本文介绍: 我们知道,在kubernetes中,pod中容器的资源隔离主要通过namespace和cgroup来实现。2.通过前面infra容器的前置知识,可以知道infra container是和pod所有容器共享networknamespace的,因此可以直接把故障做在infra容器上,并且infra容器的生命周期是和pod相同的。在给pod注入网络故障,模拟pod网络延迟,丢包的场景下,会出现注入故障的目标container重启,进而导致故障恢复失败,最后只能重启相应pod来恢复故障。
目录
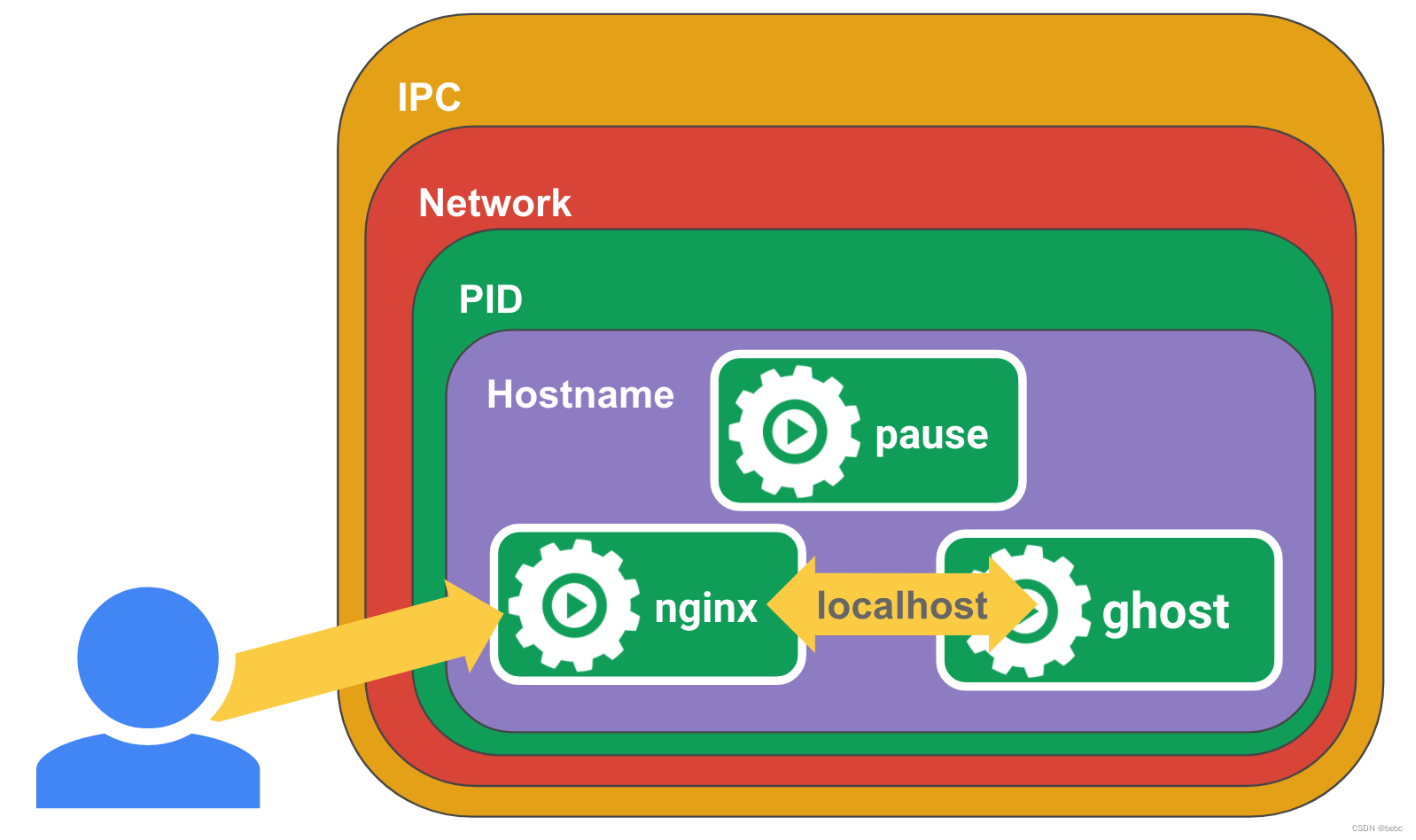
一、infra容器的作用
我们知道,在kubernetes中,pod中容器的资源隔离主要通过namespace和cgroup来实现。那如果我们需要为pod中的容器共享某种资源应该怎么做。kubernetes 中的 pause 容器就提供了以下功能:
二、pod网络故障注入问题
背景:
问题分析:
三、充分利用pod infra容器
思考:
解决:
四、参考
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。