本文介绍: JVM的执行流程程序在执行前先要把Java代码转换成字节码(.class)文件,JVM需要将字节码文件通过一定方式的**类加载器(ClassLoader)**把文件加载到内存的**运行时数据区(Runtime Data Area)**,而字节码文件是JVM的一套指令集规范,并不能直接由底层操作系统区执行,因此需要特定的命令解析器**执行引擎(Execution Engine)**将字节码翻译成底层系统指令再交给CPU去执行,这个过程中需要调用其他语言的接口**本地库接口(Native Interface
为什么学习JVM
JVM的执行流程
程序在执行前先要把Java代码转换成字节码(.class)文件,JVM需要将字节码文件通过一定方式的类加载器(ClassLoader)把文件加载到内存的运行时数据区(Runtime Data Area),而字节码文件是JVM的一套指令集规范,并不能直接由底层操作系统区执行,因此需要特定的命令解析器**执行引擎(Execution Engine)将字节码翻译成底层系统指令再交给CPU去执行,这个过程中需要调用其他语言的接口本地库接口(Native Interface)**来实现整个程序的功能。
JVM的组成部分
类加载、运行时数据区(内存区域)、本地方法接口、执行引擎。
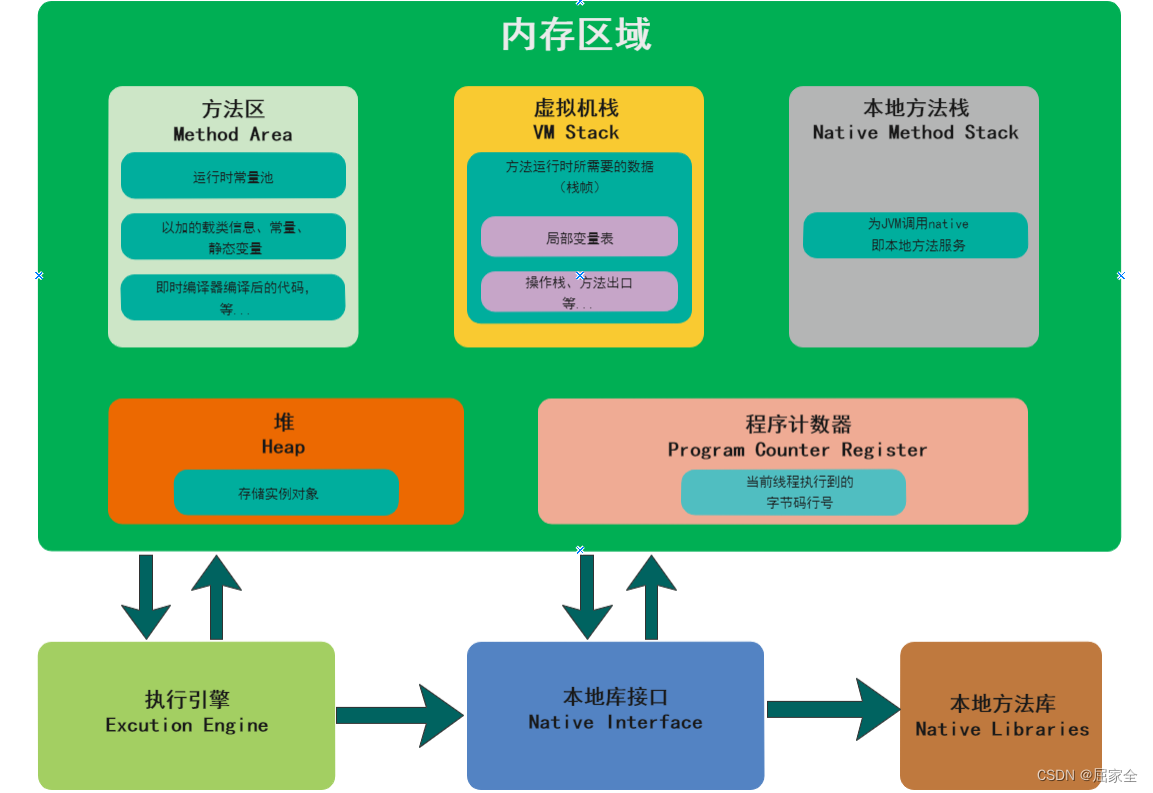
类加载
运行时数据区
本地方法接口
简单地讲,一个 Native Method 是一个Java调用非Java代码的接囗。一个 Native Method 是这样一个Java方法:该方法的实现由非Java语言实现,比如C。特点:用native关键字修饰的方法称为一个本地方法,没有方法体。
为什么使用:因为Java在有些层次的任务使用Java实现起来不容易,Java语言需要与外部环境进行交互,直接访问操作系统接口即可,JVM本身开发也是在底层使用了C语言。
执行引擎
垃圾回收
什么样的对象是垃圾呢
Java中的垃圾对象是指没有被任何引用变量所引用的对象。这些对象无法被访问,也无法被使用,因此它们占用内存空间而不被程序所使用,成为垃圾对象
内存溢出和内存泄漏
定位垃圾的方法
对象的finalization机制
垃圾回收算法
分代回收
垃圾回收器
JVM调优参数
JVM调优工具
Java内存泄漏排查思路
CPU飙高排查方案与思路
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。