本文介绍: 最近要批量解压归档文件和压缩包,所以就想能不能并行执行这些工作。因为tar自身不支持并行解压,但是像make却可以支持生成一些文件,所以我才有了这种想法。方法有两种,第一种不用安装任何软件或工具,直接bash或其他 Shell 中就可以使用;第二种需要安装 GNU parallel 这个工具来进行。二者在使用上都很简单,但是后者更人性化(应该可以用这个词来形容)一些。最后还介绍了一种比较奇特的方法,是无意中看到的,虽然没啥用但是有点意思。
最近要批量解压归档文件和压缩包,所以就想能不能并行执行这些工作。因为tar自身不支持并行解压,但是像make却可以支持生成一些文件,所以我才有了这种想法。
方法有两种,第一种不用安装任何软件或工具,直接bash或其他 Shell 中就可以使用;第二种需要安装 GNU parallel 这个工具来进行。二者在使用上都很简单,但是后者更人性化(应该可以用这个词来形容)一些。最后还介绍了一种比较奇特的方法,是无意中看到的,虽然没啥用但是有点意思。
直接在命令最后使用&
这个方法需要在命令最后使用&,也就是将这个命令放入后台执行。如下是并行解压提取当前文件夹下所有的归档文件的方法:
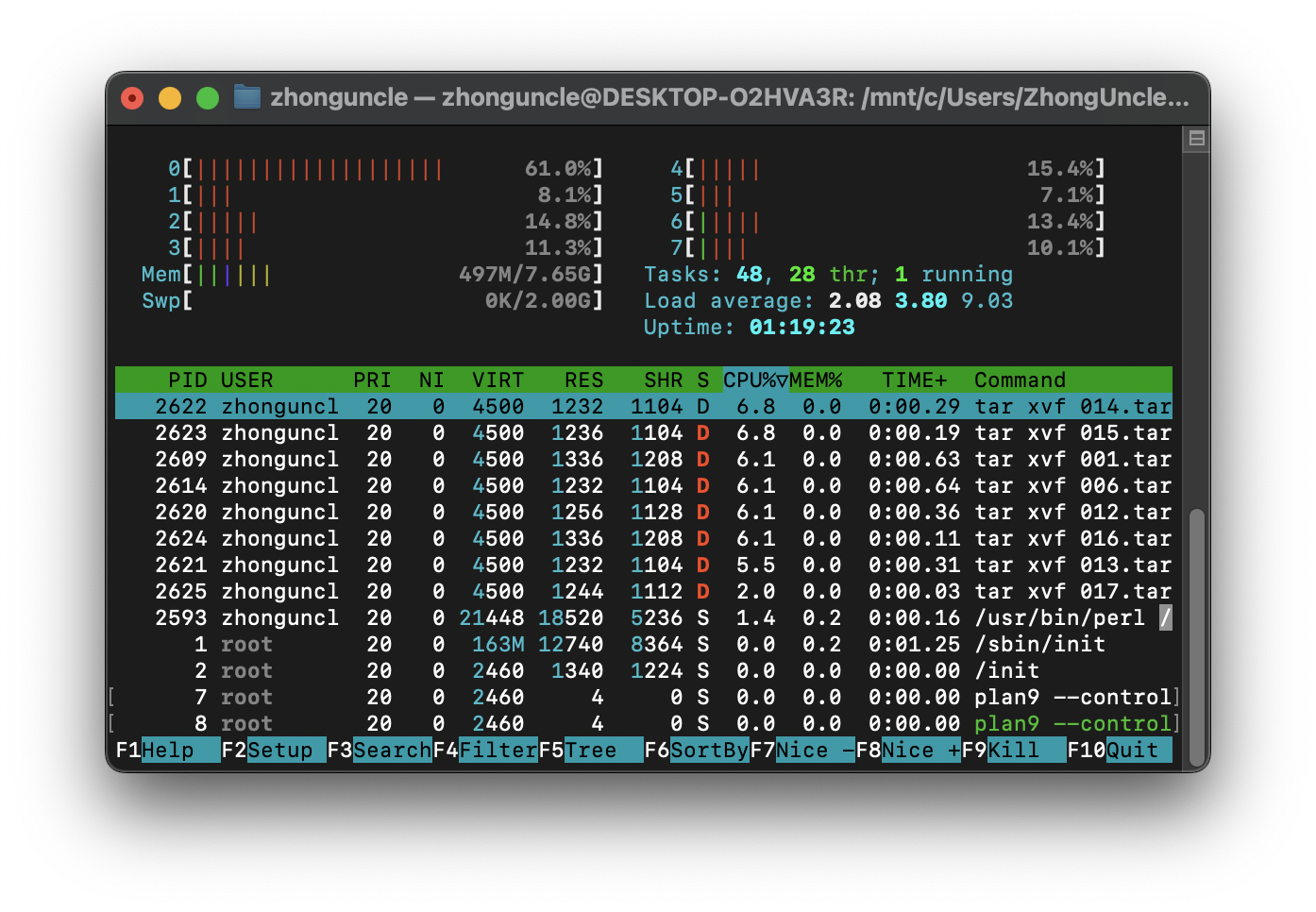
可以看到这个方法可以说是非常简单了,但是最大的问题就是它会给每个归档文件创建一个进程,并不会自动根据设备的线程数而创建合适数量的进程(tar由于需要大量 I/O,所以也无法维持高 CPU 使用率),如下:
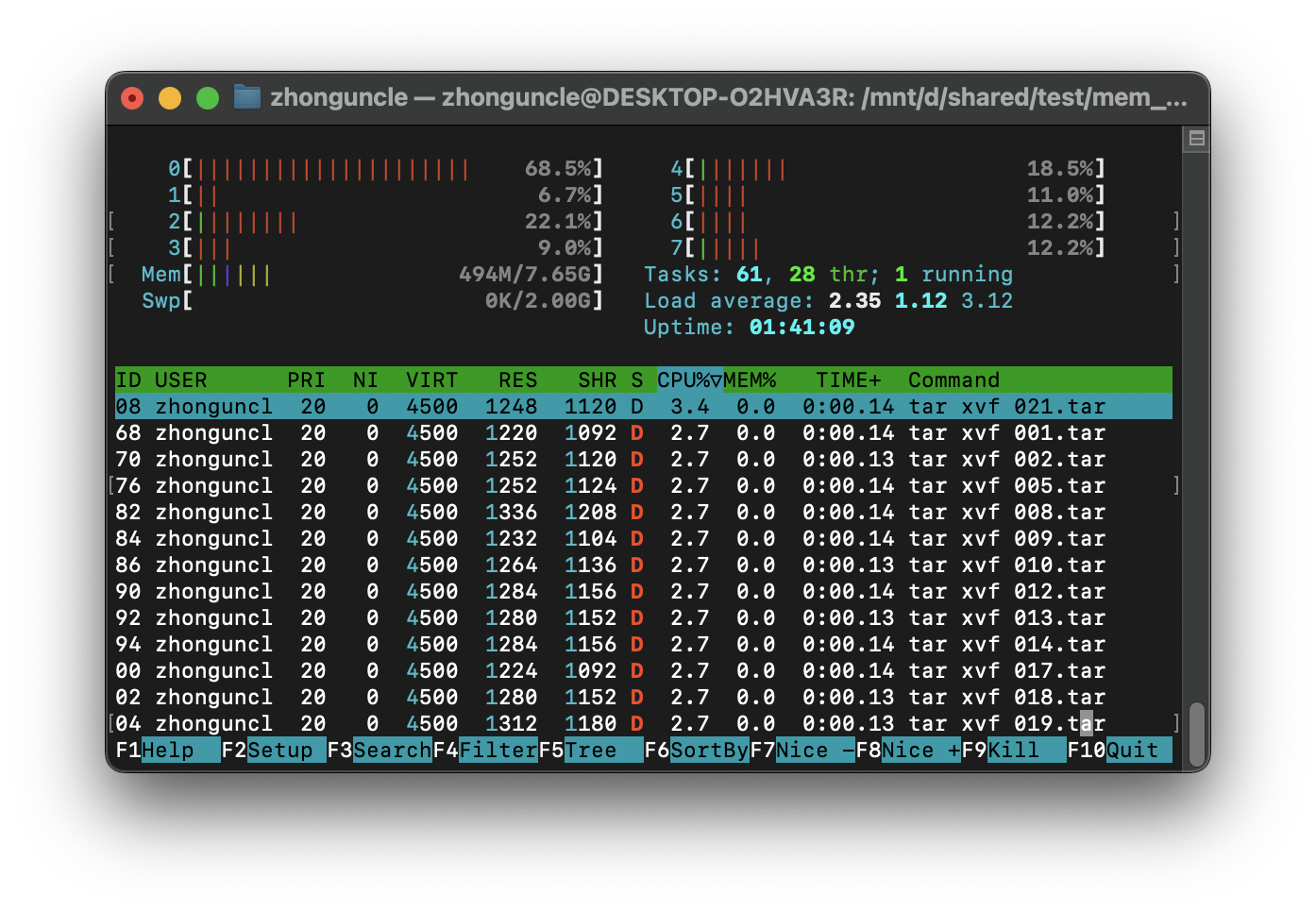
如果是小数量的解压提取可能没什么问题,但是如果特别大数量的归档文件解压提取,那么可能会造成调度损耗过大。如果需要根据实际线程数量生成,那么就复杂多了。
使用GNU parallel
管道传递参数
二者的速度区别
扩展
参考资料
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。