本文介绍: 通过这些数据,GLIP学习到了丰富的视觉概念和语义信息,比如什么是“猫”,它们长什么样,常出现在哪些场景中,以及如何根据不同的描述(例如“黑色的猫”)来识别和定位具体的对象。比如,当GLIP遇到一个它在预训练数据中没有直接见过的新图片,即使这张图片中的对象是新的或者以新的方式出现,GLIP也能利用它从预训练中学到的知识,来识别和定位图片中的对象。: 在现有的视觉识别任务中,模型通常是针对一组固定的对象类别进行训练的,这限制了它们在现实世界中的应用,因为遇到新的视觉概念时,需要额外的标注数据来进行泛化。
论文:https://arxiv.org/pdf/2112.03857.pdf
代码:https://github.com/microsoft/GLIP
核心思想
问题: 在现有的视觉识别任务中,模型通常是针对一组固定的对象类别进行训练的,这限制了它们在现实世界中的应用,因为遇到新的视觉概念时,需要额外的标注数据来进行泛化。
而且,要想理解图片中的细节(如对象检测、分割、姿态估计等),需要对象级别的、富含语义的视觉表征。
GLIP 对比 BLIP、BLIP-2、CLIP
主要问题: 如何构建一个能够在不同任务和领域中以零样本或少样本方式无缝迁移的预训练模型?
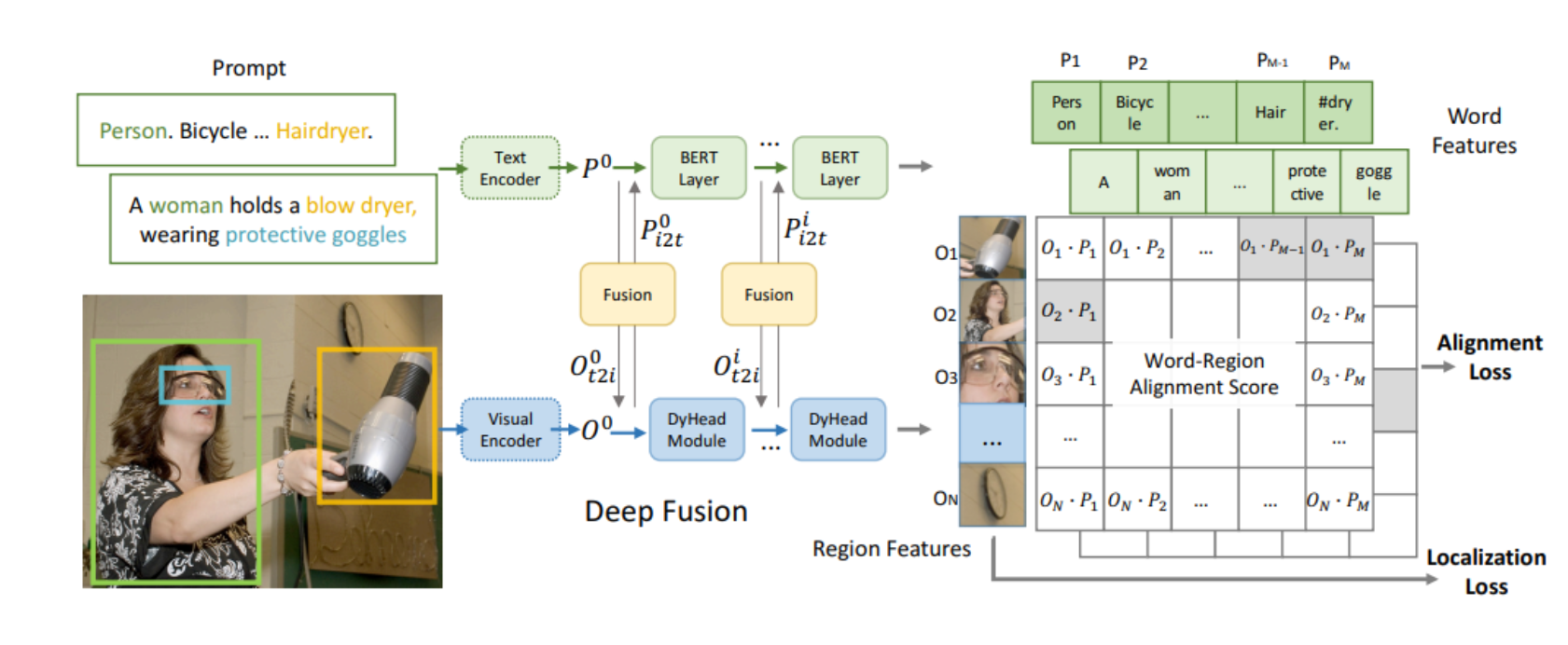
统一的短语定位损失
语言意识的深度融合
预训练数据类型的结合
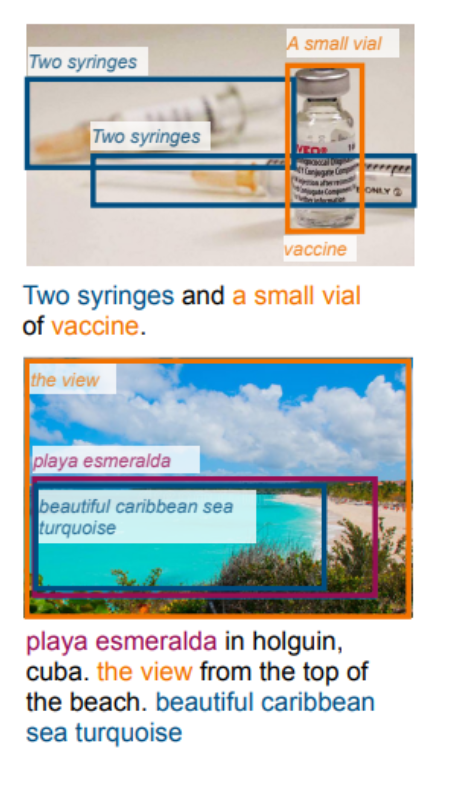
语义丰富数据的扩展
零样本和少样本迁移学习
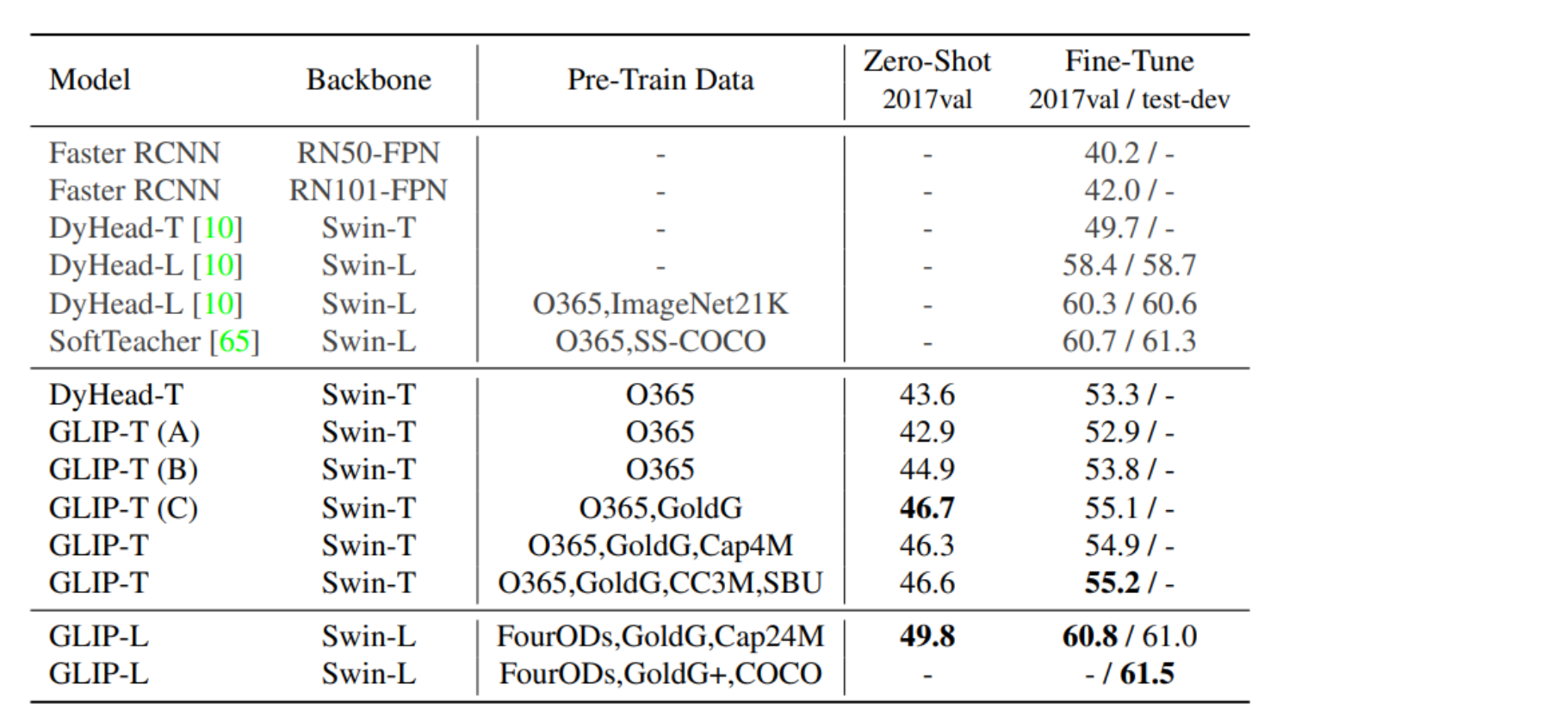
效果
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。