本文介绍: 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka、Pulsar 等。
一、Kafka 概述
1.1 为什么需要消息队列(MQ)
主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka、Pulsar 等。
1.2 使用消息队列的好处
(1)解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
(2)可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
(3)缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
(4)灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
1.3 消息队列的两种模式
1.4 Kafka 定义
1.5 Kafka 简介
1.6 Kafka 的特性
1.7 Kafka 系统架构
1.8 分区的原因
二、部署 kafka 集群
1.下载安装包
2.安装 Kafka
3. 修改配置文件
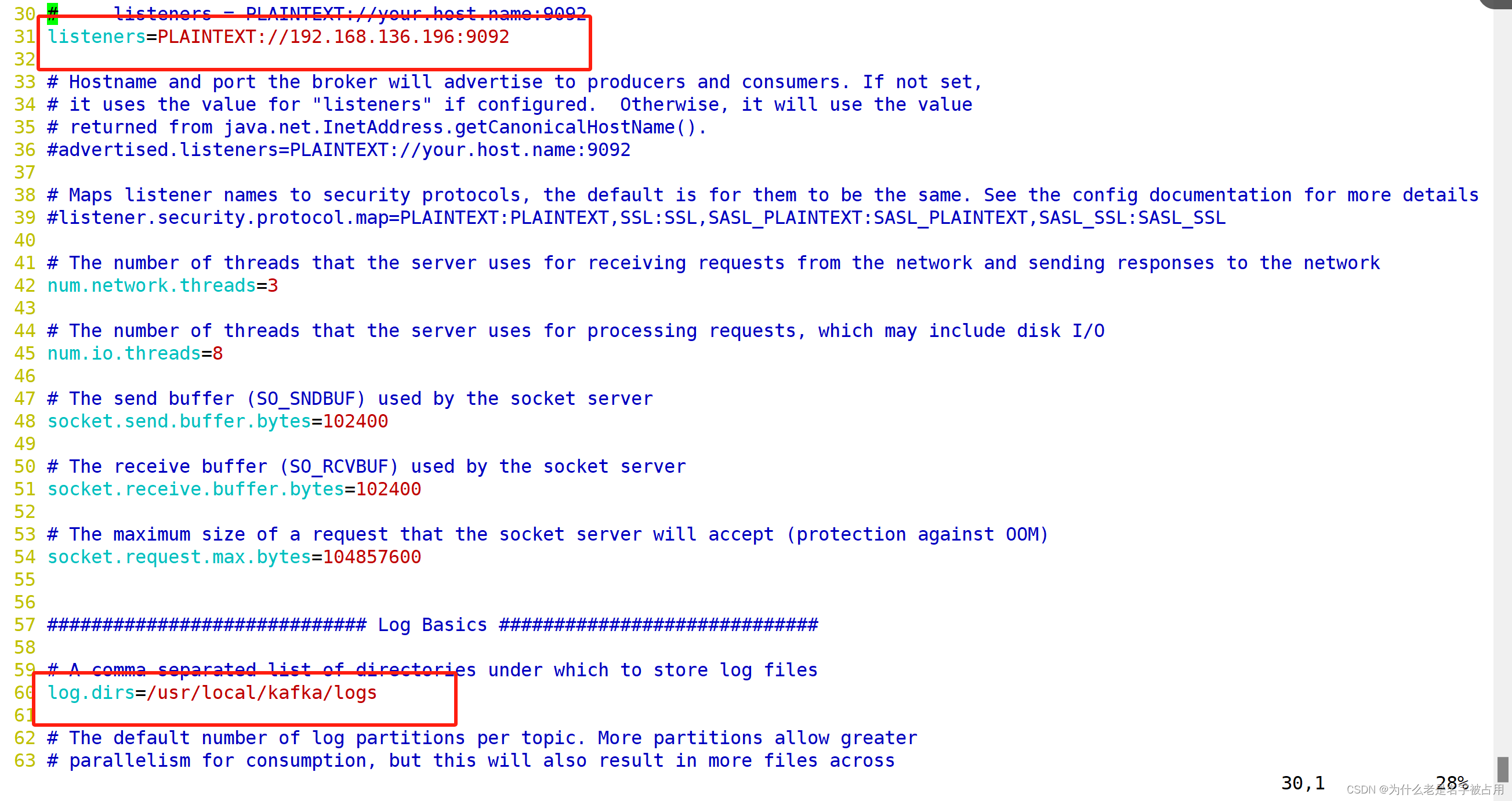



4. 修改环境变量

5. 配置 Zookeeper 启动脚本
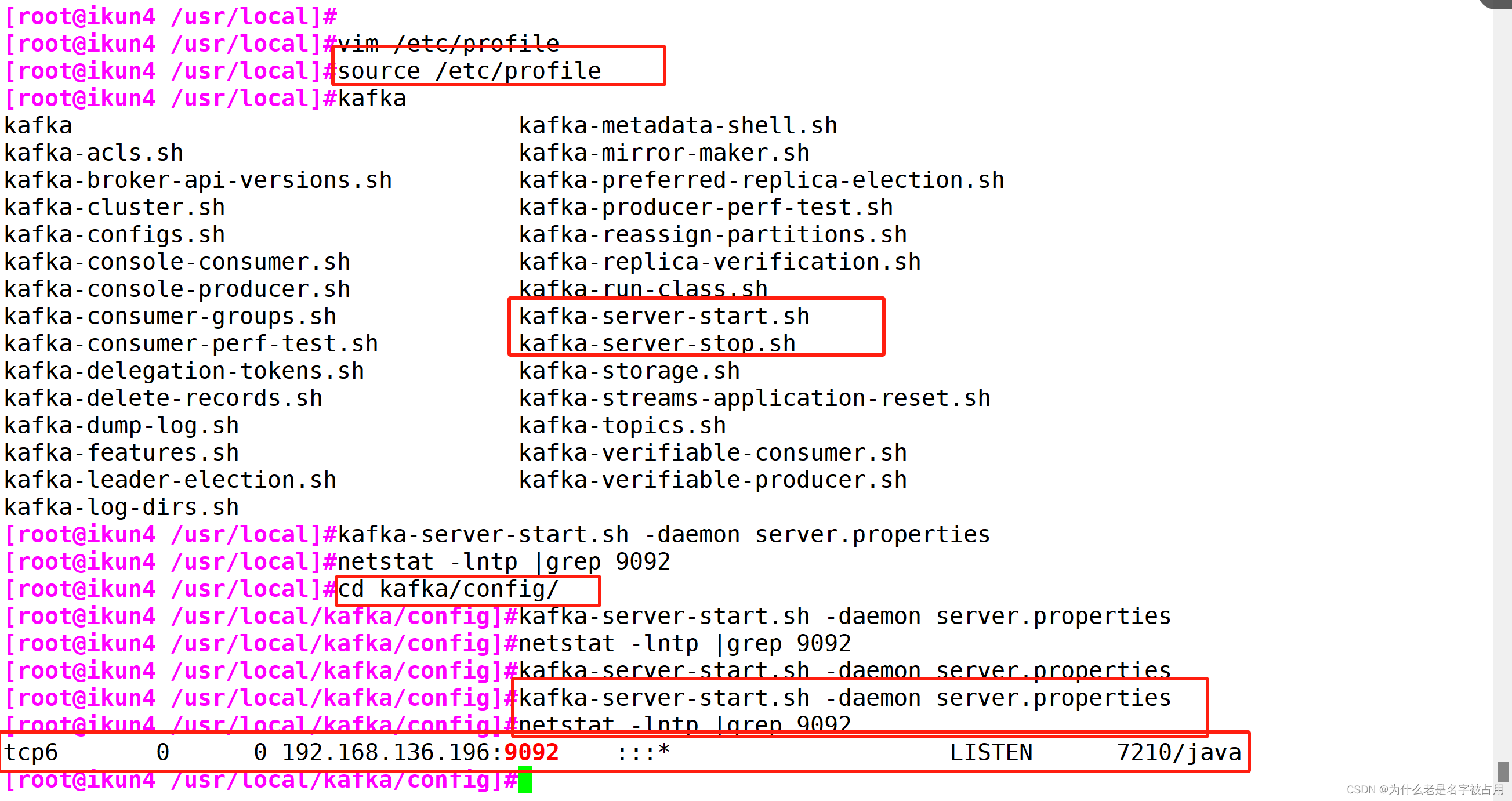
6. Kafka 命令行操作
创建topic

查看当前服务器中的所有 topic

查看某个 topic 的详情

发布消息

消费消息
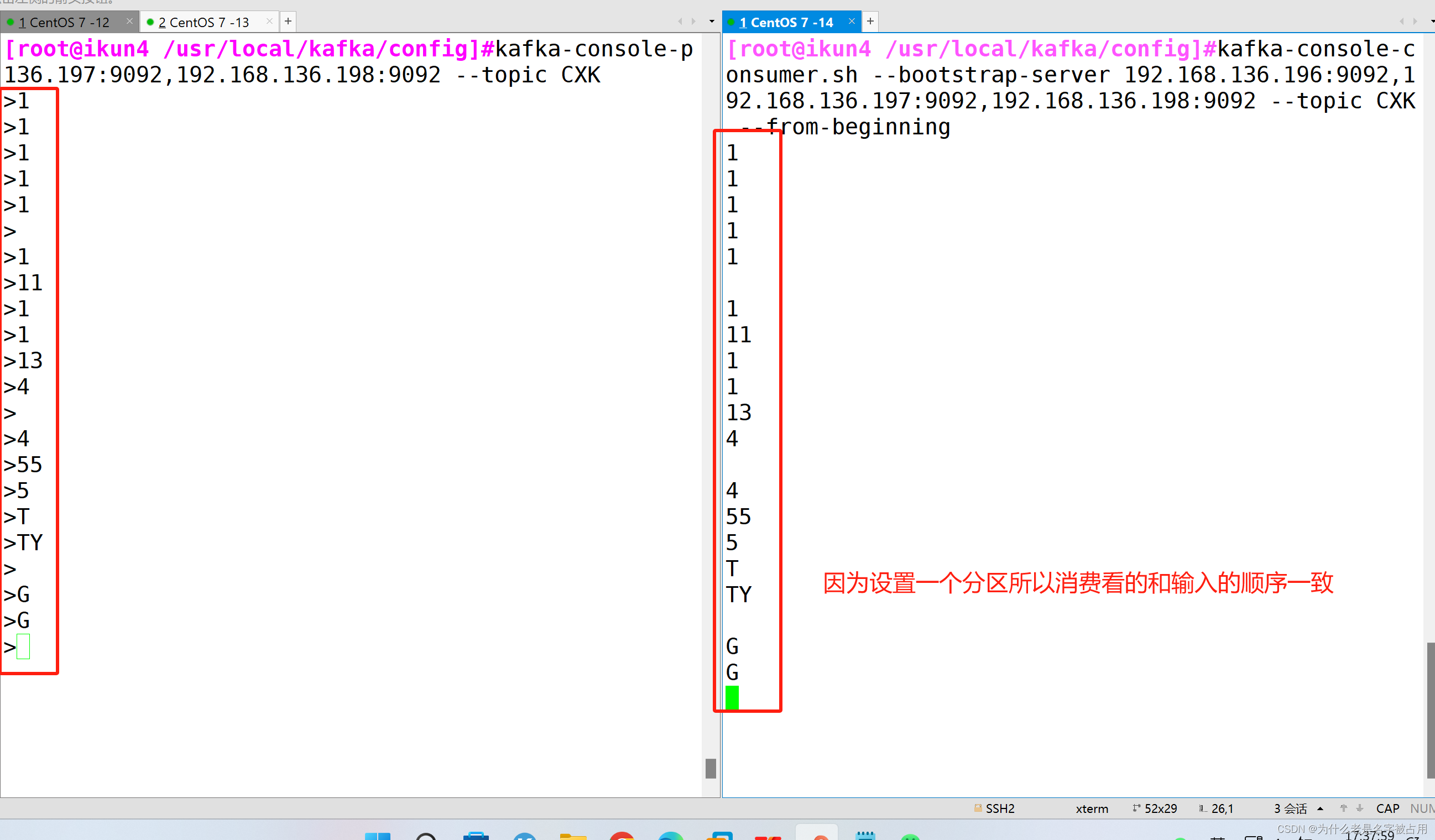
修改分区数


删除 topic

三、Filebeat+Kafka+ELK
1.部署 Zookeeper+Kafka 集群
2.部署 Filebeat


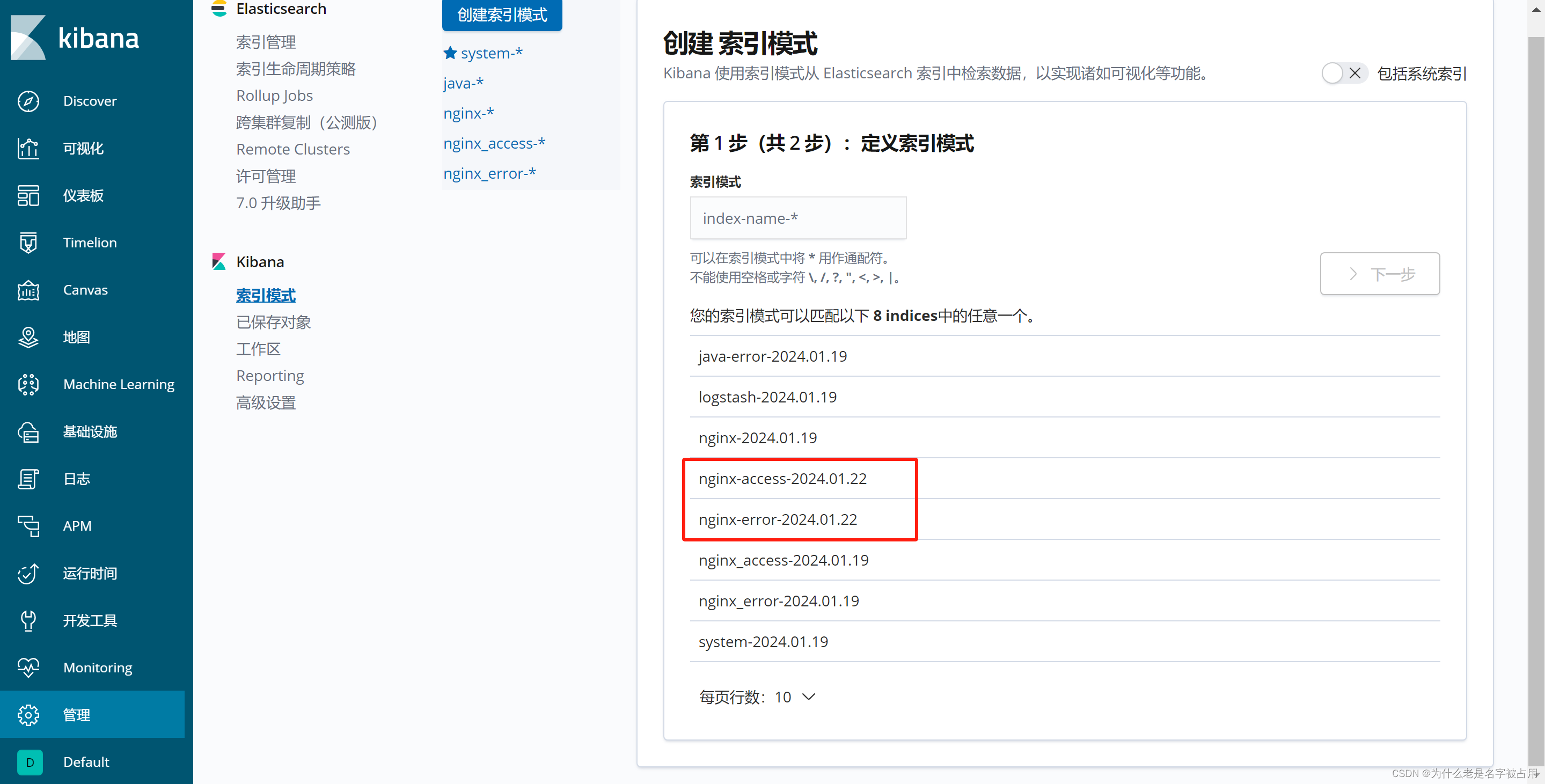
3.部署 ELK,在 Logstash 组件所在节点上新建一个 Logstash 配置文件

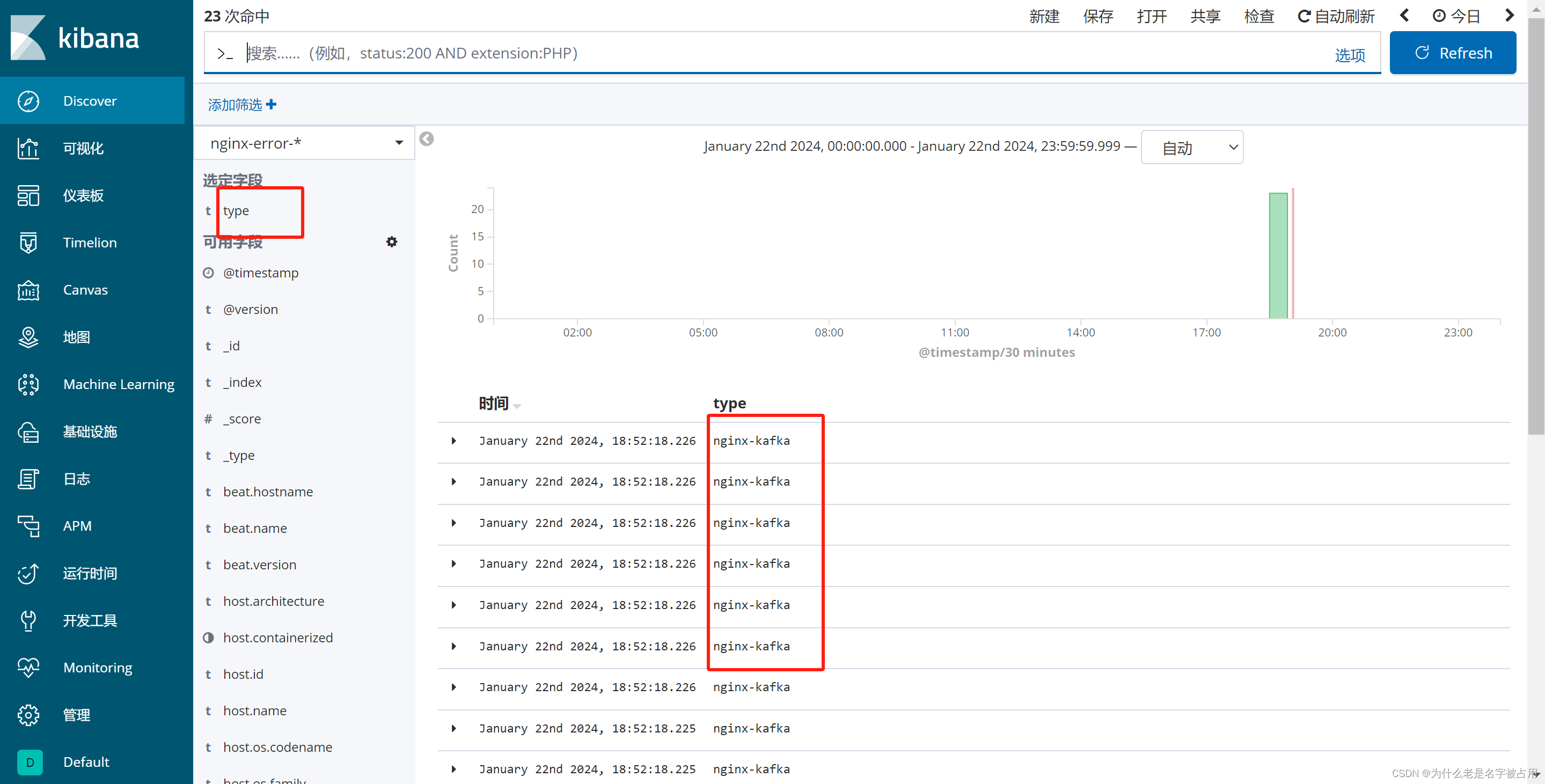
4.浏览器访问





声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

![[设计模式Java实现附plantuml源码~行为型]请求的链式处理——职责链模式](https://img-blog.csdnimg.cn/direct/699aac3ed0c446d088772a0ed4c444ed.png)




