本文介绍: 概述、原理、读缓存、写缓存、缓存页管理、淘汰策略、数据、压缩、参数、参考
概述
关系型数据库MySQL有InnoDB存储引擎,存储引擎很大程度上决定着数据库的性能。
在MongoDB早期版本中,默认使用MMapV1存储引擎,其索引就是一个B-树(也称B树)。
从MongoDB 3.0开始引入WiredTiger(以下简称WT)存储引擎,在性能及稳定性上都有明显的提升。从MongoDB 3.2开始,WT作为默认的引擎,在索引和集合的检索上借鉴B+树。
WT是一个优秀的单机数据库存储引擎,拥有诸多特性,支持BTree、LSM Tree索引,支持行存储和列存储,实现ACID级别事务、支持大到4G的记录。
现代计算机近20年来CPU的计算能力和内存容量飞速发展,但磁盘的访问速度并没有得到相应的提高,WT就是在这样的一个情况下研发出来,充分利用CPU并行计算的内存模型的无锁并行框架,使得WT引擎在多核CPU上的表现优于其他存储引擎。针对磁盘存储特性,WT实现一套基于BLOCK/Extent的磁盘友好访问算法,使得WT在数据压缩和磁盘I/O访问上优势明显。实现基于snapshot技术的ACID事务,snapshot技术大大简化WT的事务模型,摒弃传统的事务锁隔离又同时能保证事务的ACID。WT根据现代内存容量特性实现一种基于Hazard Pointer的LRU cache模型,充分利用内存容量的同时又能拥有很高的事务读写并发。
WiredTiger存储引擎在数据检索性能上做了许多优化,基于内存的二级的缓存提供高速读取数据能力,在写方面则是根据磁盘I/O的特点做缓冲式写入,这是基于空间、时间因素权衡的一种择优设计。
原理
读缓存
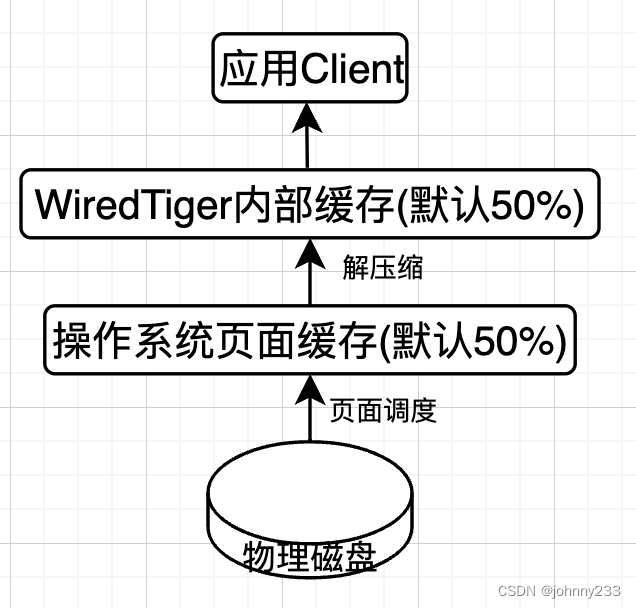
写缓冲
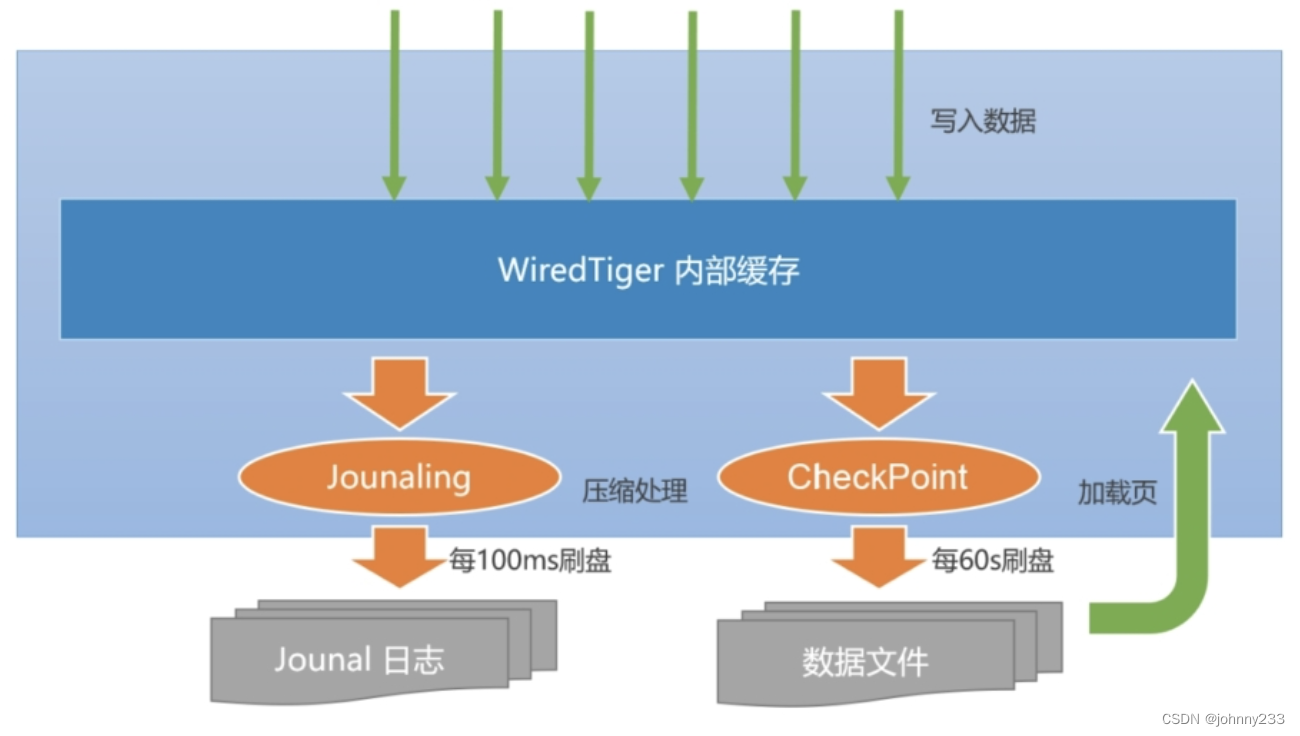
缓存页管理
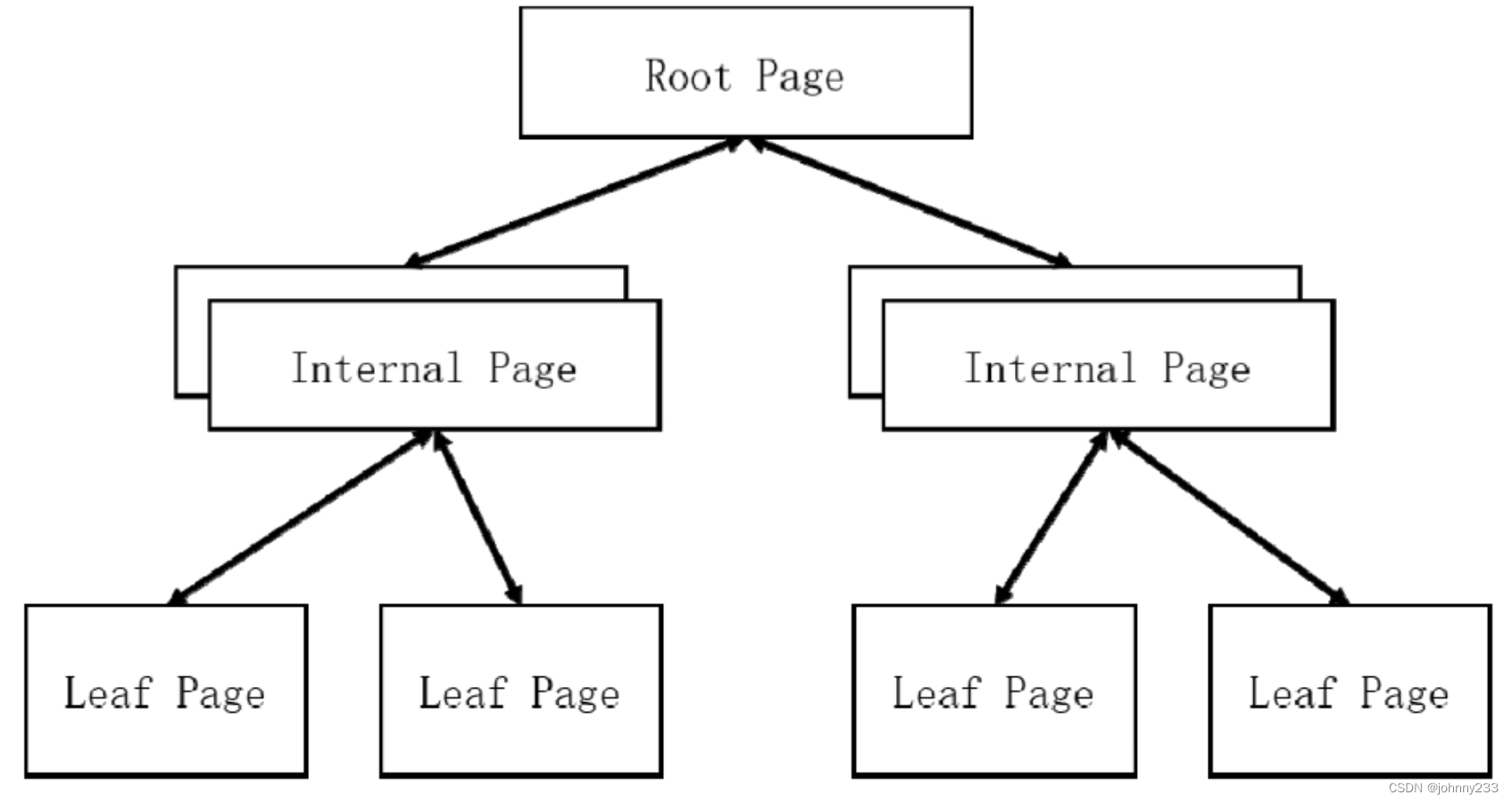
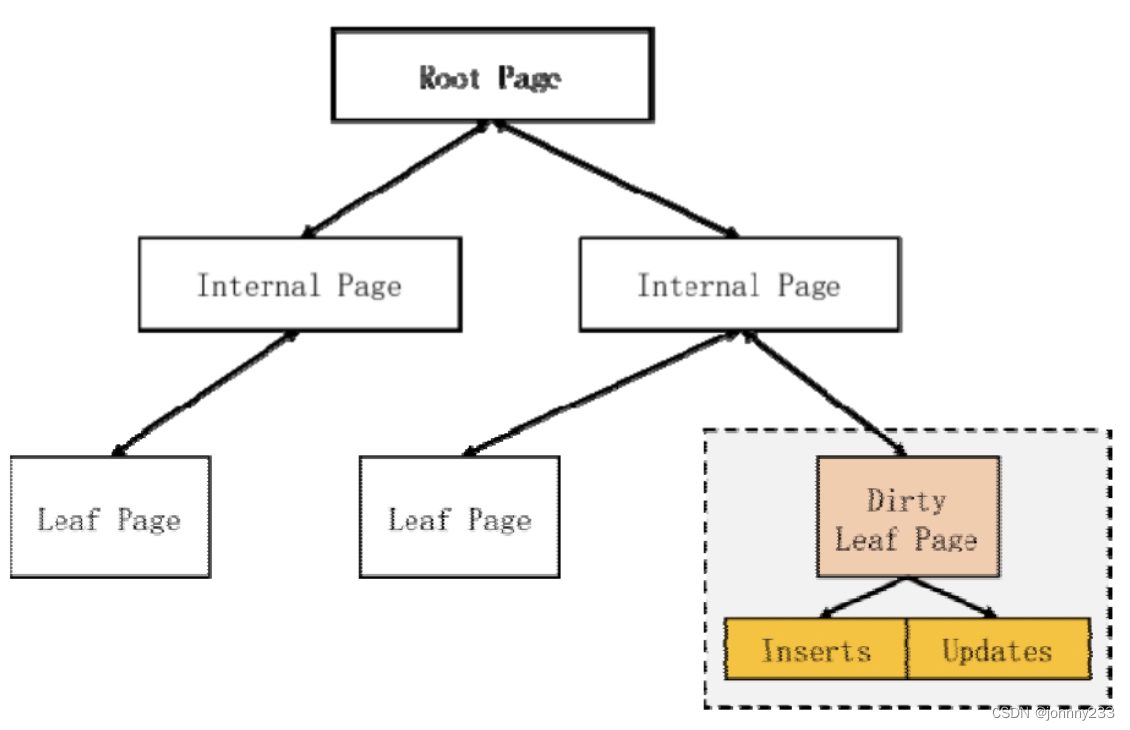
数据
压缩
参数
参考
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。