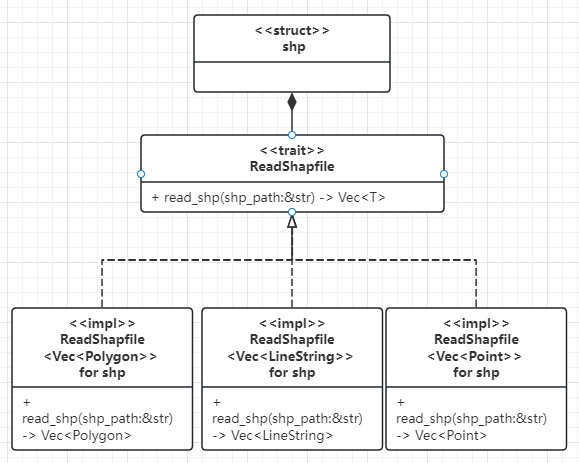
本文介绍: 首先定义了一个结构体,这个空结构体的作用类似于Java里面的class。然后定义了一个特性(trait),特性这个东西,在Rust中,类似于Java里面的接口,或者C++里面的虚函数,但是与接口和虚函数不同的时候,特性可以直接在里面写实现,也可以留空,如果你是学Java的,你把下面的代码理解为定义了一个接口,并且定义了一个实现接口的工厂方法即可。在这里的特性中,我们定义一个泛型T,然后定义了一个方法,就叫做read_shp,输入产生就是一个shapefile的路径,返回值是一个T。
本节已经涉及Rust学习曲线上的一个大坑:泛型和特性了,属于语言的深水区,如果初学者,建议看一眼知道有这个功能即可。
如果我们立足于功能实现,那么做到像上一节那样就可以了,从原理上来说,每个函数满足唯一的功能,是一种好的设计,软件工程里面“高内聚低耦合”是有利于系统的独立性的。
但是在调用的时候,就需要有一点的心智了,例如我们要读取点线面三种不同的shapefile,就要记住三种不同的函数名和三种不同的绘图要素构建程序,那也太麻烦了,有没有一种方法,让我们调用一种方法,根据不同的参数类型自动适配不同的处理逻辑呢?
如果你是学Python/Java/JavaScript这样的高级语言的同学,你肯定已经有了自己的实现方法,例如Python/Javascript作为动态类型的语言,可以只写一个入口函数,然后根据函数的输入参数自动去选择不同的分支来处理。
而Java也有同名方法覆盖,利用不同的函数签名(参数类型)来解决用同名函数实现不同的逻辑流程。
而C++则是可以用泛型和函数重载来实现这个功能。
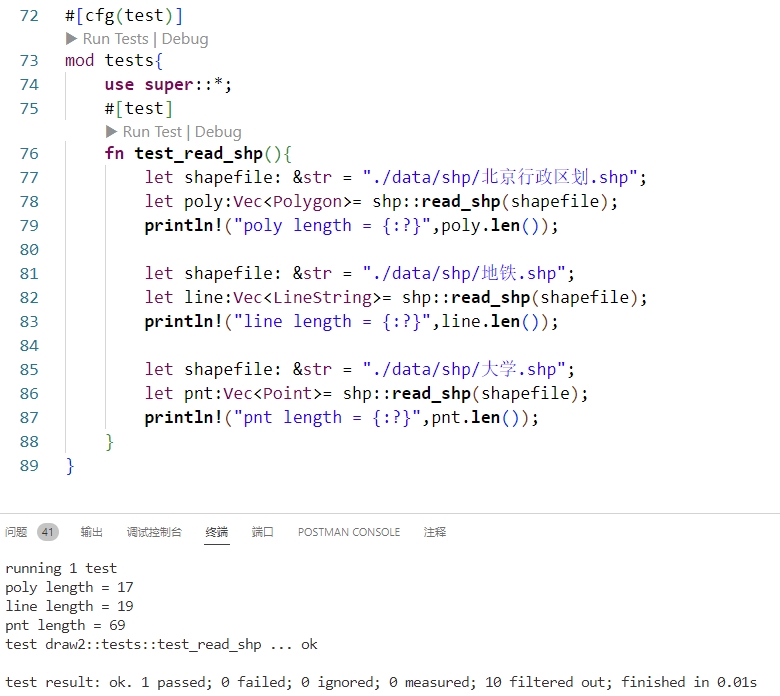
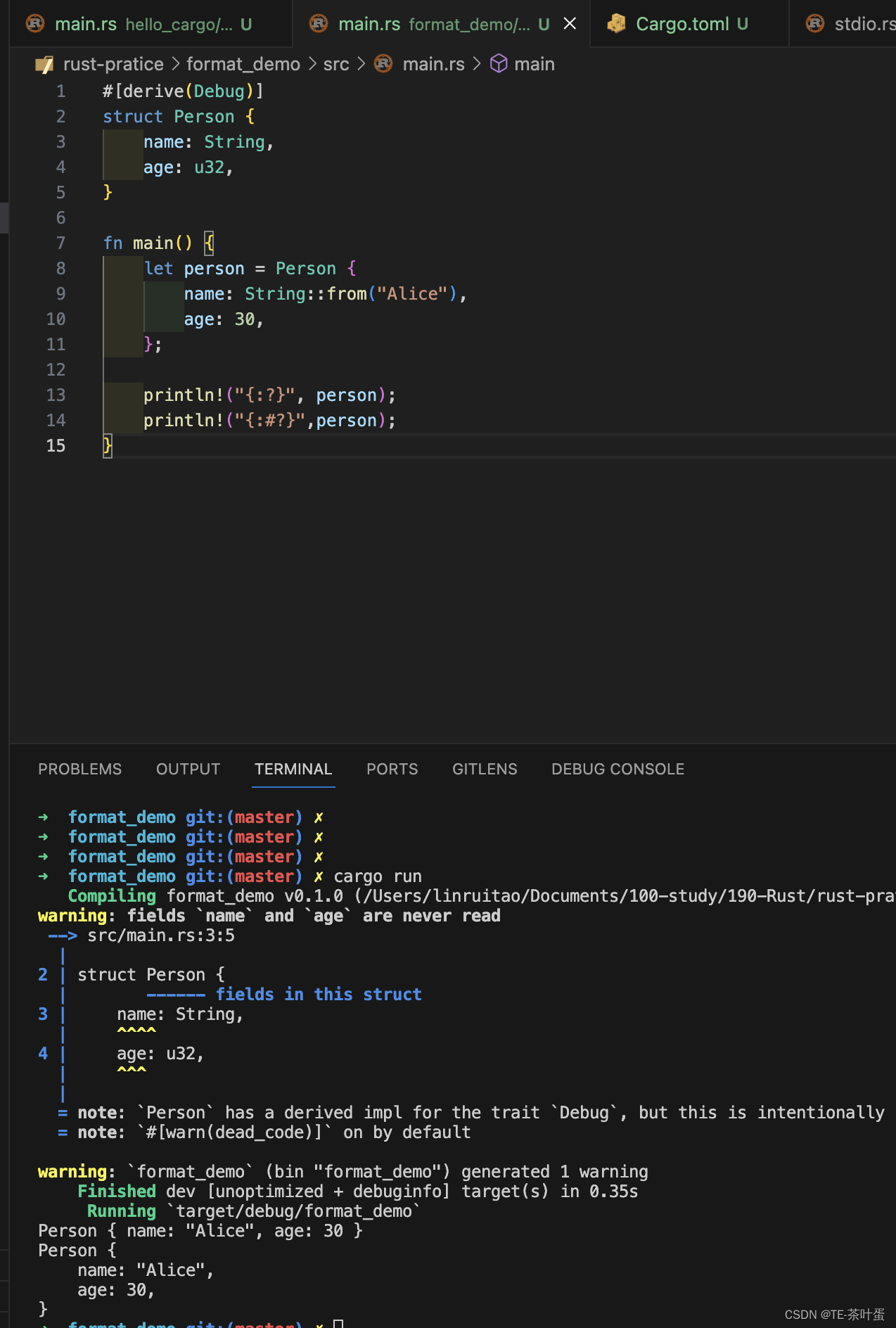
架构定义


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。