本文介绍: 爬虫,又称网页抓取、网络蜘蛛或网络爬虫,是一种自动浏览互联网并从网站上获取信息的程序或脚本。本文介绍goquery框架,并用之实现一个爬取自己主页,为自己添加流量的小爬虫。
爬虫介绍
爬虫,又称网页抓取、网络蜘蛛或网络爬虫,是一种自动浏览互联网并从网站上获取信息的程序或脚本。它通过模拟人类浏览器的行为,按照预设的规则和策略遍历互联网上的网页,并将所获取的数据存储下来进行进一步处理和分析。
爬虫在我们生活中可以产生的东西有很多
在生活中爬虫其实可以做很多事情,鉴于本文是一个入门教程,就接下来会以一个爬取csdn网页增加流量的列子逐步介绍和完善我们的爬虫程序。
goquery介绍
GoQuery是专为Go(Golang)语言设计的一个强大的HTML解析和查询库。它模仿了jQuery的API风格,使得在Go中处理HTML文档变得简单且直观。
GoQuery主要用于网页抓取(Web Scraping),能够通过CSS选择器来定位、遍历和操作HTML元素。你可以使用它来提取网页中的特定数据、修改DOM结构或进行其他与HTML文档相关的操作。
利用NewDocumentFromReader方法获取主页信息
NewDocumentFromReader 是GoQuery库中的一个函数,用于从io.Reader接口读取的HTML数据创建一个新的文档对象。对于文档对象是什么我们会在下文经性讲解。
func NewDocumentFromReader(reader io.Reader) (*Document, error)
Document介绍
通过查询获取文章信息
css选择器介绍
goquery中的选择器
标签。
获取主页中的文章链接
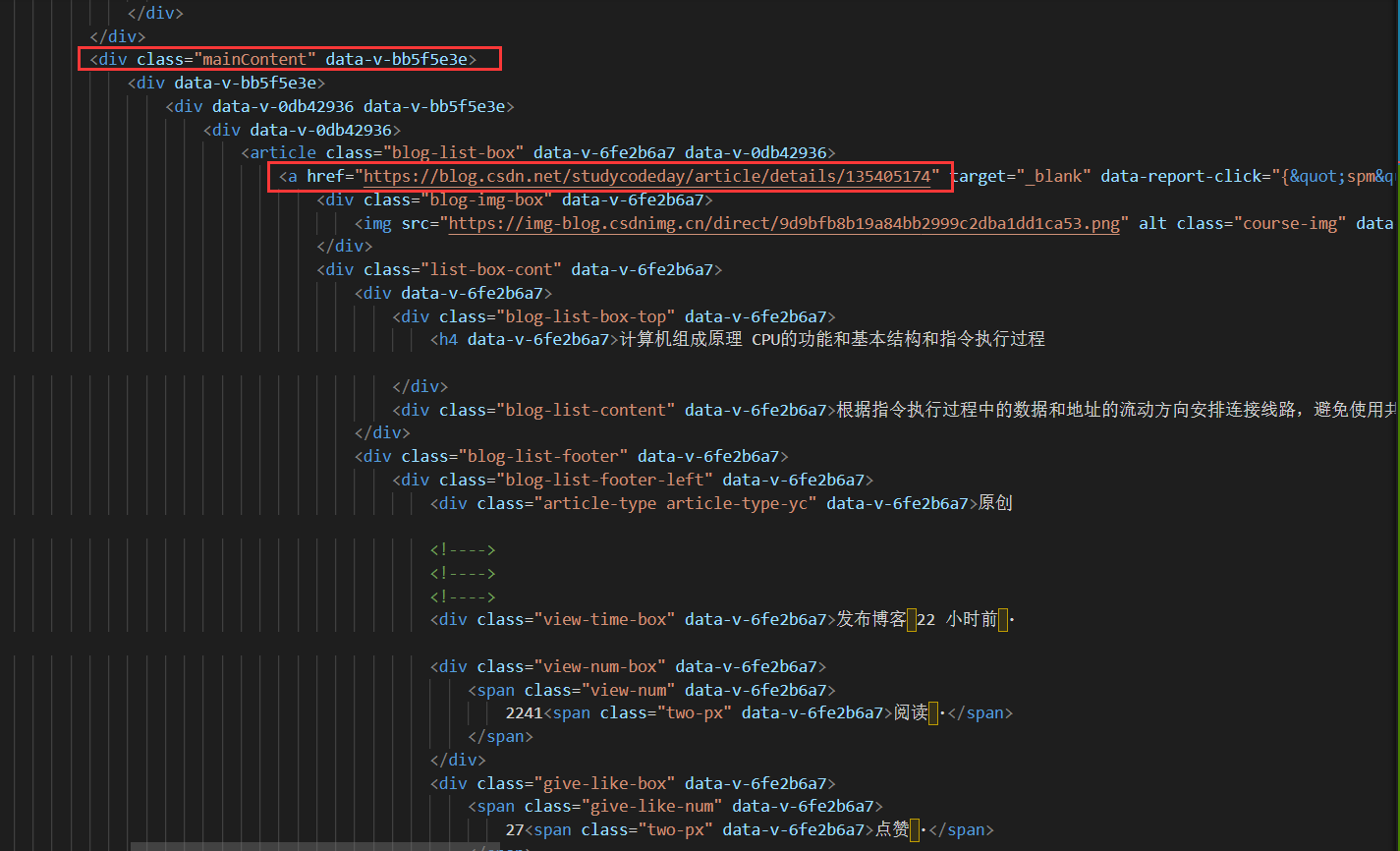
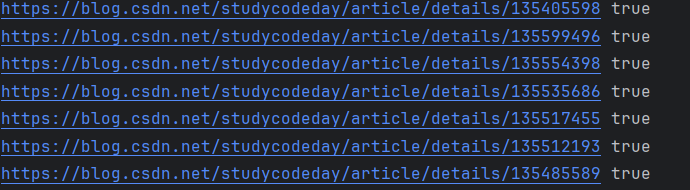
爬取

总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。