本文介绍: 在本次基线测试中,我们以金融场景中所遇到四类实际业务问题和数据入手进行对比实验,包括金融类短讯类型分类任务、金融文本行业分类、金融情绪分析任务以及金融类实体识别任务。对比 FinBERT 和 Google 原生中文BERT、 BERT-wwm、RoBERTa-wwm-ext 这三种通用领域的预训练模型可知,FinBERT效果提升显著,在 F1-score 上平均可以提升2~5.7个百分点。
FinBERT是熵简科技 AI Lab 开源的基于 BERT 架构的金融领域预训练语言模型,相比于Google发布的原生中文BERT、哈工大讯飞实验室开源的BERT-wwm 以及 RoBERTa-wwm-ext该模型在多个金融领域的下游任务中获得了显著的性能提升,在不加任何额外调整的情况下,F1-score 直接提升至少 2~5.7 个百分点。
论文地址:FinBERT: A Pre-trained Financial Language Representation Model for Financial Text Mining
github地址:https://github.com/valuesimplex/FinBERT
FinBERT-Base模型下载地址:FinBERT_L-12_H-768_A-12_pytorch.zip
论文的主要贡献:
一,FinBERT (BERT for Financial Text Mining)是第一个通过在金融语料上使用多任务学习得到的特定领域的BERT,其可以把金融领域语料上的知识传递到下游金融文本相关的应用任务上;
二,FinBERT和标准BERT采用不同的训练目标函数。本文设计或采用了6中自监督预训练任务,可以通过多任务自监督学习方法来训练,从而更有效地捕捉大规模预训练语料中的语言知识和语义信息;
模型及预训练方式
模型结构
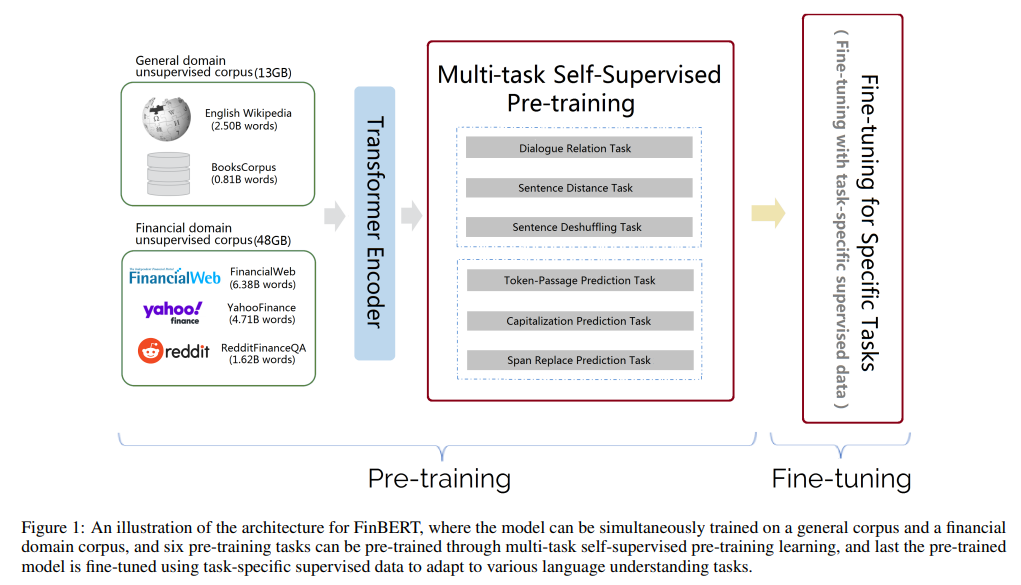
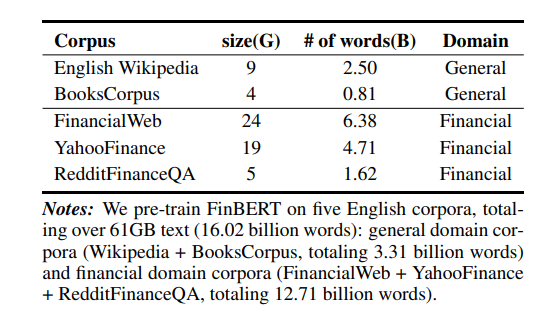
训练语料
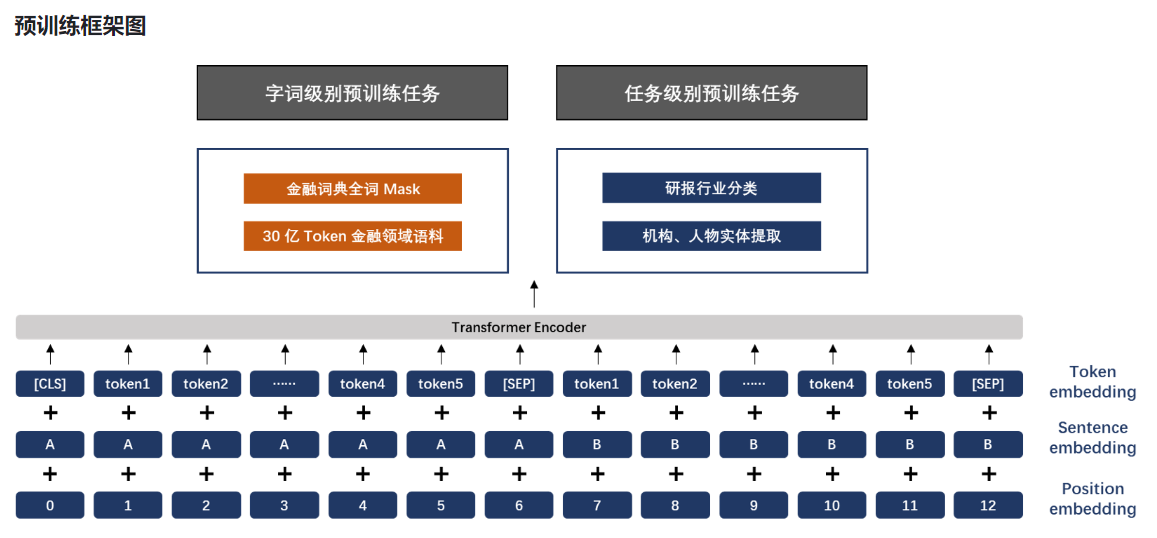
预训练方式
下游任务实验结果
实验一:金融短讯类型分类
实验任务
数据集
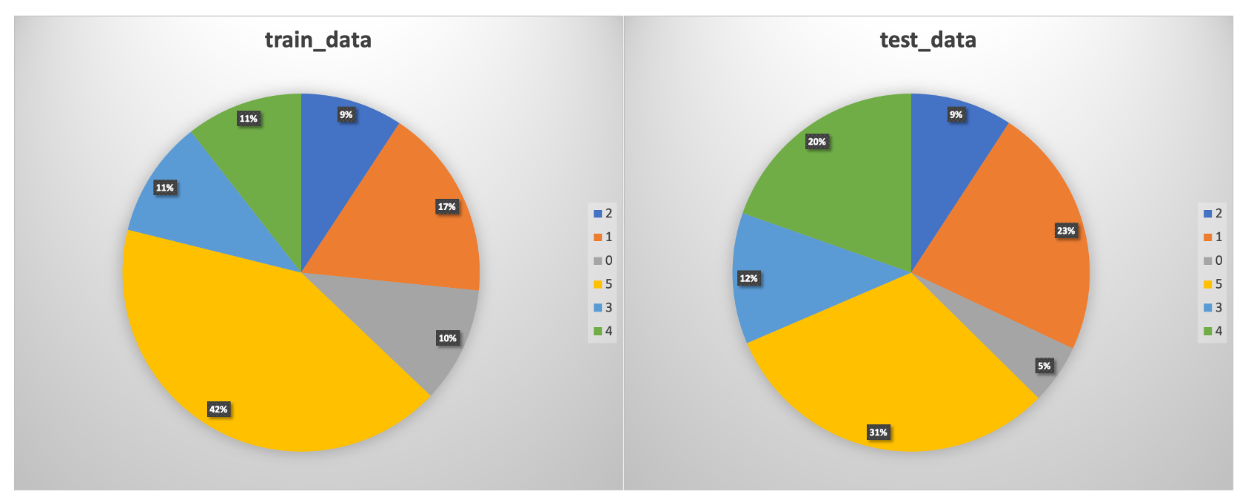
实验结果
实验二:金融短讯行业分类
实验任务
数据集
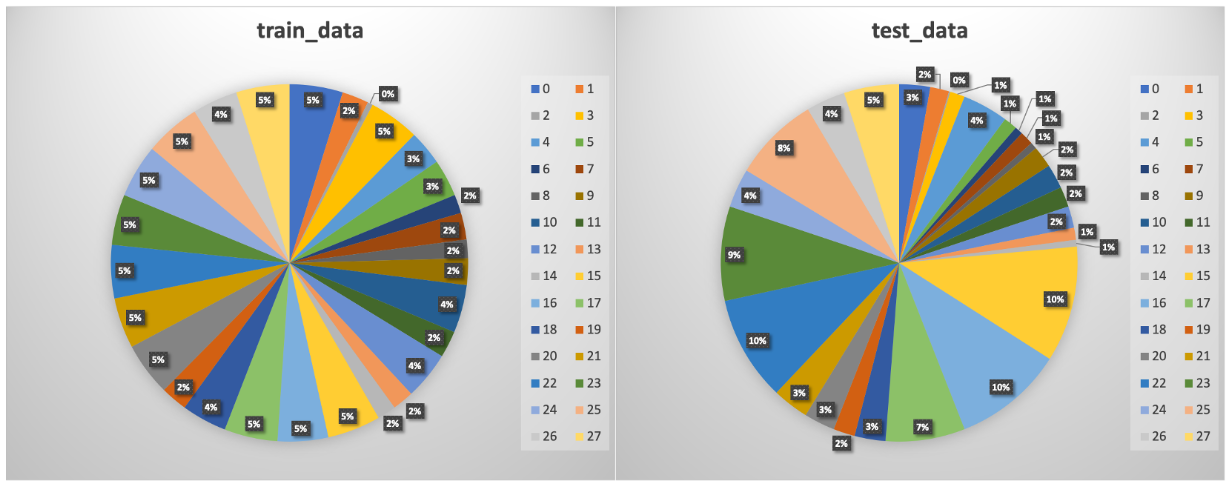
实验结果
实验三:金融情绪分类
实验任务
数据集
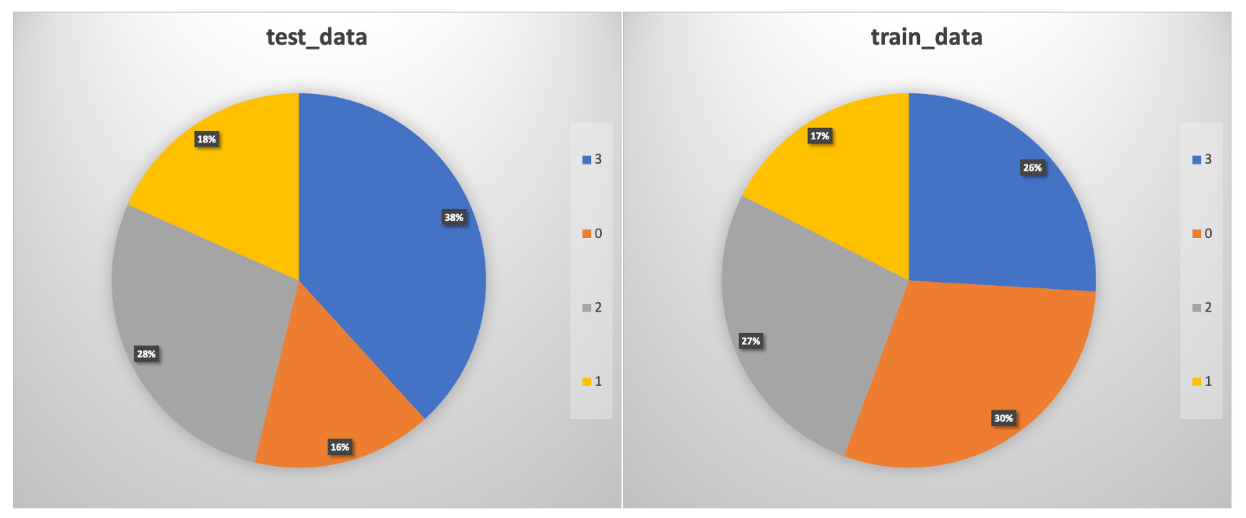
实验结果
实验四:金融领域的命名实体识别
实验任务
数据集
结果展示
总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。