本文介绍: 应用需求指源系统数据的入仓也需要考虑当前集市、数据应用系统的数据需求,因为数据需求是千变万化的,但是只要保留全面的基础的业务数据,就有了加工的基础,当前的数据需求只是考虑的一部分,更多的需要根据业务经验以及主题模型进行数据入仓和模型设计。(7)实时数据区:实时数据区需要使用部分批量数据来和实时流数据进行关联加工,因此可从主数据区获得所需要的数据后进行存放在实时数据区的关联数据区,同时对于加工结果不仅可以推送到KAFKA等消息中间件,同时也可输出到实时数据区的结果区进行保留。比如10年以上的数据进行删除。
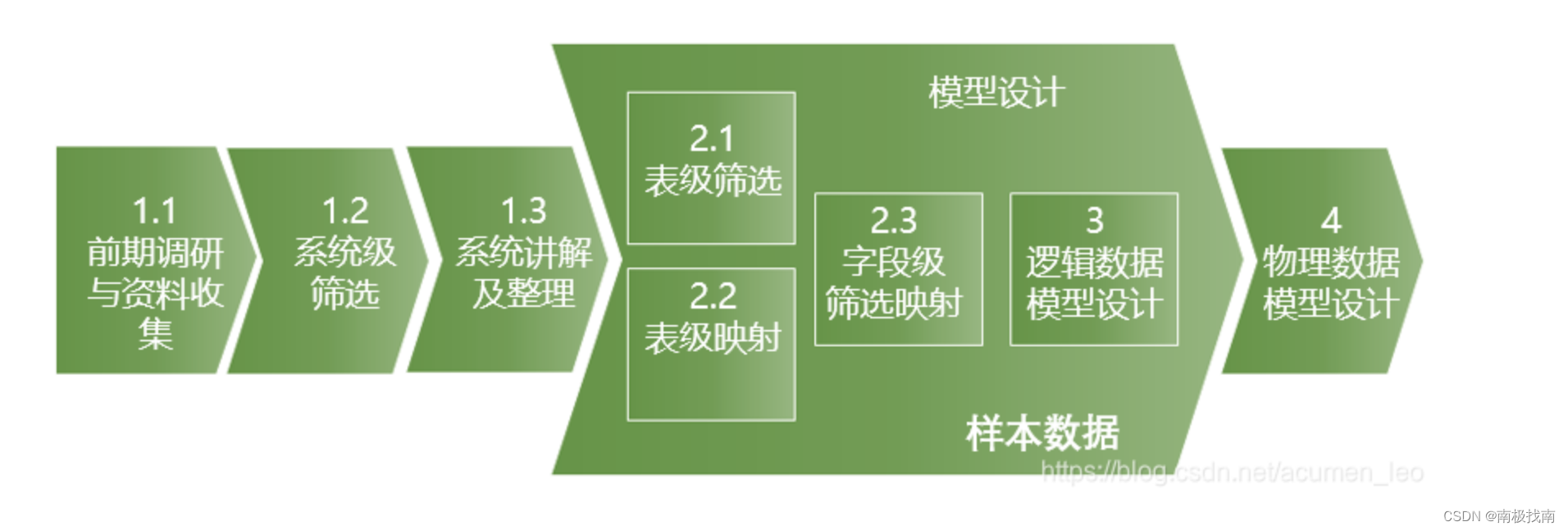
数据仓库作为全行或全公司的数据中心和总线,汇集了全行各系统以及外部数据,通过良好的系统架构可以保证系统稳定性和处理高效性,那如何保障系统数据的完备性、规范性和统一性呢?这里就需要有良好的数据分区和数据模型,那数据分区在第三部分数据架构中已经介绍,本节将介绍如何进行数据模型的设计。
1、各数据分区的模型设计思路:
数据架构部分中提到了在数据仓库中主要分为以下区域,那各数据区域的主要设计原则如下:

(1)主数据区:主数据区是全行最全的基础数据区,保留历史并作为整个数据仓库的数据主存储区,后续的数据都可以从主数据区数据加工获得,因此主数据区的数据天然就要保留所有历史数据轨迹。
1) 近源模型区:主要是将所有入数据仓库的数据表按历史拉链表或事件表(APPEND算法)的方式保留所有历史数据,因此模型设计较简单,只需要基于源系统表结构,对字段进行数据标准化后,增加保留历史数据算法所需要的日期字段即可。


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。







