本文介绍: 本篇内容主要讲解了多线程中关于cas和juc的相关知识点
1. 关于CAS
CAS: 全称Compare and swap,字面意思:”比较并交换“,且比较交换的是寄存器和内存;
一个 CAS 涉及到以下操作:
1.1 CAS伪代码
下面写的代码是伪代码,该段代码不能被顺利的编译运行,但是可以用来辅助理解上述所说 CAS 的工作流程.
CAS其实是一个cpu指令(一条cpu指令就能满足上述比较交换的逻辑),说明单个cpu指令是原子的。故此可以使用CAS完成一些操作(给编写线程安全的代码,引入了新的思路并且不涉及线程阻塞),进一步代替“加锁”;
1.2 CAS 有哪些应用
1.2.1 实现原子类
Int++操作不是原子的(load,add,save),其中AtomicInteger,基于CAS的方式对int进行封装了,此时进行int++(基于cas指令来实现的)就是原子的操作了

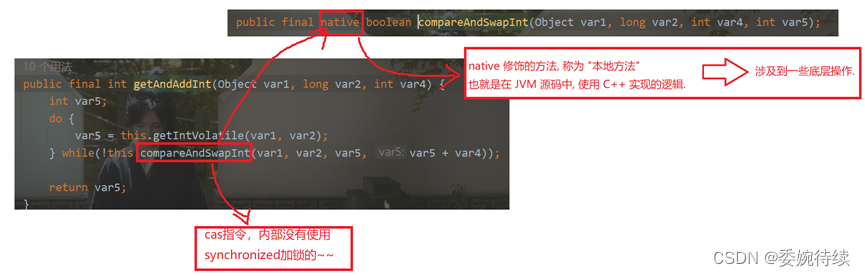

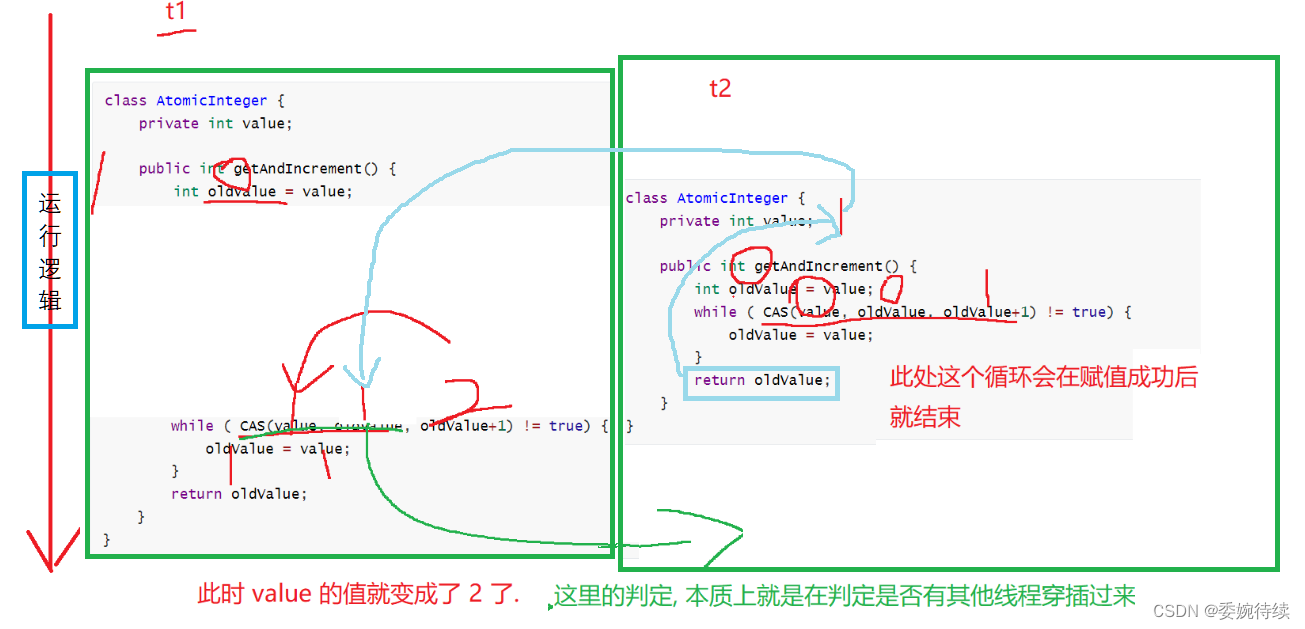
1.2.2 实现自旋锁


2. JUC的相关类
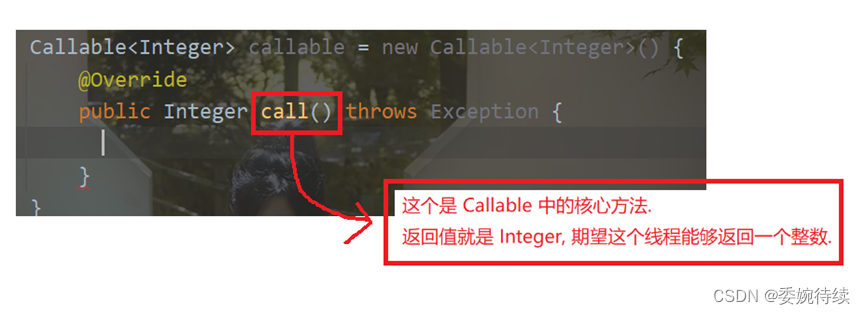
2.1 Callable 接口
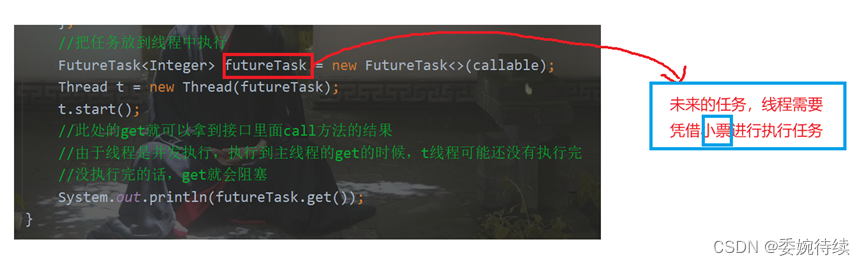
2.2 ReentrantLock
2.3 信号量 Semaphore
2.4 CountDownLatch
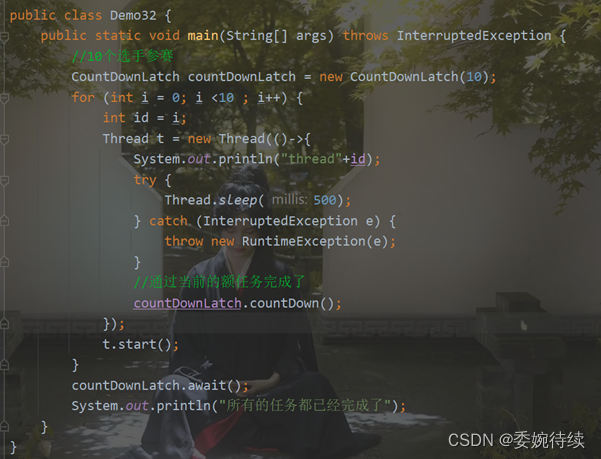

3 线程安全的集合类
3.1 多线程环境使用 ArrayList:
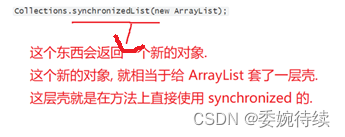
3.1.1 Collections.synchronizedList(new ArrayList);
3.1.2 使用 CopyOnWriteArrayList
3.2 多线程环境使用哈希表
3.2.1 Hashtable
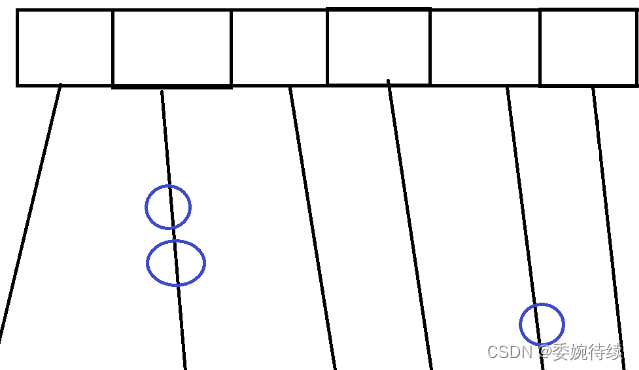
3.2.2 ConcurrentHashMap
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。