本文介绍: 在C/C++中,变量,函数以及后面C++要学的:类都是大量存在的,这些变量函数和类都存在于全局作用域中,这样可能会导致很多冲突,也就是命名冲突。使用命名空间的目的就是对这些标志符也就是变量函数等名称进行本地化,以此来避免命名冲突或名字污染。于是namespace关键字就应运而生来针对解决这种问题。在定义一个新的命名空间的时候,使用关键字namespace加后面命名空间的名称,然后再接一对{}就可以了,{}里面就是命名空间的成员。缺省参数是声明或定义函数时为函数的参数指定一个缺省值。
一、命名空间
1.命名空间(namespace)的定义
在C/C++中,变量,函数以及后面C++要学的:类都是大量存在的,这些变量函数和类都存在于全局作用域中,这样可能会导致很多冲突,也就是命名冲突。使用命名空间的目的就是对这些标志符也就是变量函数等名称进行本地化,以此来避免命名冲突或名字污染。于是namespace关键字就应运而生来针对解决这种问题。
在定义一个新的命名空间的时候,使用关键字namespace加后面命名空间的名称,然后再接一对{}就可以了,{}里面就是命名空间的成员。
(1)命名空间的格式:
(2)命名空间可以嵌套
(3)可以有多个命名空间
一个程序中可以有多个命运空间不会冲突,当编译器运行时,会将两个命令空间的内容合并到一起。
注意:
2.域 以及 编译器的搜索原则
对于全局域和局部域来说,他们不仅影响生命周期,还影响访问。
但是命名空间域只影响访问,最初的变量是什么,在namespace之后生命周期不变。
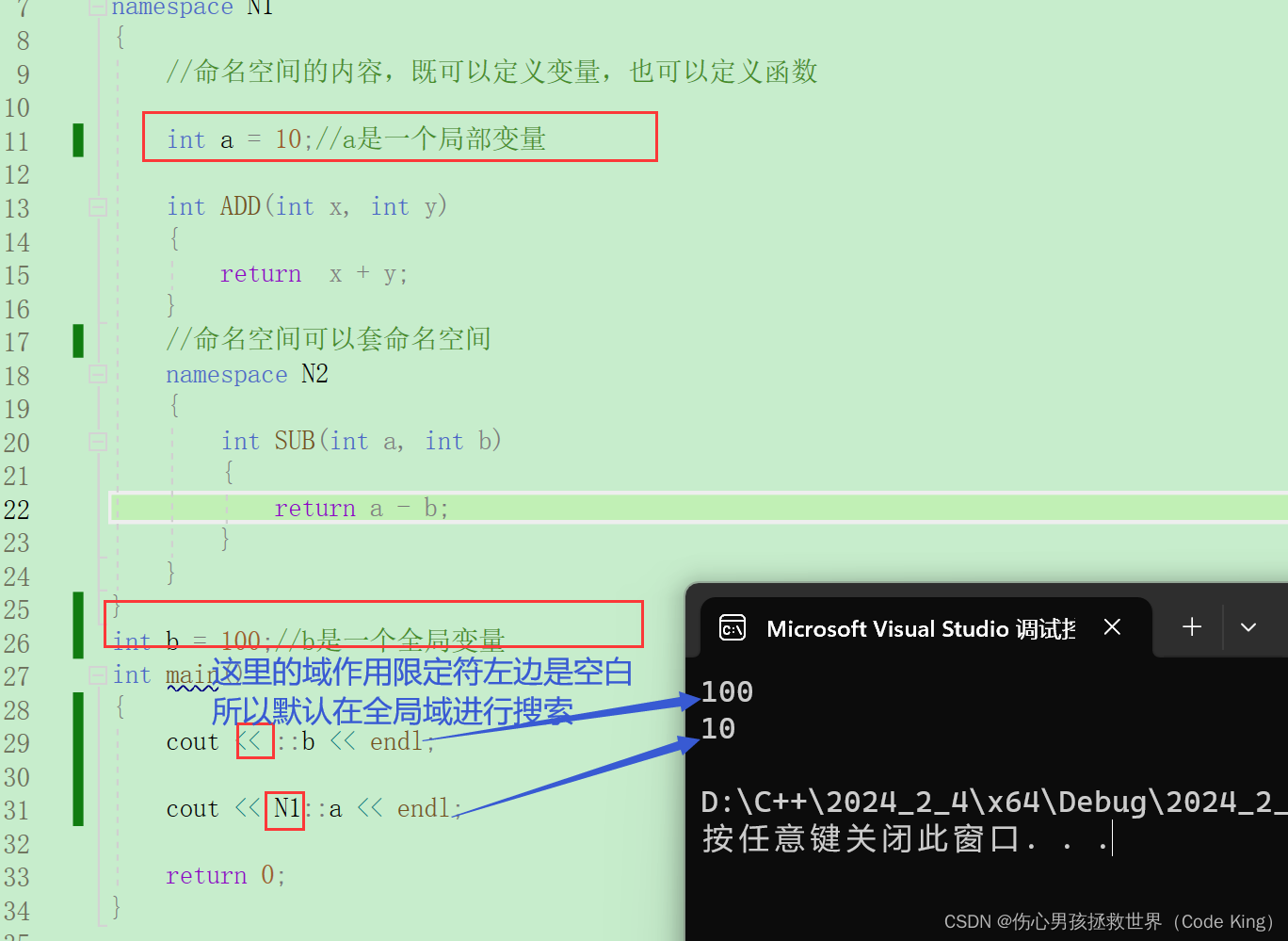
(::)域作用限定符,如果域作用限定符左边是空白,就默认是在全局域中进行搜索。
如果域作用限定符左边有指定域,那就只会在指定域进行搜索。
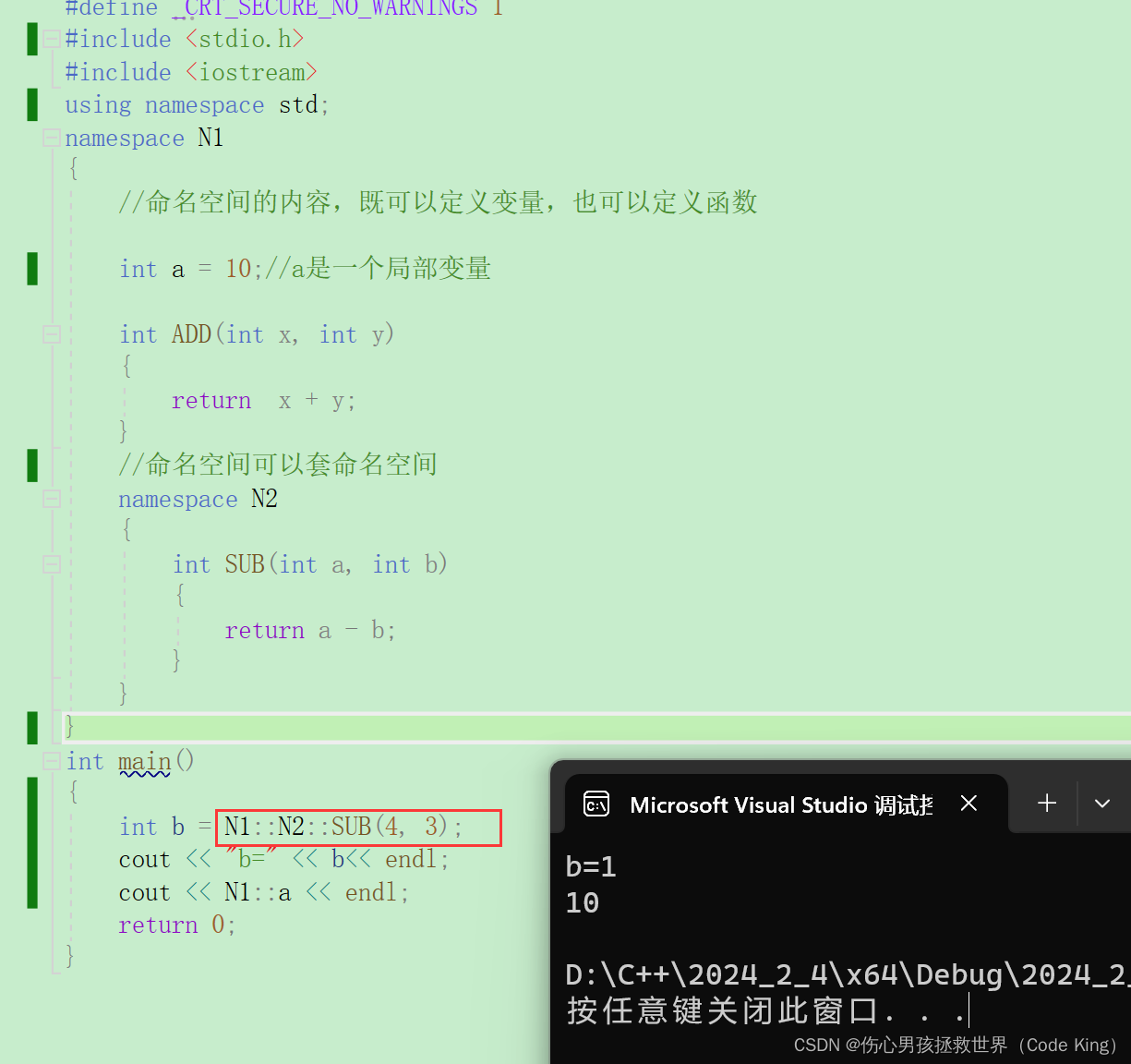
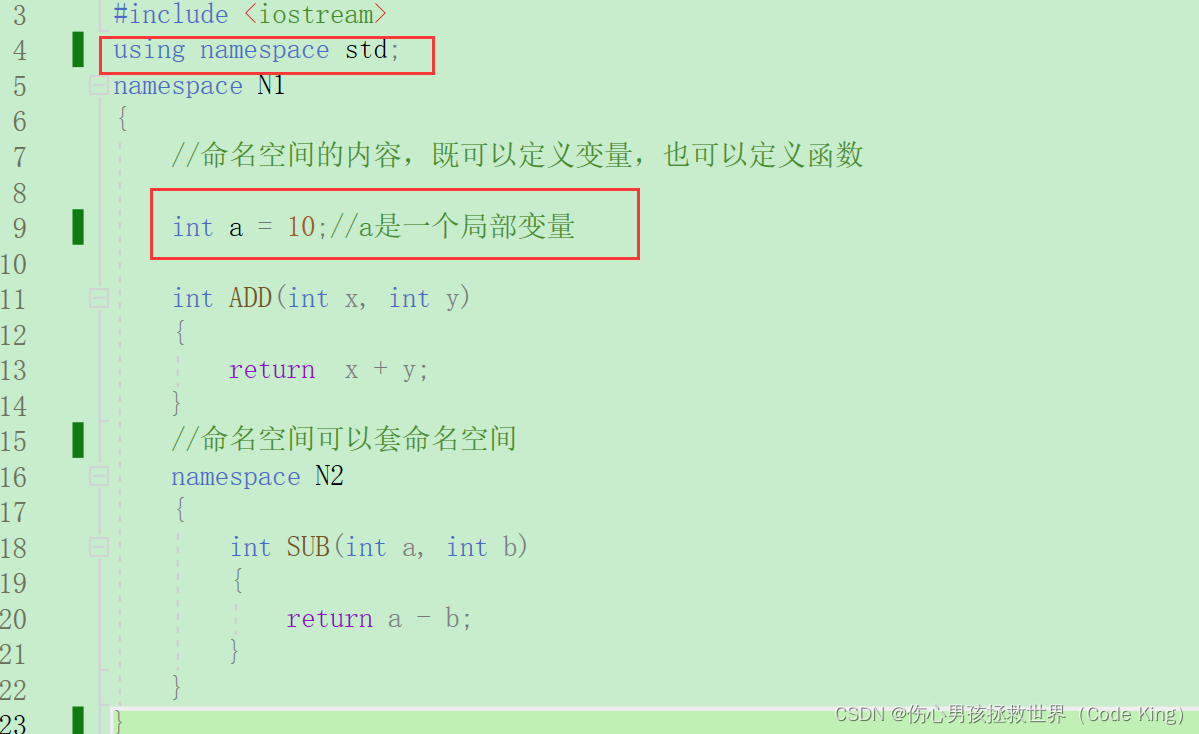
3.namespace的三种使用方式

二、C++的输入与输出
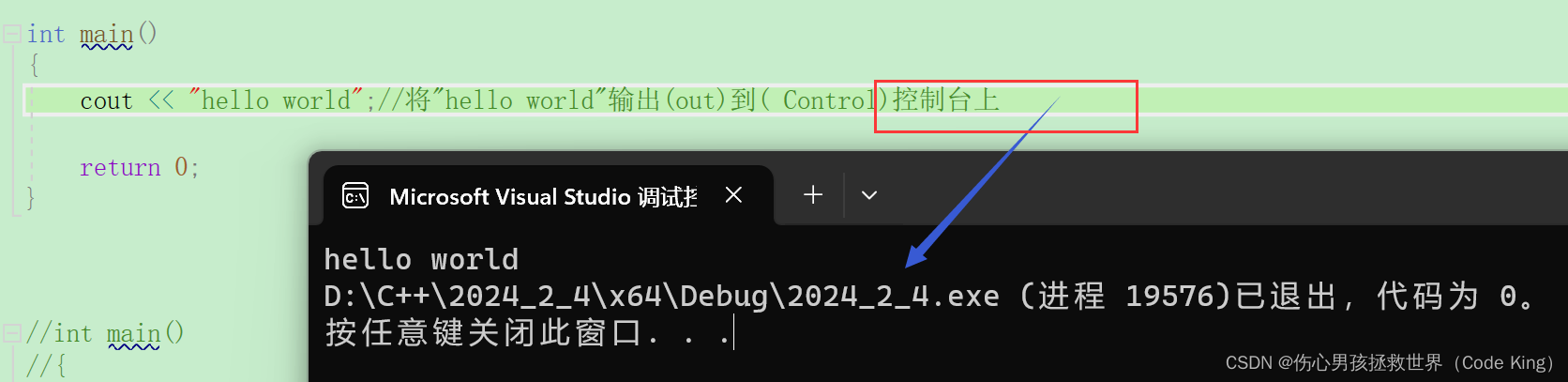
注意:
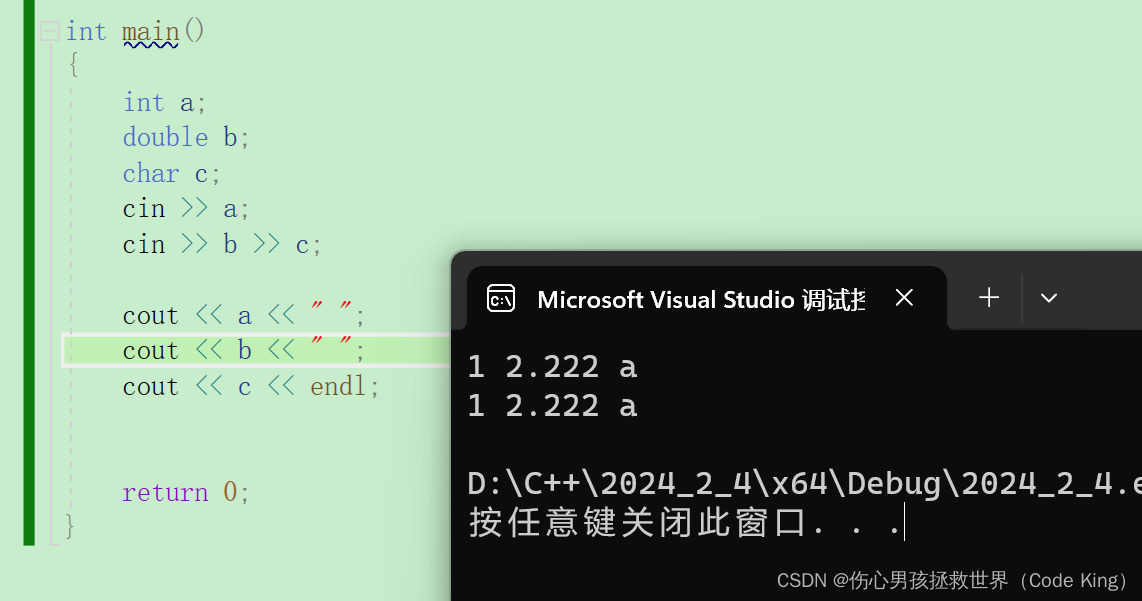
三、缺省参数
1.缺省参数的定义
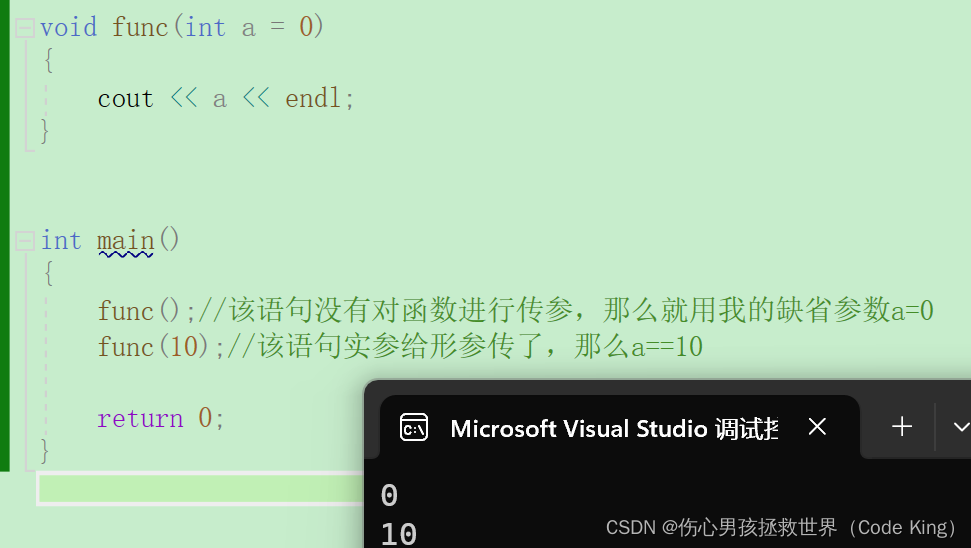
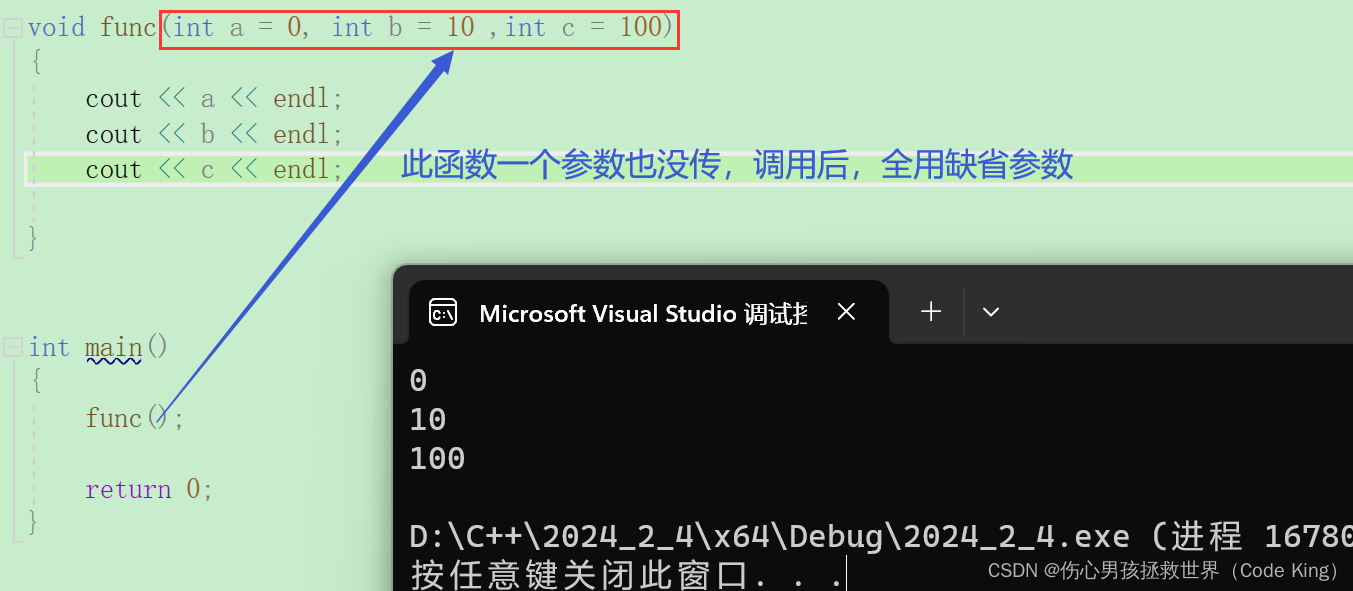
2.缺省参数的分类
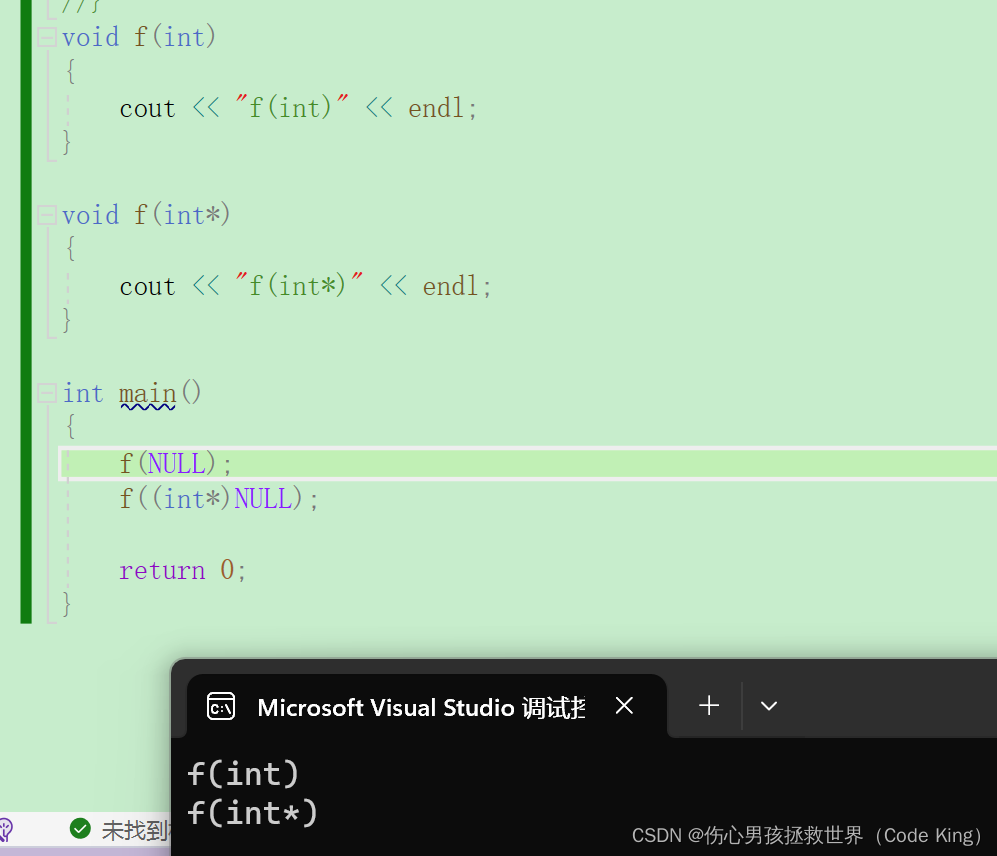
四、函数重载
1.函数重载的概念
2.C++支持函数重载的原因
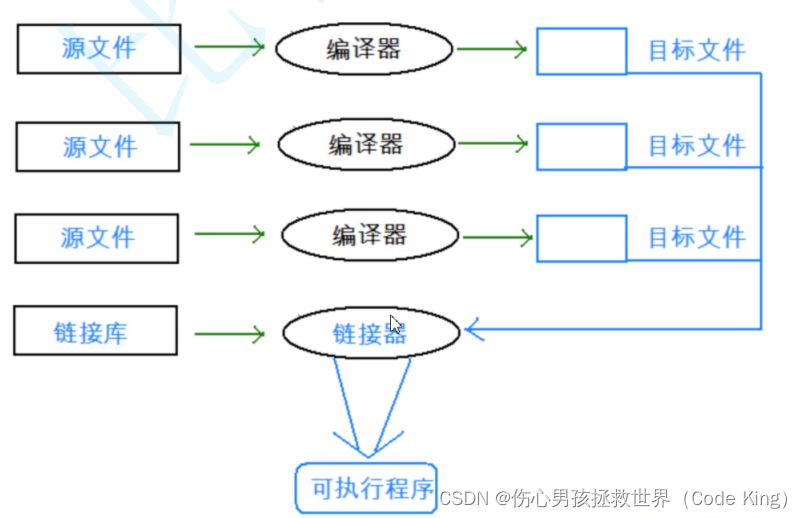
五、引用
1.引用的定义
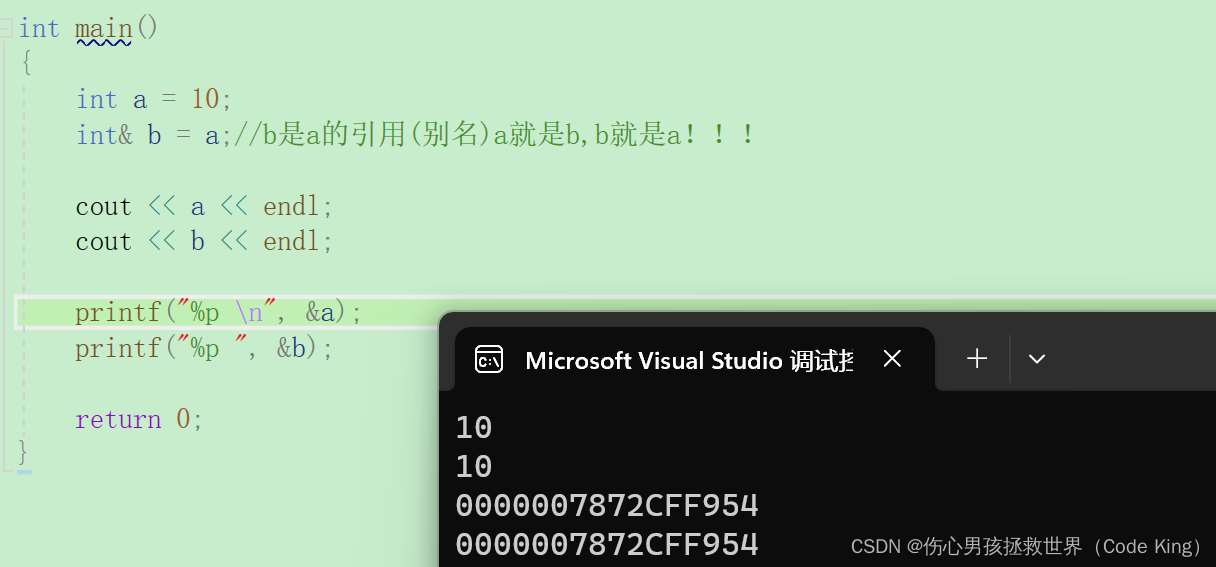
2.引用的特性
3.使用场景
(1)做参数
(2)做返回值
1.传值返回
2.传引用返回
3.传值和传引用的区别
4.引用和指针
引用和指针的不同点
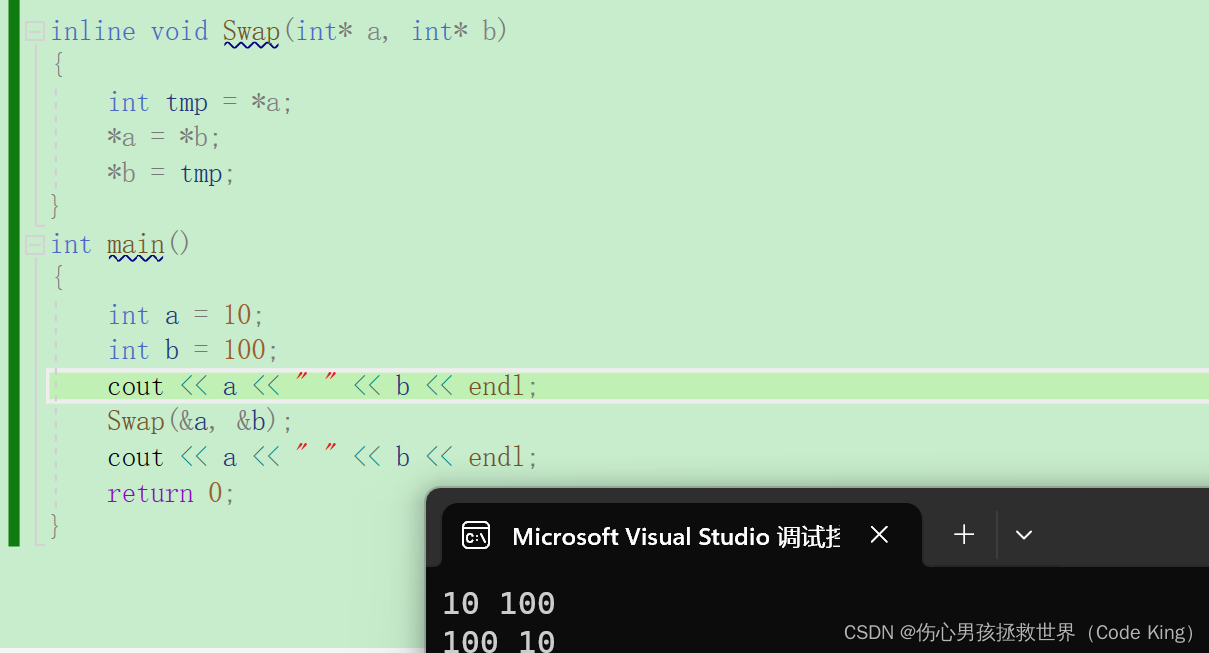
六、内联函数
1.内联函数的概念
2.特性
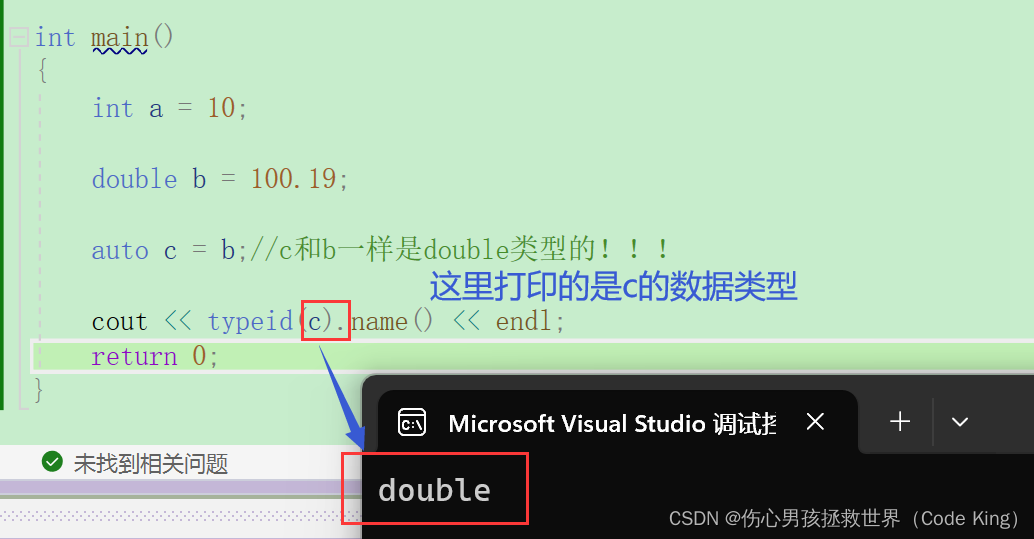
七、auto和 nullptr
1.关键字:auto
2.nullptr


声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。




