“embeddings”的中文翻译是“嵌入”或“嵌入向量”。在自然语言处理(NLP)领域,通常被称为“词向量”或“词嵌入”,它是表示词汇或令牌的一种方式,通过将这些词汇或令牌映射到一个向量空间中的点,以捕捉它们之间的语义和语法关系。这些向量通常是通过训练模型(如Word2Vec、GloVe等)学习得到的,用于各种NLP任务,如文本分类、命名实体识别、情感分析等。
embeddings是一个相对低维的空间,可以将高维向量转换到其中。在机器学习中,embeddings通常用于对大型输入(例如表示单词的稀疏向量)进行处理,可以更容易地进行模型训练。理想情况下,embeddings通过将语义相似的输入紧密地放置在嵌入空间中来捕获输入的一些语义。
在NLP领域,embeddings通常用于单词的表示。与传统的基于规则或基于词袋模型的方法相比,embeddings可以提供更丰富的语义信息,并且可以更好地处理语义相似的单词。例如,“table”和“desk”在语义上很相似,因此它们的embeddings也应该在嵌入空间中彼此接近。
需要注意的是,虽然embeddings技术具有很多优势,但它也有一些局限之处。其中一个很大的限制是词的动态属性,例如一个词在不同的语境下可能有不同的含义。
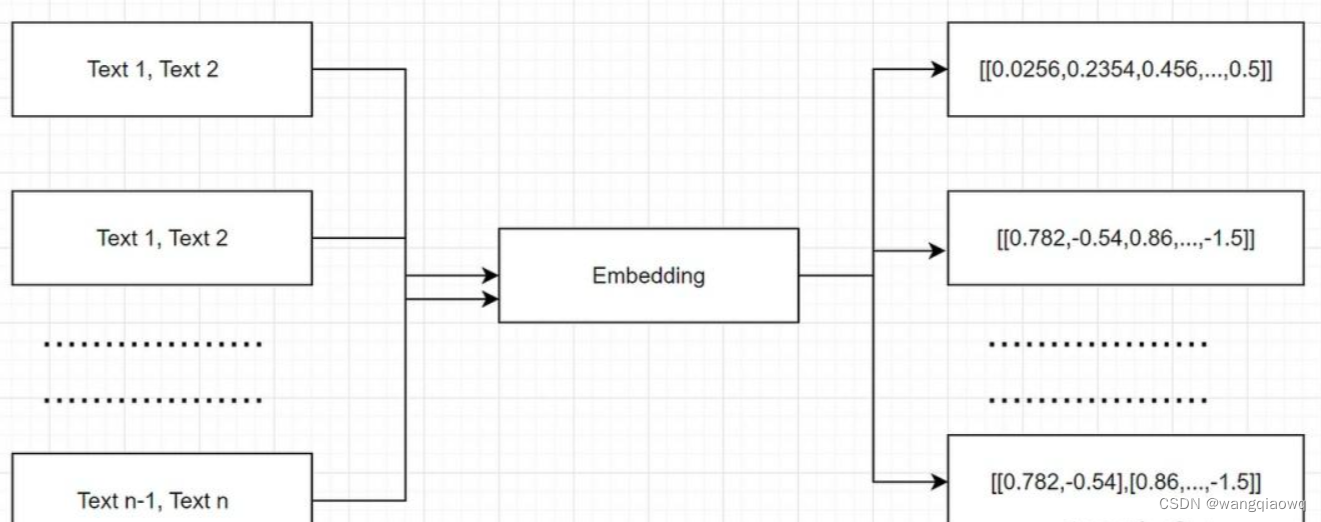
我们的文档以文本的形式表示,因此很难根据问题找到相关信息。假设你需要在1000页中找到苹果上一季度的收入,并将收入与前几年进行比较。这可能需要多大的挑战性和耗时?因此,为了让我们的搜索更容易,我们首先需要以数字格式转换或表示单词或短语,这些单词或短语可以用作机器学习模型的输入。换句话说,帮助机器理解文本。embeddings将每个单词或短语映射到实数向量,通常具有数百个维度,使得相似的单词或短语被映射到嵌入空间中的相似向量。
使用embeddings的主要优点之一是,它们可以捕捉单词或短语之间的语义和句法关系。例如,在嵌入空间中,“国王”和“王后”的向量比“苹果”的向量更接近,因为它们在语义上与王室头衔相关。