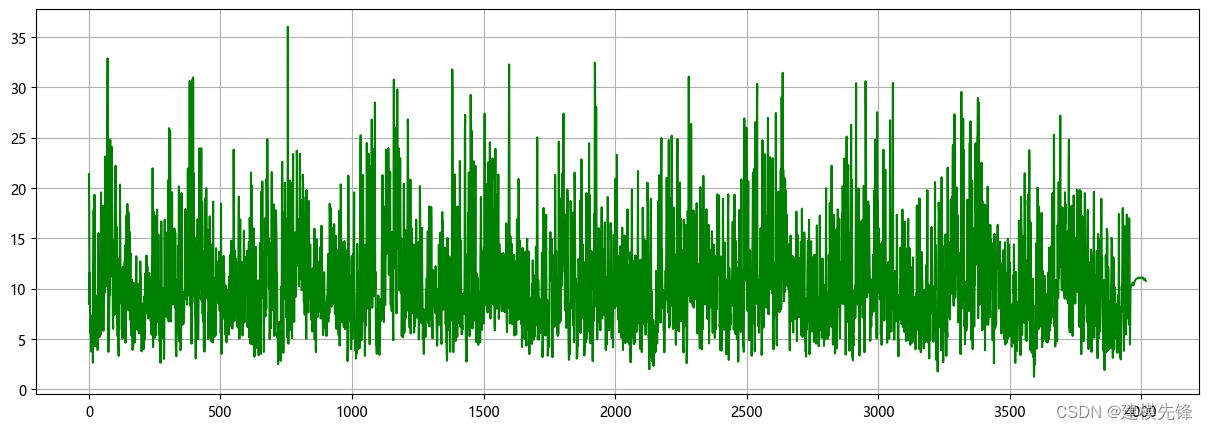
1.2 CEEMDAN分解
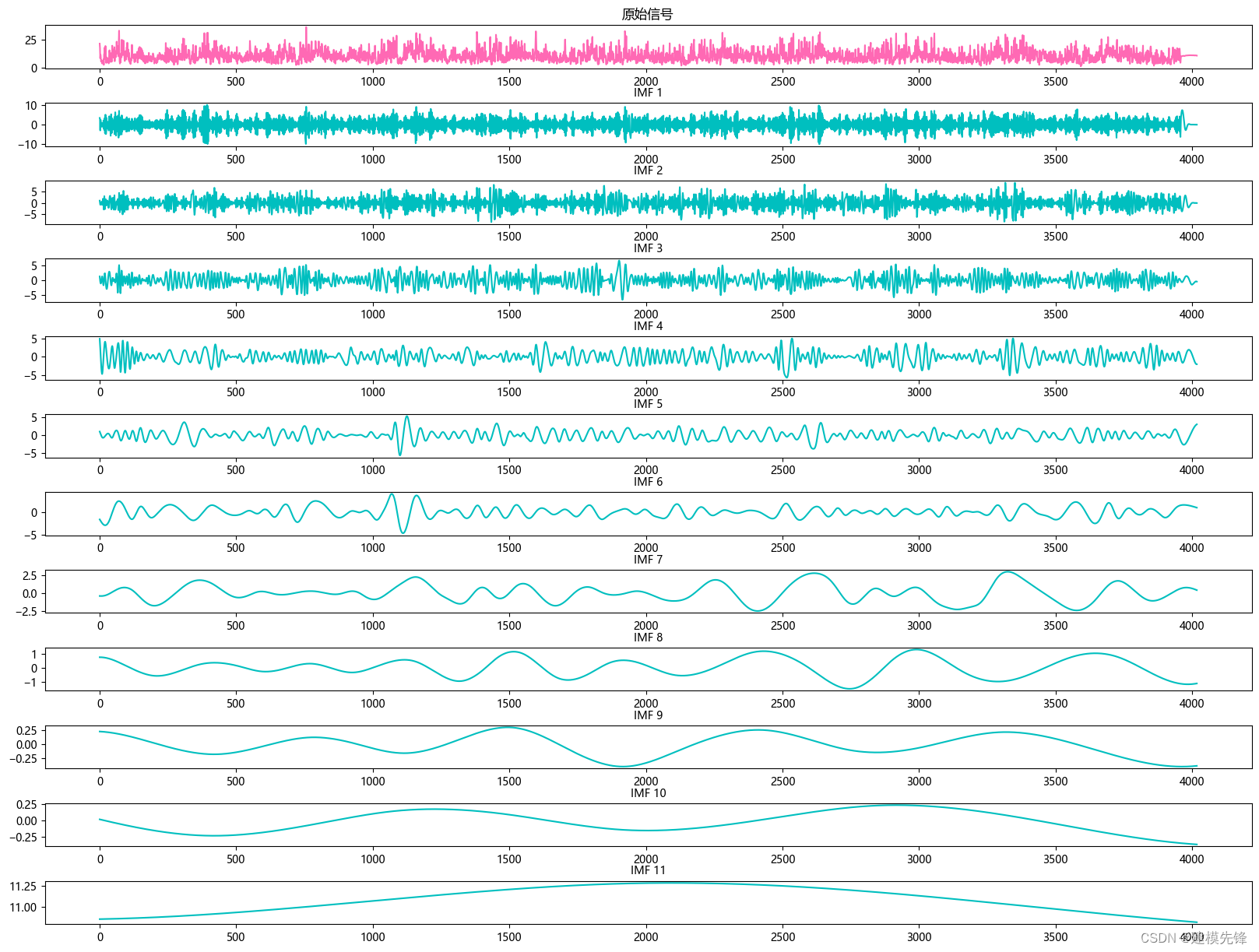
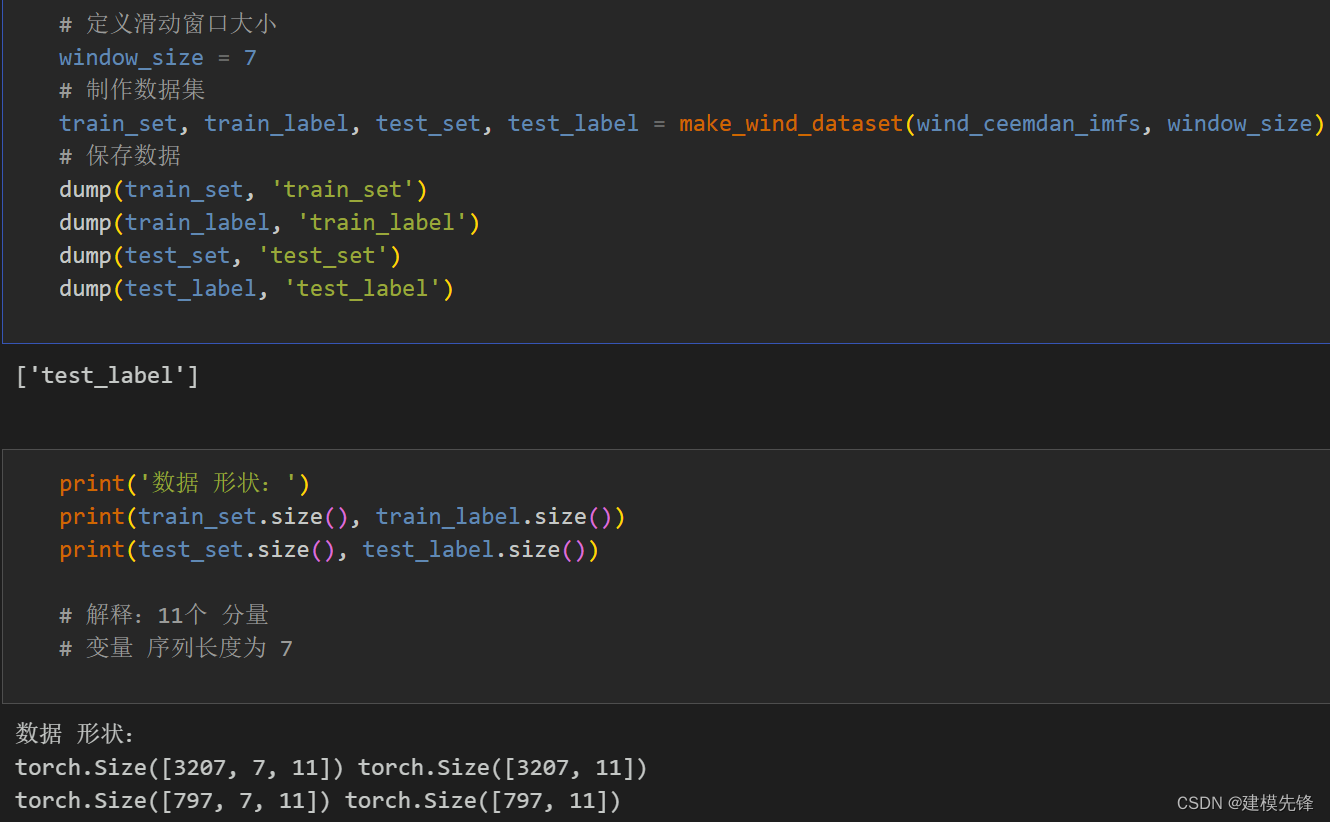
2 数据集制作与预处理
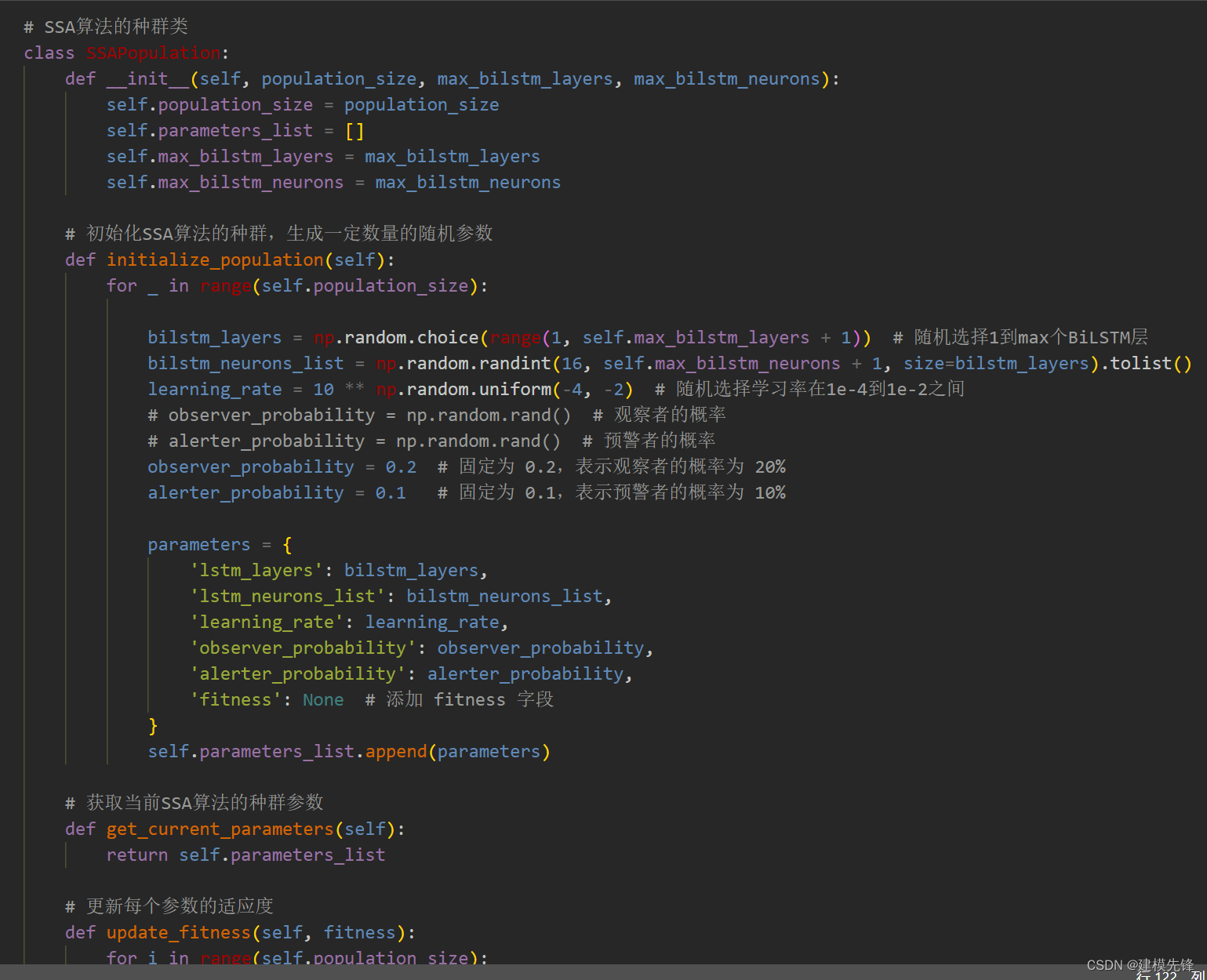
3 麻雀优化算法
3.1 麻雀优化算法介绍
3.2 基于Python的麻雀优化算法实现
3.3 麻雀优化算法-超参数寻优过程

4 基于CEEMADN的 SSA-BiLSTM-Attention 模型预测
4.1 定义SSA-BiLSTM-Attention预测模型
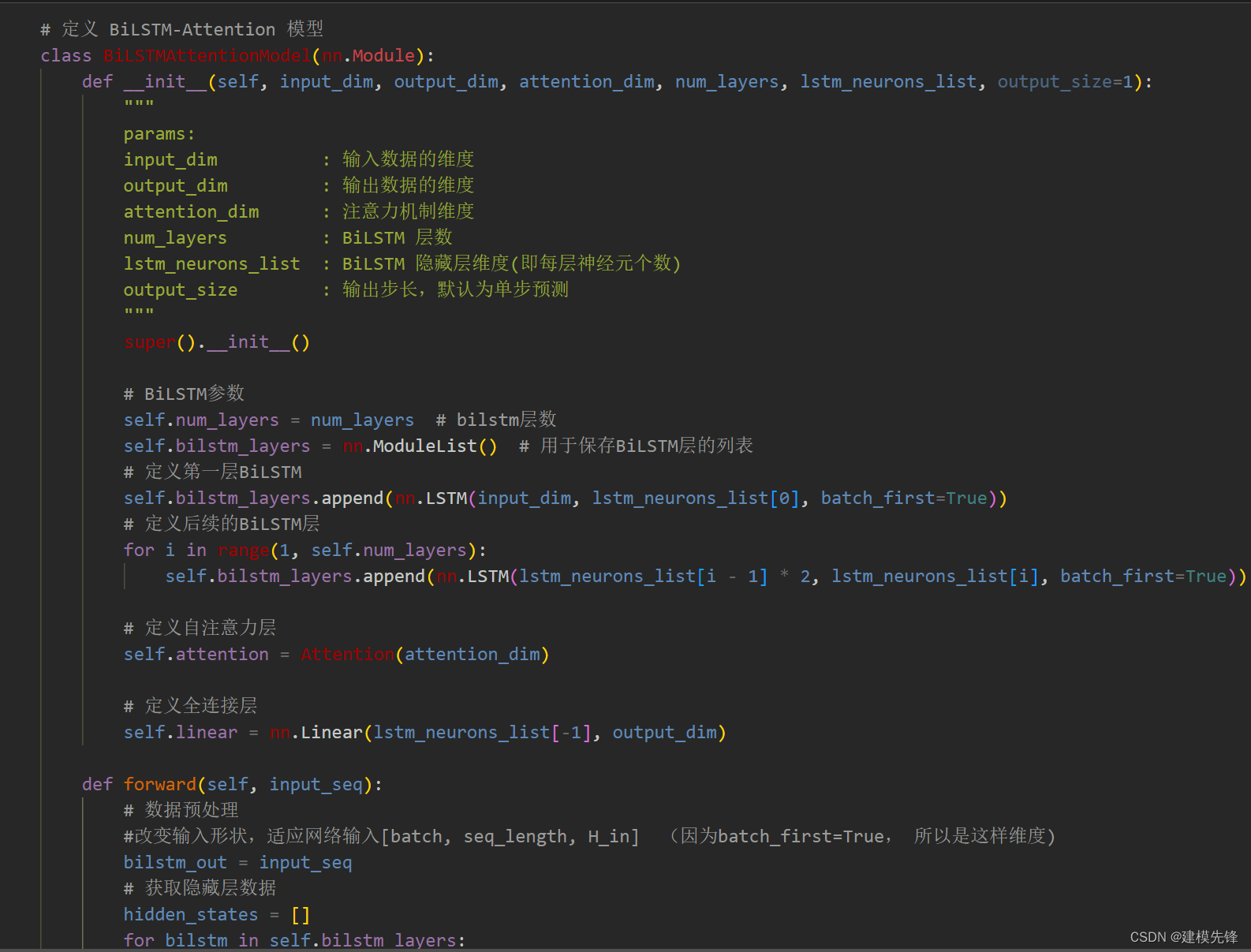
4.2 设置参数,训练模型

4.3 模型评估

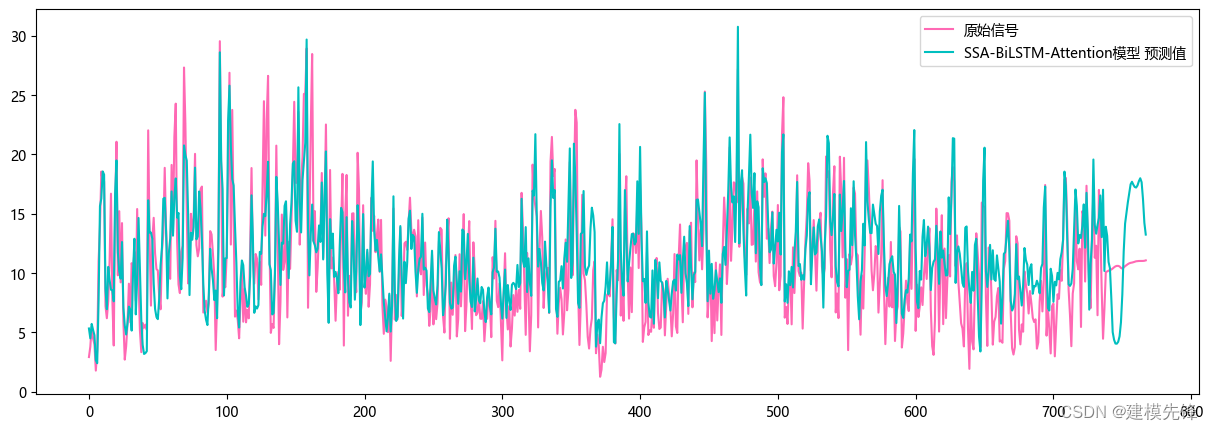
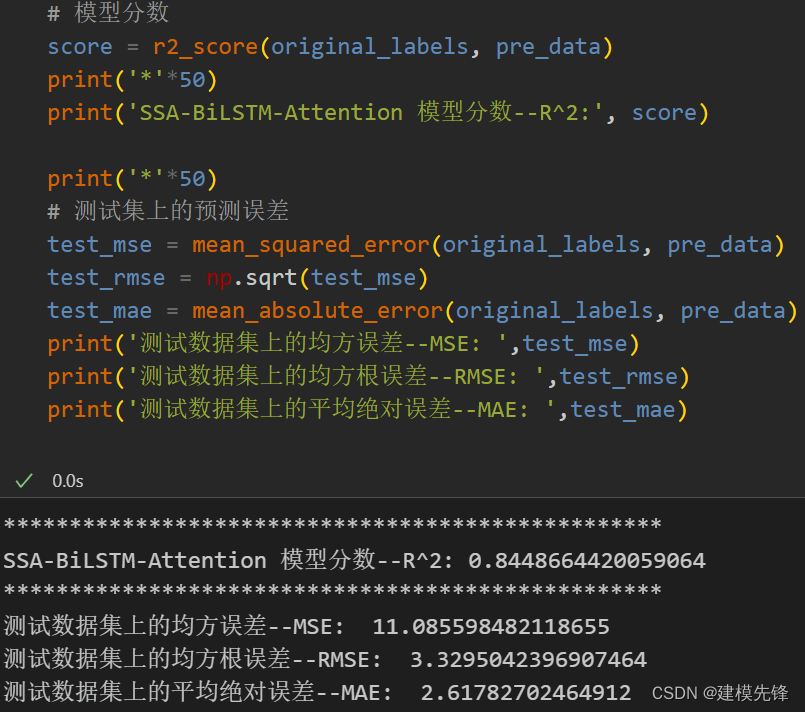
代码、数据如下:
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。