导语
本文探索了如何通过各种提示设计策略,来增强大型语言模型(LLMs)在Few-shot In-context Learning中的文本到SQL转换能力。通过使用示例SQL查询的句法结构来检索演示示例,并选择同时追求多样性和相似性的示例可以提高性能,同时,LLMs也从与数据库相关的知识增强中受益。
1 引言
文本到SQL解析作为信息检索系统的关键组成部分,将自然语言查询转化为可从数据库中检索相关信息的SQL语句。近年来,神经符号设计方法结合了神经网络的功能和符号逻辑的严密性,成为提高系统可靠性和鲁棒性的首选技术。本文的重点在于探索和验证各种提示设计策略,旨在提升大型语言模型在文本到SQL解析任务中的表现,并特别关注于利用SQL查询的句法结构来改进示例选择,实验结果证明了这种方法在提升性能方面的有效性。同时也发现LLMs在某些情况下能从数据库知识增强中受益。本研究在Spider数据集上获得的执行准确度高达84.4,超越了目前最先进的系统和最佳微调系统,突显了所提策略的有效性和实用性

2 方法
2.1 示例选择
该模块的目标是从上下文的示例池中选择一部分标注示例。可以使用的方法如
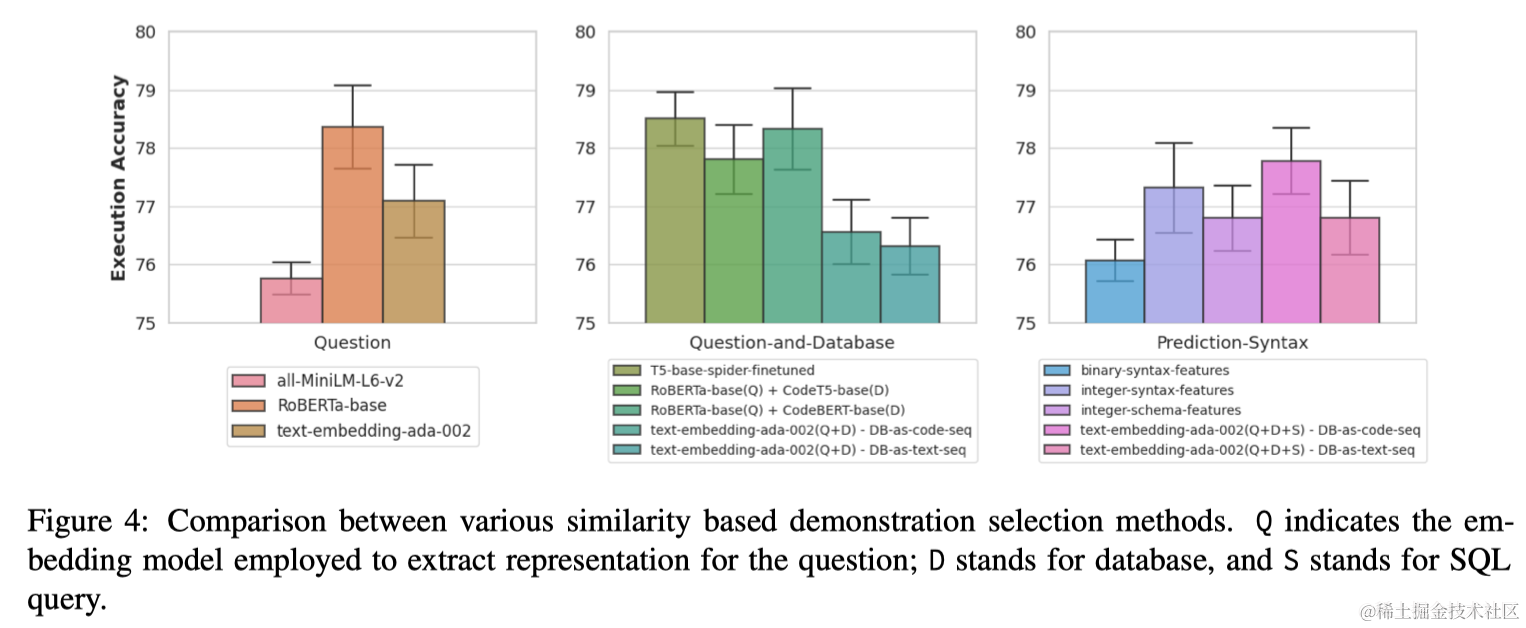
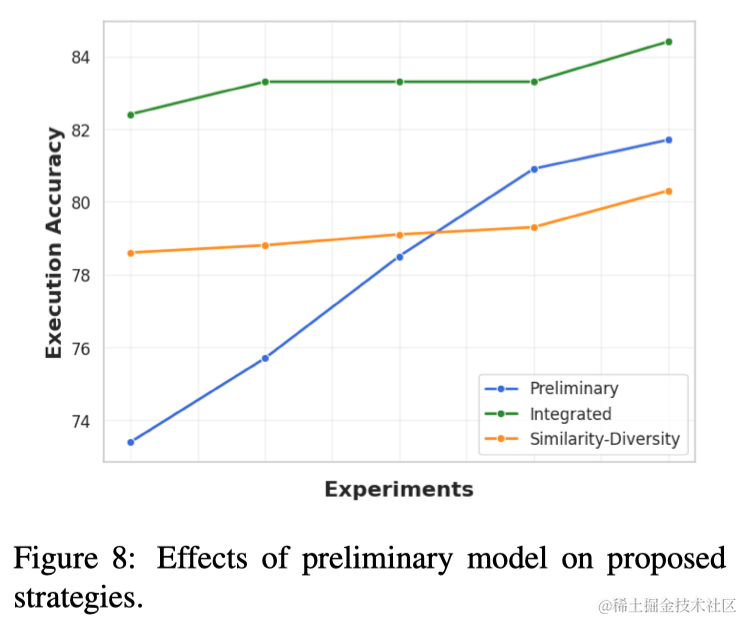
本文提出使用输出SQL查询来选择示例,而不是使用输入问题。这是因为作者认为Text-to-SQL中SQL语句包含比输入问题中更明确的关于问题结构的信息。此外,与只能转换成连续语义向量的自然语言问题不同,SQL查询可以根据其语法转换成离散特征向量。为此,首先将所有池实例的SQL查询转换成离散语法向量。然后,这些元素被映射到二进制特征,表示它们在查询中的存在。推理时,首先使用初步预测器生成SQL查询草稿。然后,应用相同的过程将这个草稿查询转换成离散向量,用于检索演示示例。
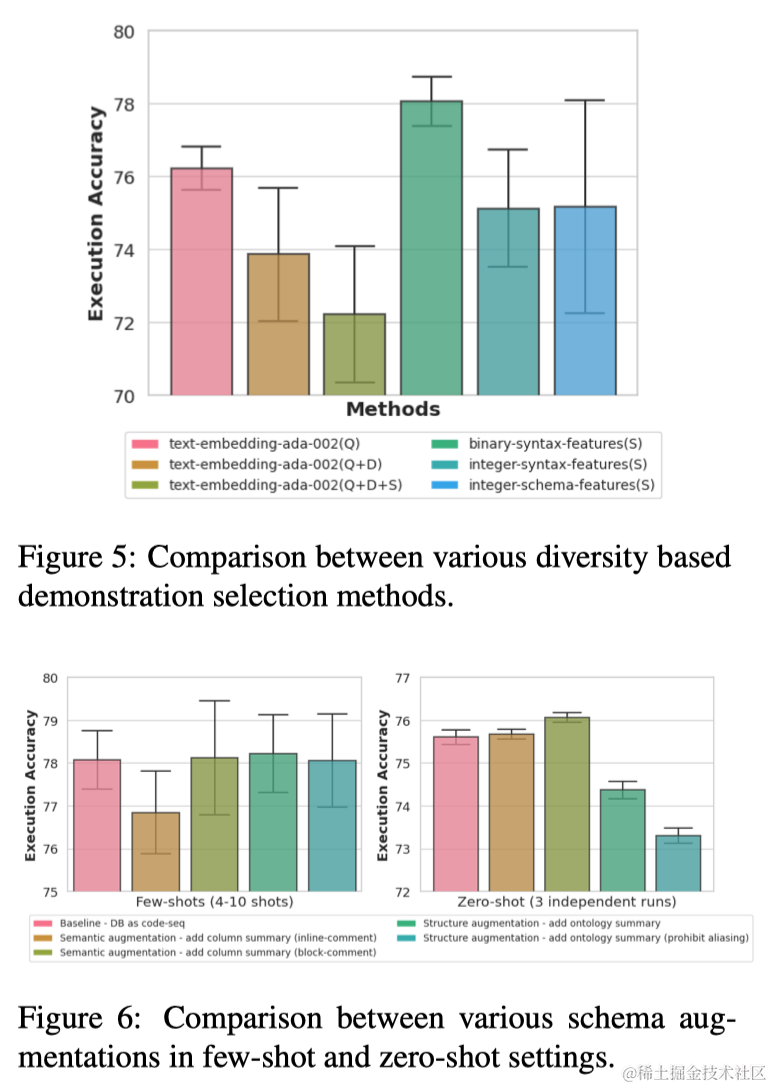
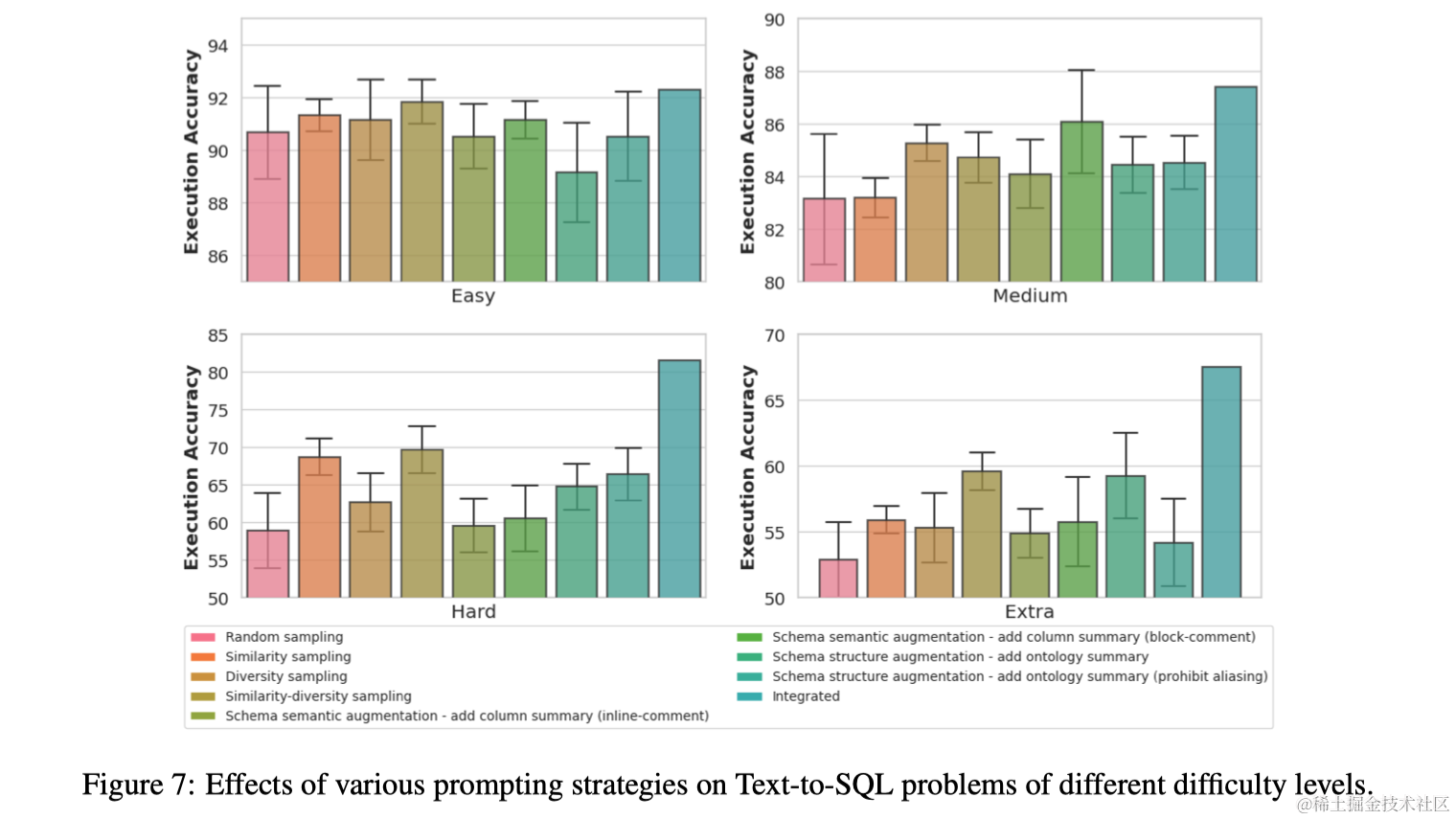
作者提出了一种与之前不同的演示选择策略,即寻求平衡演示的相似性和多样性,这是通过将给定示例的表示从表示问题语义的连续值向量更改为捕获SQL语法的离散值向量来实现的。为此,首先将标注示例池划分为表示不同类别的不相交分区(基于难度等级)。给定一个测试实例,使用初步预测器生成一个草稿SQL查询,并根据其类别,检索属于相关分区的候选示例。接下来对示例的离散向量实施k-means聚类,选择靠近每个聚类中心的k个多样化示例用于构建提示。演示选择策略过程概述在算法1中。