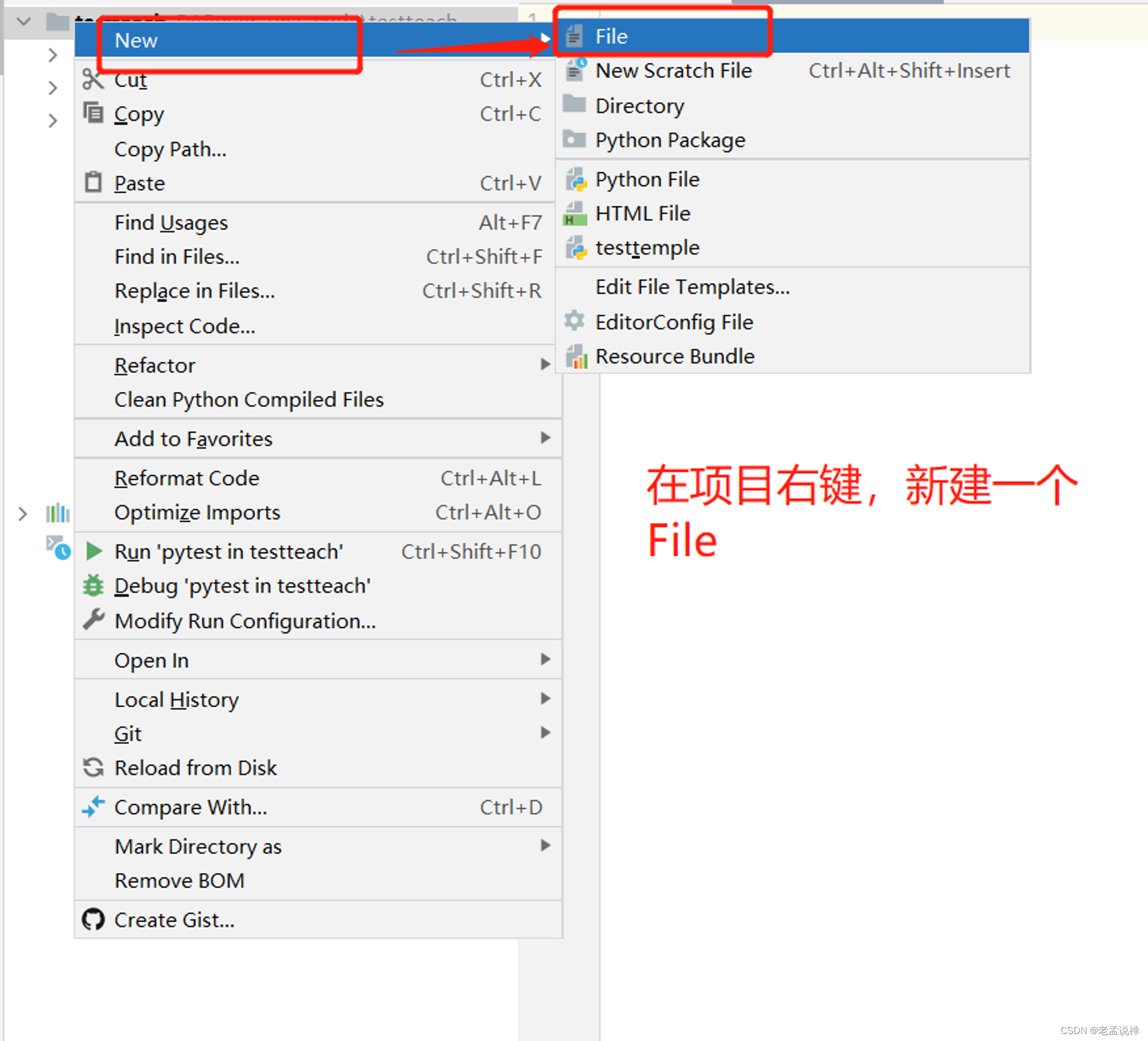
本文介绍: 根据命名法的解析程度和特定角色,包含分类单元用法名称(学名)的字符串由不同部分组成。因此,带有名称的字符串可以分解成这些部分,同时部分的数量可能表明了分类等级。该方法是 strsplit() 的包装器,如果在参数【repaste】中指明的话,还可以重新粘贴名称组分。Arguments参数【x】:一个包含分类名称的字符向量。参数【split,fixed,…】:传递给 strsplit() 的参数。参数【repaste】:一个整数向量,指示输出的名称的组分。一个字符矩阵,在输入向量中具有与名称相同
Description
根据命名法的解析程度和特定角色,包含分类单元用法名称(学名)的字符串由不同部分组成。
因此,带有名称的字符串可以分解成这些部分,同时部分的数量可能表明了分类等级。
该方法是 strsplit() 的包装器,如果在参数【repaste】中指明的话,还可以重新粘贴名称组分。
Usage
Arguments
参数【x】:一个包含分类名称的字符向量。
参数【split,fixed,…】:传递给 strsplit() 的参数。
参数【repaste】:一个整数向量,指示输出的名称的组分。
Value
Examples
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。