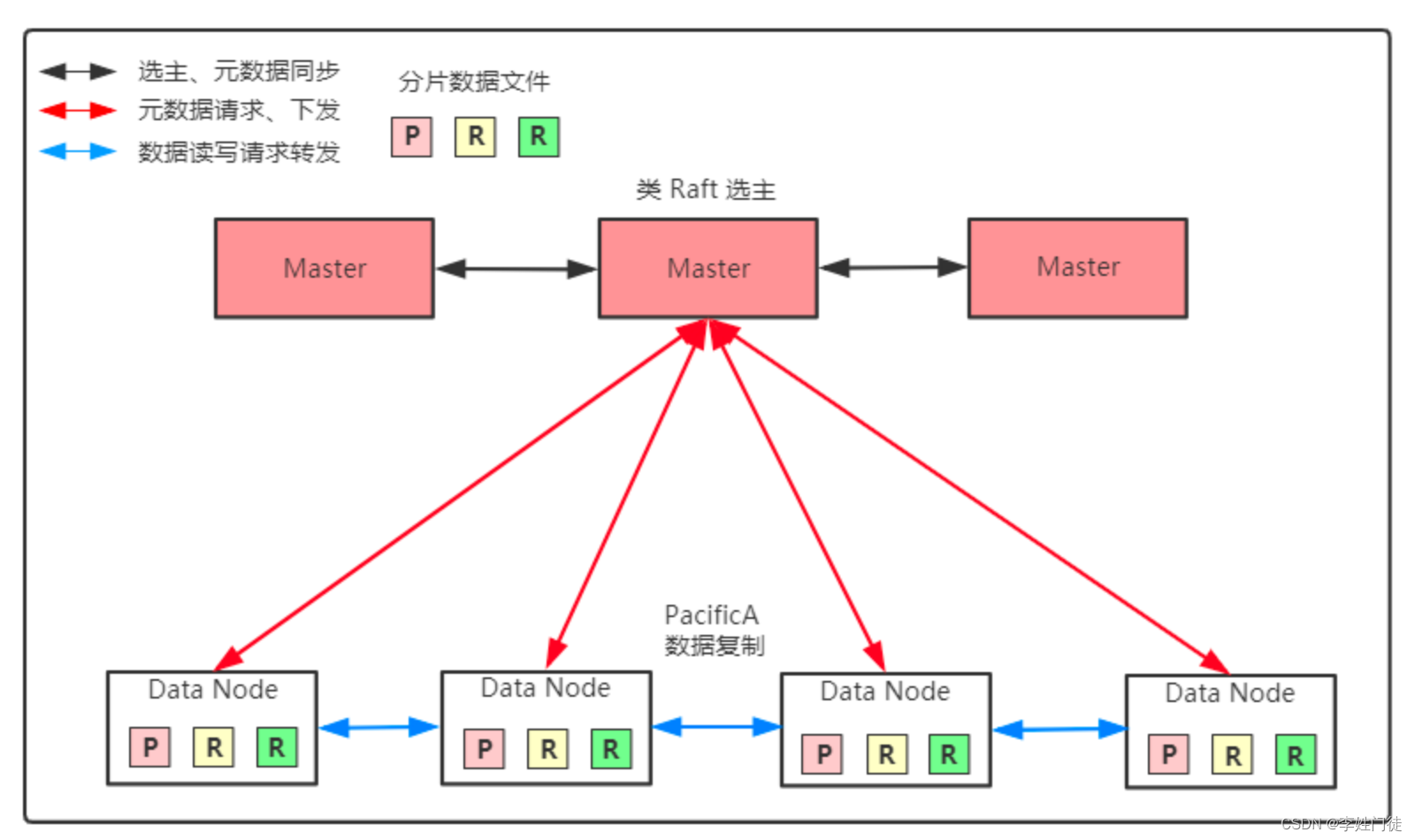
本文介绍: 浅分页适合用于小于10000数据集的业务场景属于通过业务解决es深度分页问题的方式(类似百度就是这样的),浅分页支持随机跳转分页的业务场景。from:未指定是0 代表数据的起始值size:未知的是10 代表返回数据条数es定义大于10000条的分页(默认)因为性能过差是禁止查询的,所以称为浅分页。具体的数量可以通过参数max_result_window设置。
elasticsearch高级应用
1.es的深度分页问题
1.浅分页from/size
浅分页适合用于小于10000数据集的业务场景属于通过业务解决es深度分页问题的方式(类似百度就是这样的),浅分页支持随机跳转分页的业务场景。
from:未指定是0 代表数据的起始值
size:未知的是10 代表返回数据条数
es定义大于10000条的分页(默认)因为性能过差是禁止查询的,所以称为浅分页。具体的数量可以通过参数max_result_window设置。
因为es集群是分片存储的同一个索引不同的数据存储在不同的分片上,所以浅分页查询的时候是类似shardingjdbc的直接查询每一个分片上所有的分页数数据并排序(query m+n)汇总到协调节点再做聚合排序(fetch)。比如from 1000 ,size 10,有3个es主分片。要查询每个分片节点的0到1010条数据,然后协调节点拿到全部分片的3030条数据再做全局排序取到前10个,这样查询的性能很差有资源浪费,深度翻页的时候数据量越大越慢。
2.深度分页scroll遍历查询
游标查询,非实时的查询,query时候在内存中建立一个快照,查询时候设置文档排序,多久删除比如scroll = 1m 1分钟后删除,会返回一个scroll_id,下次根据scroll_id查询的时候会遍历这个快照。使用后推荐直接把指定scroll_id删除掉。
3.深度分页search_after
2.es的数据写入过程
1.写入原理
2.translog预写日志
3.es的数据存储
1.段
2.段合并
4.elk
1.elk概念
elk分别表示elasticsearch、logstash、kibana
2.elk能做什么
1.日志搜集
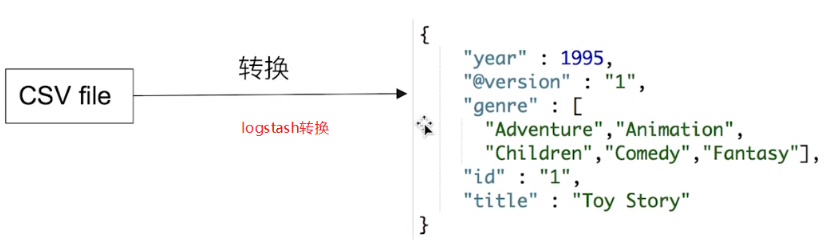
2.异构数据同步
1.canal
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。