本文介绍: 因为需要大量的数据去完善最后的参数,使得参数更加准确,因为乘法难解,所以可以加上对数转换成加法,而且转换后虽然L的数值改变了,但是我们要求取的是。这个公式就是对目标函数求偏导得出方向,因为梯度下降是沿这原来的反方向走,所以后面那个公式前面的符号改变成+号,表示在原来的初始位置。0是偏置项,在训练过程中为了使得训练结果更加精确而做的微调,不是一个大范围的因素,核心影响因素是权重项。0后面乘x0,使得满足矩阵的转换,所以在处理数据时候会添加如有上图所示的x0一列全是1的数据。的过程并没有一个学习的过程。
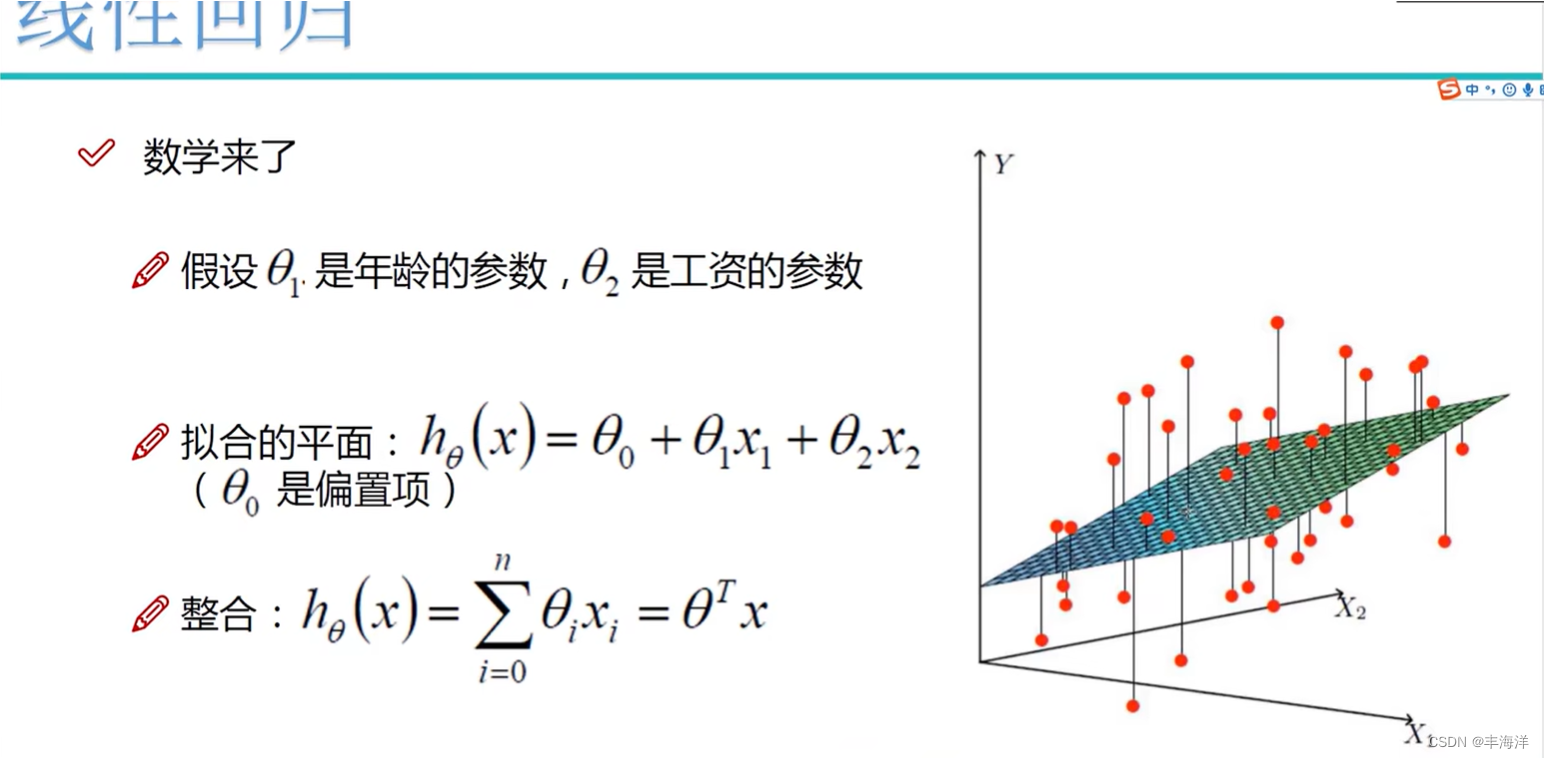

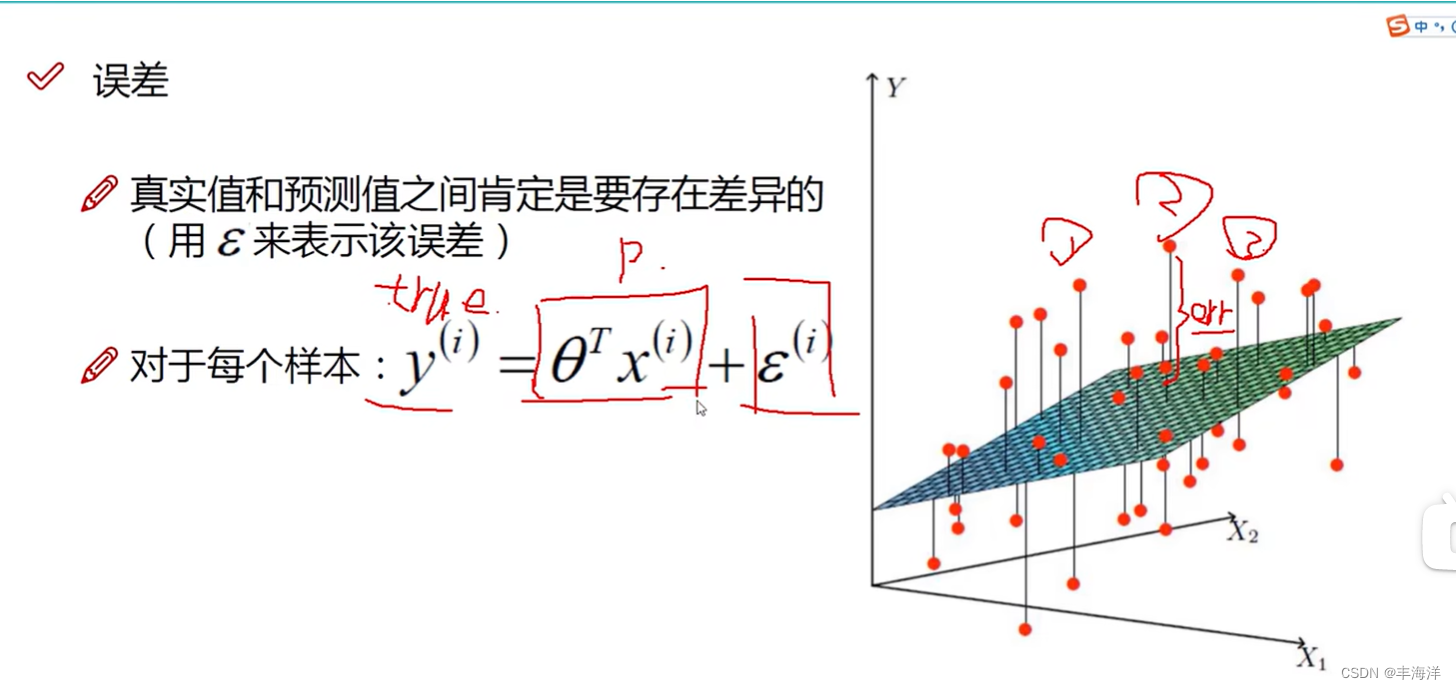









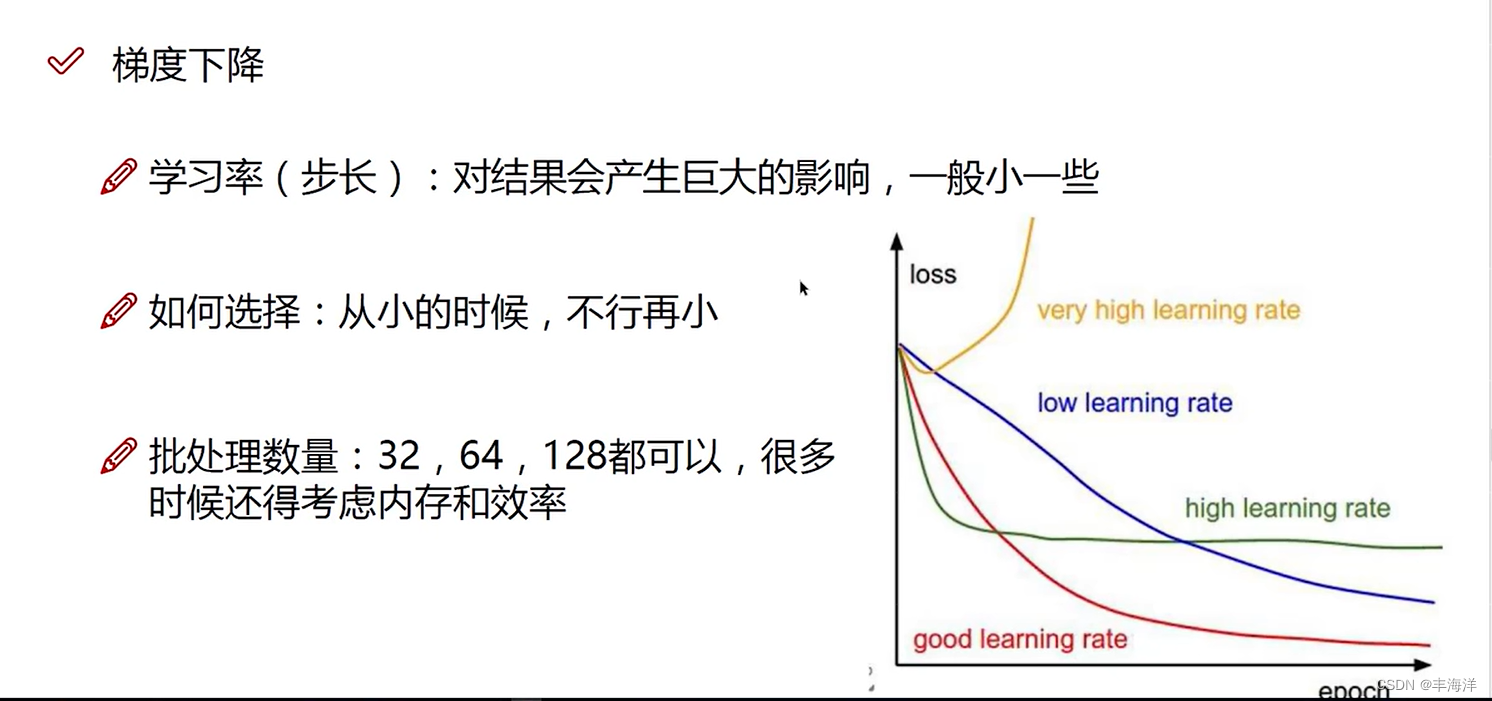
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)