29.SpringCloud可以选择哪些微服务链路追踪方案?
服务容灾
21.什么是服务雪崩?
在微服务中,假如一个或者多个服务出现故障,如果这时候,依赖的服务还在不断发起请求,或者重试,那么这些请求的压力会不断在下游堆积,导致下游服务的负载急剧增加。不断累计之下,可能会导致故障的进一步加剧,可能会导致级联式的失败,甚至导致整个系统崩溃,这就叫服务雪崩。

一般,为了防止服务雪崩,可以采用这些措施:
22.什么是服务熔断?什么是服务降级?
什么是服务熔断?
服务熔断是微服务架构中的容错机制,用于保护系统免受服务故障或异常的影响。当某个服务出现故障或异常时,服务熔断可以快速隔离该服务,确保系统稳定可用。
它通过监控服务的调用情况,当错误率或响应时间超过阈值时,触发熔断机制,后续请求将返回默认值或错误信息,避免资源浪费和系统崩溃。
服务熔断还支持自动恢复,重新尝试对故障服务的请求,确保服务恢复正常后继续使用。
什么是服务降级?
服务降级是也是一种微服务架构中的容错机制,用于在系统资源紧张或服务故障时保证核心功能的可用性。
当系统出现异常情况时,服务降级会主动屏蔽一些非核心或可选的功能,而只提供最基本的功能,以确保系统的稳定运行。通过减少对资源的依赖,服务降级可以保证系统的可用性和性能。
它可以根据业务需求和系统状况来制定策略,例如替换耗时操作、返回默认响应、返回静态错误页面等。
有哪些熔断降级方案实现?
目前常见的服务熔断降级实现方案有这么几种:

23.Hystrix怎么实现服务容错?
尽管已经不再更新,但是Hystrix是非常经典的服务容错开源库,它提供了多种机制来保护系统:

-
服务熔断(Circuit Breaker):Hystrix通过设置阈值来监控服务的错误率或响应时间。当错误率或响应时间超过预设的阈值时,熔断器将会打开,后续的请求将不再发送到实际的服务提供方,而是返回预设的默认值或错误信息。这样可以快速隔离故障服务,防止故障扩散,提高系统的稳定性和可用性。
-
服务降级(Fallback):当服务熔断打开时,Hystrix可以提供一个备用的降级方法或返回默认值,以保证系统继续正常运行。开发者可以定义降级逻辑,例如返回缓存数据、执行简化的逻辑或调用其他可靠的服务,以提供有限但可用的功能。
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
/**
* 服务降级示例
**/
@Service
public class MyService {
@HystrixCommand(fallbackMethod = "fallbackMethod")
public String myServiceMethod() {
// 实际的服务调用逻辑
// ...
}
public String fallbackMethod() {
// 降级方法的逻辑,当服务调用失败时会执行此方法
// 可以返回默认值或执行其他备用逻辑
// ...
}
}-
请求缓存(Request Caching):Hystrix可以缓存对同一请求的响应结果,当下次请求相同的数据时,直接从缓存中获取,避免重复的网络请求,提高系统的性能和响应速度。
-
请求合并(Request Collapsing):Hystrix可以将多个并发的请求合并为一个批量请求,减少网络开销和资源占用。这对于一些高并发的场景可以有效地减少请求次数,提高系统的性能。
-
实时监控和度量(Real-time Monitoring and Metrics):Hystrix提供了实时监控和度量功能,可以对服务的执行情况进行监控和统计,包括错误率、响应时间、并发量等指标。通过监控数据,可以及时发现和解决服务故障或性能问题。
-
线程池隔离(Thread Pool Isolation):Hystrix将每个依赖服务的请求都放在独立的线程池中执行,避免因某个服务的故障导致整个系统的线程资源耗尽。通过线程池隔离,可以提高系统的稳定性和可用性。
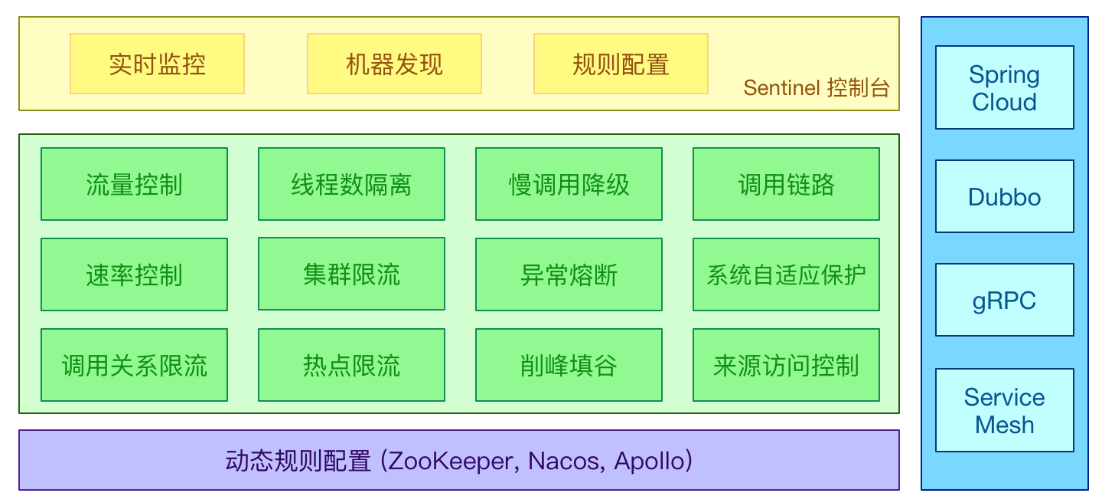
24.Sentinel怎么实现限流的?
Sentinel通过动态管理限流规则,根据定义的规则对请求进行限流控制。具体实现步骤如下:
// 原本的业务方法.
@SentinelResource(blockHandler = "blockHandlerForGetUser")
public User getUserById(String id) {
throw new RuntimeException("getUserById command failed");
}
// blockHandler 函数,原方法调用被限流/降级/系统保护的时候调用
public User blockHandlerForGetUser(String id, BlockException ex) {
return new User("admin");
}private static void initFlowQpsRule() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule1 = new FlowRule();
rule1.setResource(resource);
// Set max qps to 20
rule1.setCount(20);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule1.setLimitApp("default");
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}

Sentinel采用的什么限流算法?
滑动窗口限流算法是一种基于时间窗口的限流算法。它将一段时间划分为多个时间窗口,并在每个时间窗口内统计请求的数量。通过动态地调整时间窗口的大小和滑动步长,可以更精确地控制请求的通过速率。
Sentinel怎么实现集群限流?
Sentinel利用了Token Server和Token Client的机制来实现集群限流。
开启集群限流后,Client向Token Server发送请求,Token Server根据配置的规则决定是否限流。T

服务网关
25.什么是API网关?
API网关(API Gateway)是一种中间层服务器,用于集中管理、保护和路由对后端服务的访问。它充当了客户端与后端服务之间的入口点,提供了一组统一的接口来管理和控制API的访问。
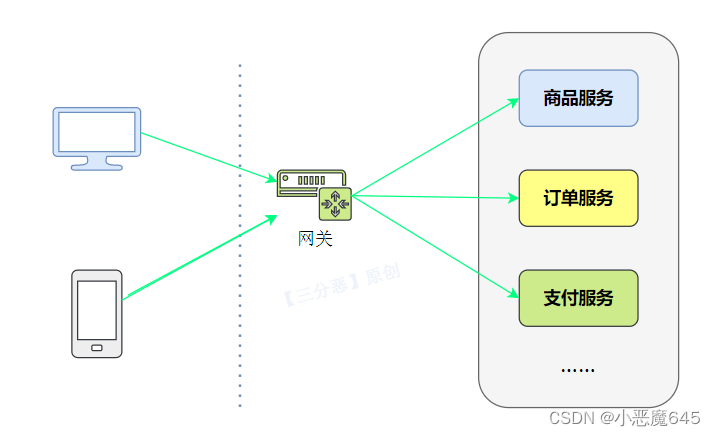
API网关的主要功能包括:
-
路由转发:API网关根据请求的URL路径或其他标识,将请求路由到相应的后端服务。通过配置路由规则,可以灵活地将请求分发给不同的后端服务。
-
安全认证与授权:API网关可以集中处理身份验证和授权,确保只有经过身份验证的客户端才能访问后端服务。它可以与身份提供者(如OAuth、OpenID Connect)集成,进行用户认证和授权操作。
-
监控与日志:API网关可以收集和记录请求的指标和日志,提供实时监控和分析,帮助开发人员和运维人员进行故障排查和性能优化。
-
数据转换与协议转换:API网关可以在客户端和后端服务之间进行数据格式转换和协议转换,如将请求从HTTP转换为WebSocket,或将请求的参数进行格式转换,以满足后端服务的需求。
-
API版本管理:API网关可以管理不同版本的API,允许同时存在多个API版本,并通过路由规则将请求正确地路由到相应的API版本上。
……
通过使用API网关,可以简化前端与后端服务的交互,提供统一的接口和安全性保障,同时也方便了服务治理和监控。它是构建微服务架构和实现API管理的重要组件之一。
26.SpringCloud可以选择哪些API网关?
使用SpringCloud开发,可以采用以下的API网关选型:
-
Netflix Zuul(已停止更新):Netflix Zuul是Spring Cloud早期版本中提供的默认API网关。它基于Servlet技术栈,可以进行路由、过滤、负载均衡等功能。然而,自2020年12月起,Netflix宣布停止对Zuul 1的维护,转而支持新的API网关项目。
-
Spring Cloud Gateway:Spring Cloud Gateway是Spring Cloud官方推荐的API网关,取代了Netflix Zuul。它基于非阻塞的WebFlux框架,充分利用了响应式编程的优势,并提供了路由、过滤、断路器、限流等特性。Spring Cloud Gateway还支持与Spring Cloud的其他组件集成,如服务发现、负载均衡等。
-
Kong:Kong是一个独立的、云原生的API网关和服务管理平台,可以与Spring Cloud集成。Kong基于Nginx,提供了强大的路由、认证、授权、监控和扩展能力。它支持多种插件和扩展,可满足不同的API管理需求。
-
APISIX:APISIX基于Nginx和Lua开发,它具有强大的路由、流量控制、插件扩展等功能。APISIX支持灵活的配置方式,可以根据需求进行动态路由、负载均衡和限流等操作
27.Spring Cloud Gateway核心概念?

在Spring Cloud Gateway里,有三个关键组件:
-
Route(路由):路由是Spring Cloud Gateway的基本构建块,它定义了请求的匹配规则和转发目标。通过配置路由,可以将请求映射到后端的服务实例或URL上。路由规则可以根据请求的路径、方法、请求头等条件进行匹配,并指定转发的目标URI。
-
Predicate(断言):断言用于匹配请求的条件,如果请求满足断言的条件,则会应用所配置的过滤器。Spring Cloud Gateway提供了多种内置的断言,如Path(路径匹配)、Method(请求方法匹配)、Header(请求头匹配)等,同时也支持自定义断言。
-
Filter(过滤器):过滤器用于对请求进行处理和转换,可以修改请求、响应以及执行其他自定义逻辑。Spring Cloud Gateway提供了多个内置的过滤器,如请求转发、请求重试、请求限流等。同时也支持自定义过滤器,可以根据需求编写自己的过滤器逻辑。
我们再来看下Spring Cloud Gateway的具体工作流程:

-
Gateway Handler(网关处理器):网关处理器是Spring Cloud Gateway的核心组件,负责将请求转发到匹配的路由上。它根据路由配置和断言条件进行路由匹配,选择合适的路由进行请求转发。网关处理器还会依次应用配置的过滤器链,对请求进行处理和转换。
-
Gateway Filter Chain(网关过滤器链):网关过滤器链由一系列过滤器组成,按照配置的顺序依次执行。每个过滤器可以在请求前、请求后或请求发生错误时进行处理。过滤器链的执行过程可以修改请求、响应以及执行其他自定义逻辑。
链路追踪
28.为什么要用微服务链路追踪?
在微服务中,有的山下游可能有十几个服务,如果某一环出了问题,排查起来非常困难,所以,就需要进行链路追踪,来帮助排查问题。

通过链路追踪,可以可视化地追踪请求从一个微服务到另一个微服务的调用情况。除了排查问题,链路追踪黑还可以帮助优化性能,可视化依赖关系、服务监控和告警。
29.SpringCloud可以选择哪些微服务链路追踪方案?
Spring Cloud提供了多种选择的微服务链路追踪方案。以下是一些常用的方案:
-
Zipkin:Zipkin 是一个开源的分布式实时追踪系统,由 Twitter 开发并贡献给开源社区。Spring Cloud Sleuth 提供了与 Zipkin 的集成,可以通过在微服务中添加相应的依赖和配置,将追踪信息发送到 Zipkin 服务器,并通过 Zipkin UI 进行可视化展示和查询。

-
Jaeger:Jaeger 是 Uber 开源的分布式追踪系统,也被纳入了 CNCF(云原生计算基金会)的维护。通过使用 Spring Cloud Sleuth 和 Jaeger 客户端库,可以将追踪信息发送到 Jaeger 并进行可视化展示和查询。
-
SkyWalking:Apache SkyWalking 是一款开源的应用性能监控与分析系统,提供了对 Java、.NET 和 Node.js 等语言的支持。它可以与 Spring Cloud Sleuth 集成,将追踪数据发送到 SkyWalking 服务器进行可视化展示和分析

-
Pinpoint:Pinpoint 是 Naver 开源的分布式应用性能监控系统,支持 Java 和 .NET。它提供了与 Spring Cloud Sleuth 的集成,可以将追踪数据发送到 Pinpoint 服务器,并通过其 UI 进行分析和监控。这些方案都可以与 Spring Cloud Sleuth 进行集成,Spring Cloud Sleuth 是 Spring Cloud 中的一个组件,提供了在微服务调用时生成追踪信息的能力。
这些方案都可以与 Spring Cloud Sleuth 进行集成,Spring Cloud Sleuth 是 Spring Cloud 中的一个组件,提供了在微服务调用时生成追踪信息的能力。
分布式事务
30.Seata支持哪些模式的分布式事务?
-
AT(Atomikos)模式:AT模式是Seata默认支持的模式,也是最常用的模式之一。在AT模式下,Seata通过在业务代码中嵌入事务上下文,实现对分布式事务的管理。Seata会拦截并解析业务代码中的SQL语句,通过对数据库连接进行拦截和代理,实现事务的管理和协调。

-
TCC(Try-Confirm-Cancel)模式:TCC模式是一种基于补偿机制的分布式事务模式。在TCC模式中,业务逻辑需要实现Try、Confirm和Cancel三个阶段的操作。Seata通过调用业务代码中的Try、Confirm和Cancel方法,并在每个阶段记录相关的操作日志,来实现分布式事务的一致性。
-
SAGA模式:SAGA模式是一种基于事件驱动的分布式事务模式。在SAGA模式中,每个服务都可以发布和订阅事件,通过事件的传递和处理来实现分布式事务的一致性。Seata提供了与SAGA模式兼容的Saga框架,用于管理和协调分布式事务的各个阶段。

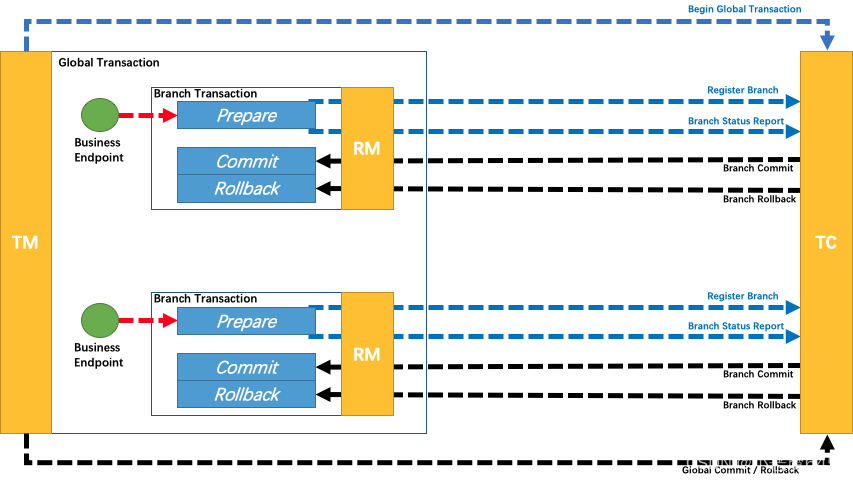
31.了解Seata的实现原理吗?
Seata的实现原理主要包括三个核心组件:事务协调器(Transaction Coordinator)、事务管理器(Transaction Manager)和资源管理器(Resource Manager)。
-
事务协调器(Transaction Coordinator):事务协调器负责协调和管理分布式事务的整个过程。它接收事务的开始和结束请求,并根据事务的状态进行协调和处理。事务协调器还负责记录和管理事务的全局事务 ID(Global Transaction ID)和分支事务 ID(Branch Transaction ID)。
-
事务管理器(Transaction Manager):事务管理器负责全局事务的管理和控制。它协调各个分支事务的提交或回滚,并保证分布式事务的一致性和隔离性。事务管理器还负责与事务协调器进行通信,并将事务的状态变更进行持久化。
-
资源管理器(Resource Manager):资源管理器负责管理和控制各个参与者(Participant)的事务操作。它与事务管理器进行通信,并根据事务管理器的指令执行相应的事务操作,包括提交和回滚。

Seata的实现原理基于两阶段提交(Two-Phase Commit)协议,具体的机制如下:
-
一阶段:在事务提交的过程中,首先进行预提交阶段。事务协调器向各个资源管理器发送预提交请求,资源管理器执行相应的事务操作并返回执行结果。在此阶段,业务数据和回滚日志记录在同一个本地事务中提交,并释放本地锁和连接资源。
Seata的事务执行流程是什么样的?
-
事务发起方(Transaction Starter)发起全局事务:事务发起方是指发起分布式事务的应用程序或服务。它向Seata的事务协调器发送全局事务的开始请求,生成全局事务ID(Global Transaction ID)。
-
事务协调器创建全局事务记录:事务协调器接收到全局事务的开始请求后,会为该事务创建相应的全局事务记录,并生成分支事务ID(Branch Transaction ID)。
-
分支事务注册:事务发起方将全局事务ID和分支事务ID发送给各个参与者(Participant),即资源管理器。参与者将分支事务ID注册到本地事务管理器,并将事务的执行结果反馈给事务协调器。
-
预提交阶段:事务发起方向事务协调器发送预提交请求,事务协调器将预提交请求发送给各个参与者。
-
全局事务提交或回滚:事务协调器根据参与者反馈的结果进行判断,如果所有参与者的本地事务都执行成功,事务协调器发送真正的提交请求给参与者,参与者执行最终的提交操作;如果有任何一个参与者的本地事务执行失败,事务协调器发送回滚请求给参与者,参与者执行回滚操作。
-
完成全局事务:事务协调器接收到参与者的提交或回滚结果后,根据结果更新全局事务的状态,并通知事务发起方全局事务的最终结果。
全局事务ID和分支事务ID是怎么传递的?
全局事务ID和分支事务ID在分布式事务中通过上下文传递的方式进行传递。常见的传递方式包括参数传递、线程上下文传递和消息中间件传递。具体的传递方式可以根据业务场景和技术选型进行选择和调整。
Seata的事务回滚是怎么实现的?

Seata的事务回滚是通过回滚日志实现的。每个参与者在执行本地事务期间生成回滚日志,记录了对数据的修改操作。
当需要回滚事务时,事务协调器向参与者发送回滚请求,参与者根据回滚日志中的信息执行撤销操作,将数据恢复到事务开始前的状态。
回滚日志的管理和存储是Seata的核心机制,可以选择将日志存储在不同的介质中。通过回滚日志的持久化和恢复,Seata确保了事务的一致性和恢复性。
服务监控
32.你们的服务怎么做监控和告警?
我们使用Prometheus和Grafana来实现整个微服务集群的监控和告警:
-
Prometheus:Prometheus 是一个开源的监控系统,具有灵活的数据模型和强大的查询语言,能够收集和存储时间序列数据。它可以通过HTTP协议定期拉取微服务的指标数据,并提供可扩展的存储和查询功能。
-
Grafana:Grafana 是一个开源的可视化仪表板工具,可以与 Prometheus 结合使用,创建实时和历史数据的仪表板。Grafana 提供了丰富的图表和可视化选项,可以帮助用户更好地理解和分析微服务的性能和状态。
33.你们的服务怎么做日志收集?
日志收集有很多种方案,我们用的是ELK:
-
Elasticsearch:Elasticsearch是一个分布式搜索和分析引擎,用于存储和索引大量的日志数据。它提供了快速的搜索和聚合功能,可以高效地处理大规模的日志数据。
-
Logstash:Logstash是一个用于收集、过滤和转发日志数据的工具。它可以从各种来源(如文件、网络、消息队列等)收集日志数据,并对数据进行处理和转换,然后将其发送到Elasticsearch进行存储和索引。
-
Kibana:Kibana是一个用于日志数据可视化和分析的工具。它提供了丰富的图表、仪表盘和搜索功能,可以帮助用户实时监控和分析日志数据,发现潜在的问题和趋势。
简单说,这三者里Elasticsearch提供数据存储和检索能力,Logstash负责将日志收集到ES,Kibana负责日志数据的可视化分析。
使用ELK进行微服务日志收集的一般流程如下:
-
使用Logstash收集日志:配置Logstash收集器,通过配置输入插件(如文件输入、网络输入等)监听微服务的日志输出,并进行过滤和处理。
-
将日志数据发送到Elasticsearch:配置Logstash的输出插件,将经过处理的日志数据发送到Elasticsearch进行存储和索引。
-
使用Kibana进行可视化和分析:通过Kibana连接到Elasticsearch,创建仪表盘、图表和搜索查询,实时监控和分析微服务的日志数据。
除了应用最广泛的ELK,还有一些其它的方案比如Fluentd、Graylog、Loki、Filebeat,一些云厂商也提供了付费方案,比如阿里云的sls。
原文地址:https://blog.csdn.net/qq_55640378/article/details/134684495
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10267.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!