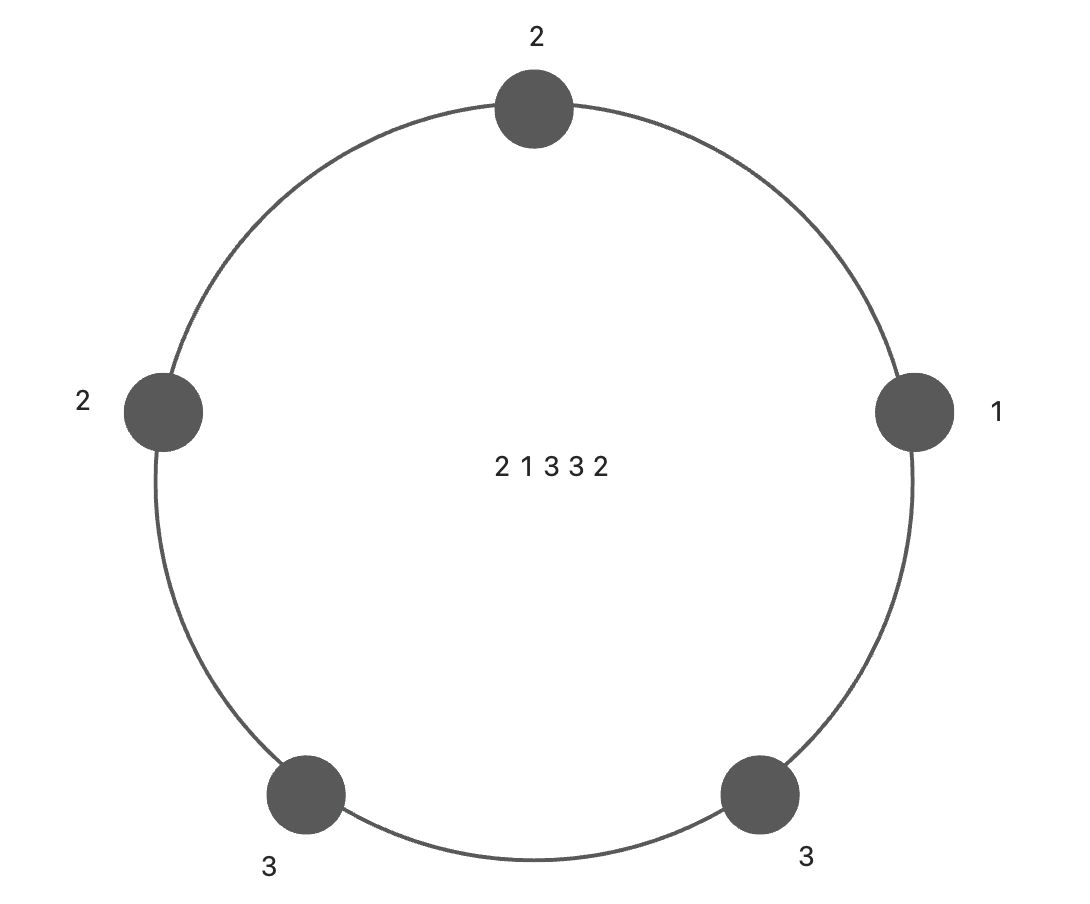
本文介绍: 我们直接用下面的例子简单最粗暴的理解:从形式上看,每个向量之间的内积为0,也就是每个向量是互相正交的,除了当前单词位置的值为1之外,其余位置的值都为0,。假设⽤ one-hot对句⼦进⾏表示,对句⼦分词之后,我们可以得到[‘我‘ , ’爱‘ , ’北京‘ , ’天安⻔‘],可以⽤one hot(独热编码)对单词进⾏编码。具体为:“我”可以表示为[1,0,0,0]”爱”可以表示为[0,1,0,0]’北京’可以表示为[0,0,1,0]’天安⻔’可以表示为[0,0,0,1]缺点。
前情提要:文本大量参照了以下的博客,本文创作的初衷是为了分享博主自己的学习和理解。对于刚开始接触NLP的同学来说,可以结合唐宇迪老师的B站视频【【NLP精华版教程】强推!不愧是的最完整的NLP教程和学习路线图从原理构成开始学,学完可实战!-哔哩哔哩】 https://b23.tv/WwVQnKr和【【唐博士带你学AI】NLP最著名的语言模型-BERT 10小时精讲,原理+源码+论文,计算机博士带你打通NLP-哔哩哔哩】 https://b23.tv/0ZtLcoj这两个视频使用Transformer通俗笔记:从Word2Vec、Seq2Seq逐步理解到GPT、BERT-CSDN博客
本文的大纲是:
目录
1.1.1 理解什么是one-hot representation
第一部分 单词向量化
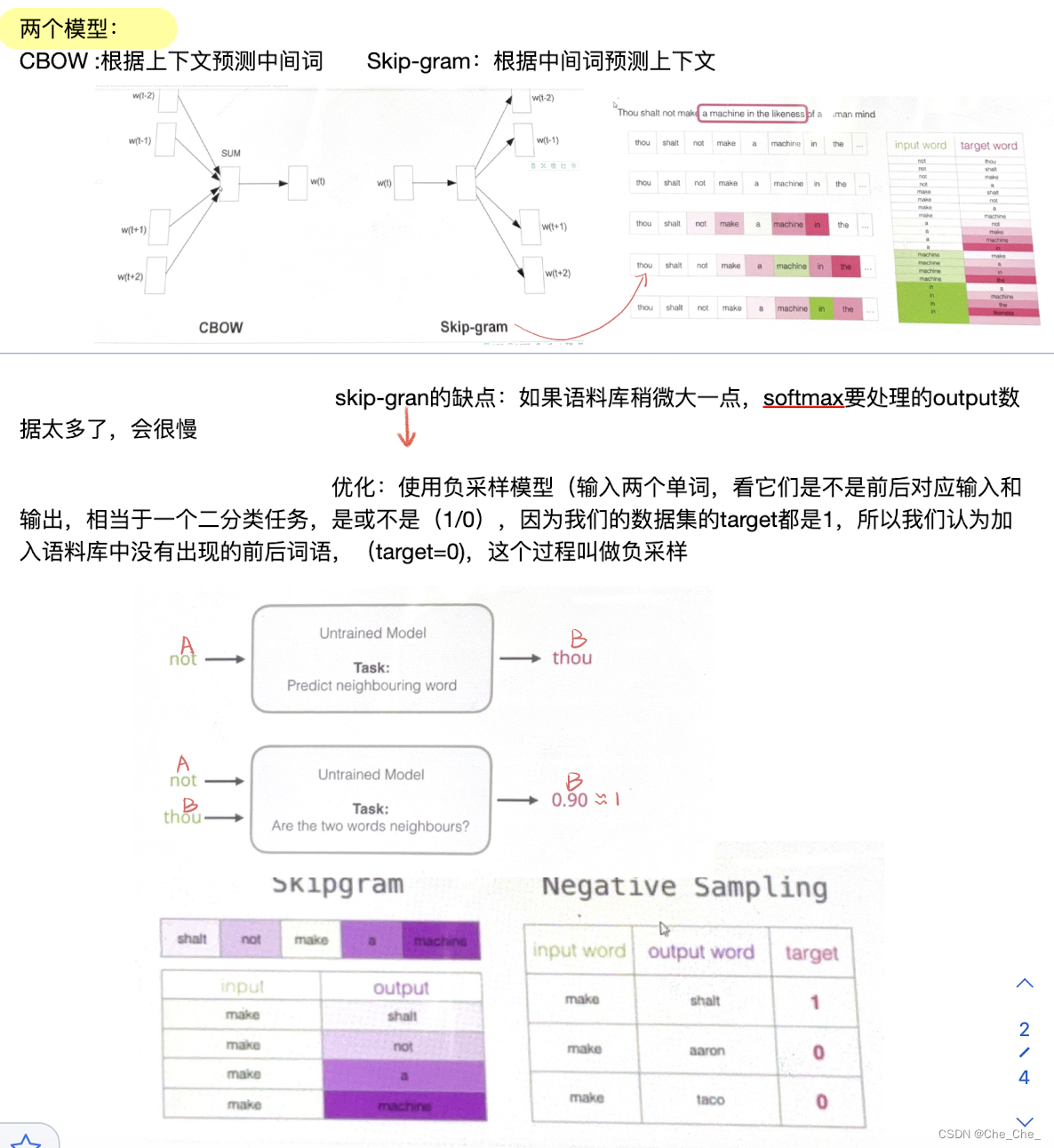
1.1 word embedding
1.1.1 理解什么是one-hot representation
1.1.2 理解什么是distribution representation
1.1.2.1我们现在提出一个比one-hot更高级的文本向量化要求:

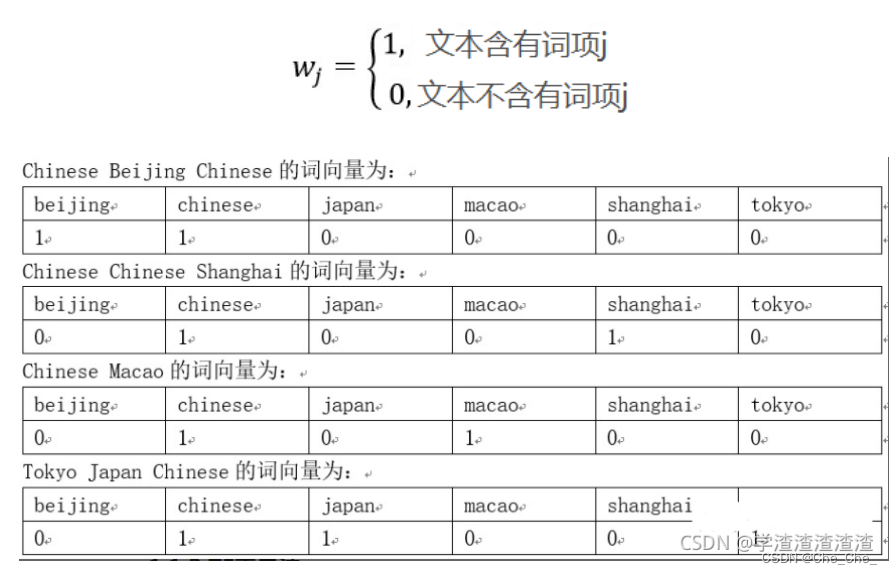


1.1.2.2 如何用distribution representation把单词变成一个跟单词上下文有关,有语义的向量呢?



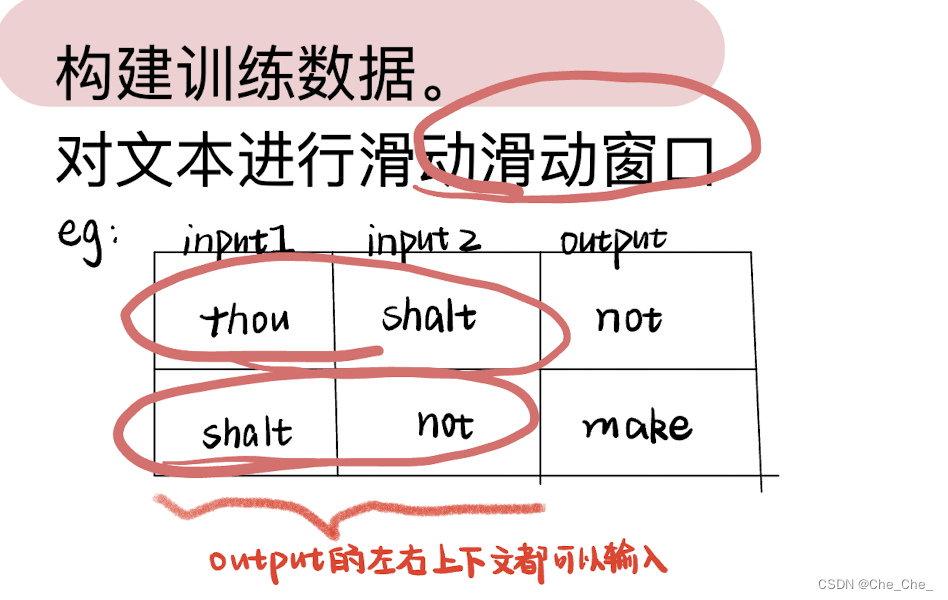

第二部分 从Seq2Seq序列引入Encoder-Decoder模型:RNN/LSTM与GRU
2.1 什么是Seq2Seq序列问题:输入一个序列 输出一个序列
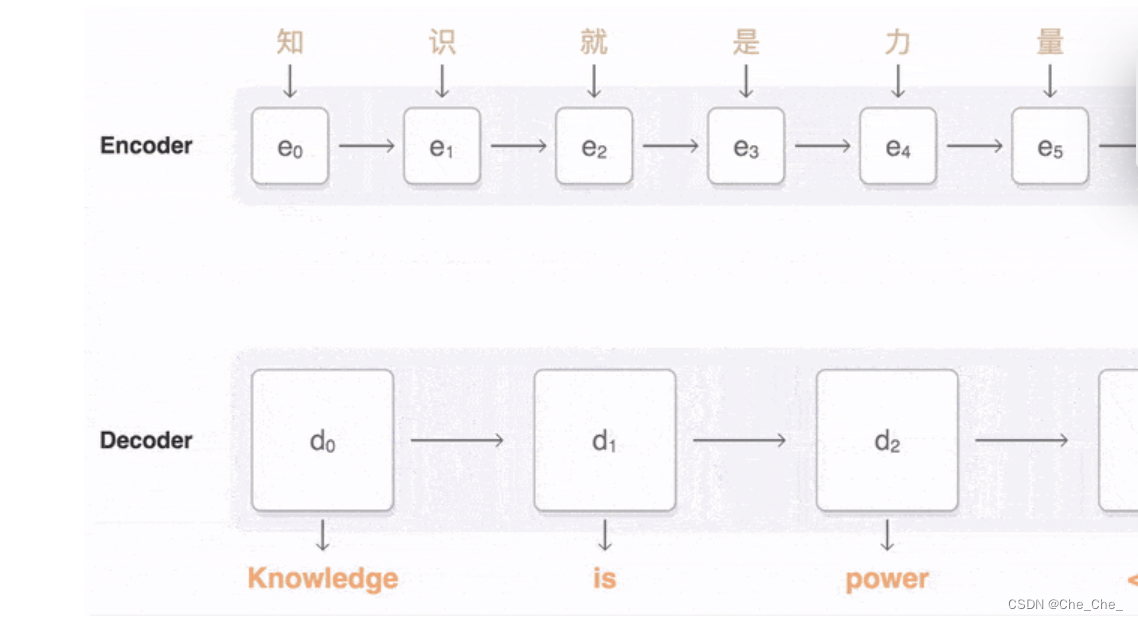
2.2 介绍Encoder-Decoder模型:RNN/LSTM与GRU
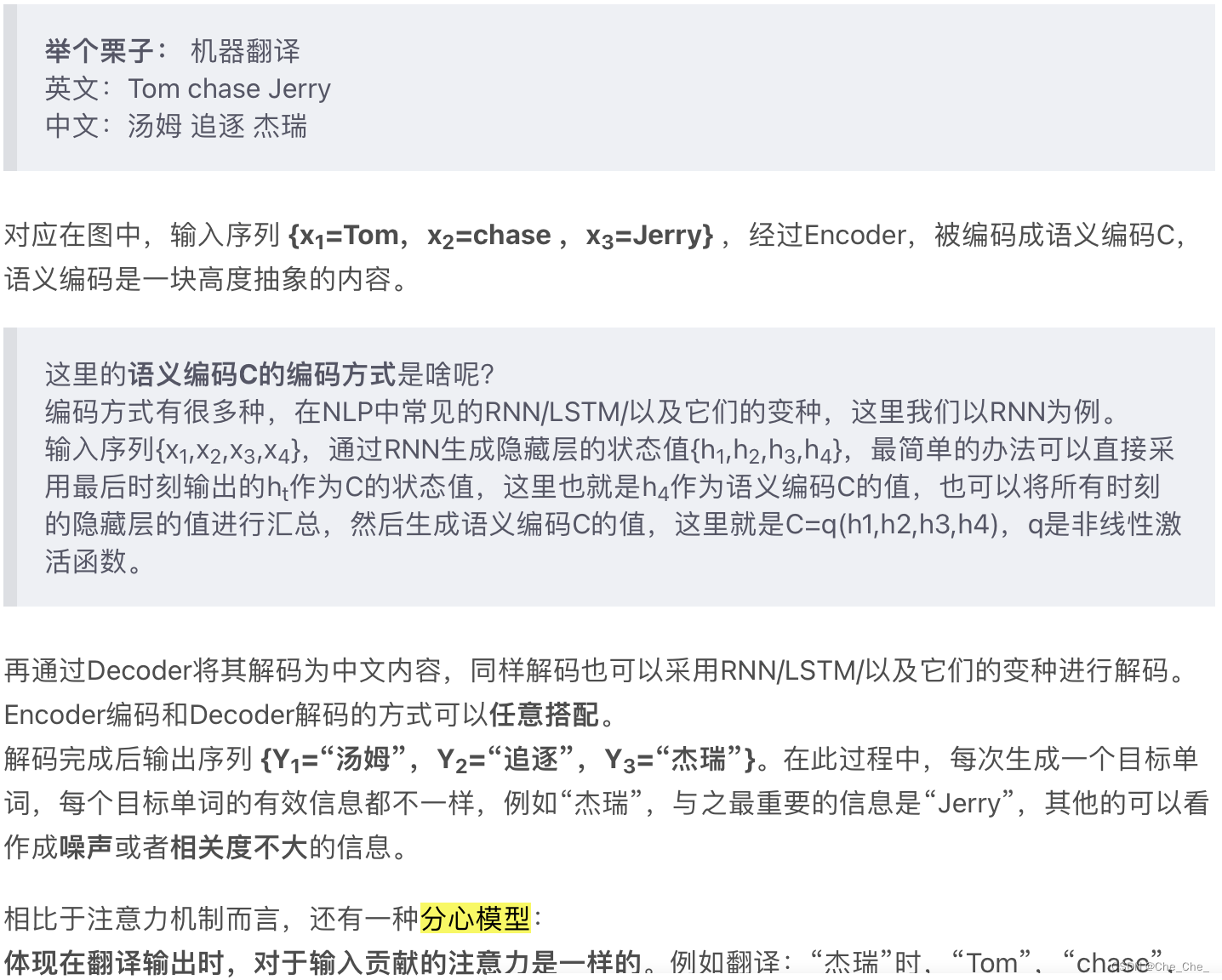
2.3 开始介绍注意力机制(Attention)





 」
」第三部分 transformer

3.1自注意力部分:
3.1.1 先来认识一下三个向量

3.1.2 attention整体流程

第三、四步:分数除以8然后softmax
3.2 多头注意力机制“multi-headed” attention
3.2.1 定义
3.2.2过程介绍



声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。