项目介绍
有需要整个项目的可以私信博主,提供部署和讲解,对相关案例进行分析和深入剖析
本研究旨在利用Python的网络爬虫技术对豆瓣电影网站进行数据抓取,并通过合理的数据分析和清洗,将非结构化的数据转化为结构化的数据,以便于后续的大数据分析。
具体而言,我们通过分析豆瓣网站的网页结构,设计出规则来获取电影数据的JSON数据包,并采用正态分布的延时措施对数据进行大量获取,从而避免IP被禁。在数据清洗方面,我们进行了空值检测与处理、字符串约束、字段值扩充等操作,使得数据变得更加准确和可靠。接着,我们利用Hadoop中的Hive组件进行大数据分析,对电影数据进行结构化分析、喜爱程度分析、趋势分析等,从多维度角度分析数据集的价值,同时也了解了Hive中的结构化查询方法。
通过Hadoop中的flume组件和HDFS自动加载存储数据,并编写shell脚本进行一键化加载和分析,采用MapReduce执行方法对大量数据进行分析,最终通过可视化展示分析结果,使得研究具备了更好的可读性和可视化效果。因此,本研究通过综合运用Python、Hadoop和数据分析等技术手段,实现了高效的数据抓取和分析,并对数据进行了清洗和可视化展示,为后续的大数据分析提供了有力支持。
研究背景
随着互联网的普及和电子商务的发展,数据已经成为了企业和机构中不可或缺的一部分,数据分析和挖掘也成为了各行各业中不可或缺的一种技术手段。因此,如何高效地获取大量的数据并进行分析成为了当前的一个研究热点。而随着互联网的发展,人们对于电影的需求也越来越高,因此,电影数据分析也成为了热门的研究方向之一。
豆瓣电影是一个广受欢迎的电影网站,拥有着庞大的用户群体和海量的电影资源。通过对豆瓣电影的数据进行抓取清洗和大数据分析,不仅可以帮助人们更好地了解电影市场的现状和趋势,还可以为电影从业者提供一定的参考和决策支持。
本研究基于Python网络爬虫技术,通过设计合理的规则,实现了对豆瓣电影网站的数据抓取。同时,在数据清洗方面,我们通过空值检测、字符串约束和字段值扩充等操作,使得数据变得更加准确和可靠。
在大数据分析方面,本研究利用Hadoop中的Hive组件进行了数据结构化分析、喜爱程度分析和趋势分析等多维度分析,并通过可视化展示了分析结果,使得数据更加易于理解和应用。同时,通过Hadoop中的flume组件和HDFS自动加载存储数据,并编写shell脚本进行一键化加载和分析,采用MapReduce执行方法对大量数据进行分析,提高了数据分析的效率和准确性。
本研究的结果不仅可以为电影从业者提供一定的参考和决策支持,还可以为电影爱好者提供更好的了解和选片建议。此外,本研究所采用的技术手段也可以为其他领域的数据分析提供一定的参考和借鉴。
国内外研究现状分析
随着互联网和移动设备的普及,人们越来越依赖于在线资源来获取信息、进行娱乐和购物。在这个过程中,豆瓣电影作为一款电影信息网站,提供了大量的电影资源和相关信息。因此,针对豆瓣电影数据的抓取、清洗和分析已成为一个热门话题,研究者们采用了各种技术手段进行探索。
在国内方面,关于豆瓣电影数据抓取和分析的研究已经取得了一些进展。李峥等人在2017年提出了一种基于Python的豆瓣电影数据爬取方法,通过调用API接口获取豆瓣电影数据,实现了数据抓取和清洗。此外,张旗等人在2018年提出了一种基于Hadoop和Hive的豆瓣电影数据分析方法,利用Hadoop集群进行数据存储和处理,并采用Hive进行数据分析和查询。这些研究表明,在国内已经有不少学者使用Python和大数据技术进行豆瓣电影数据的研究,取得了一些成果。
在国外方面,豆瓣电影的研究也受到了一定的关注。例如,I. Lai等人在2018年提出了一种基于深度学习的电影评论情感分析方法,通过对豆瓣电影的评论进行情感分析,研究了用户对电影的情感偏好。此外,N. P. Luong等人在2019年提出了一种基于自然语言处理的电影主题挖掘方法,通过对豆瓣电影的评论进行文本分析,挖掘出了一些主题和关键词。这些研究表明,国外学者也在豆瓣电影数据的分析方面有所涉猎,并尝试将深度学习和自然语言处理等技术应用于豆瓣电影的研究。
总的来说,针对豆瓣电影数据的抓取、清洗和分析已经成为一个热门话题,国内外学者都在进行各种尝试。国内学者主要采用Python和大数据技术进行研究,而国外学者则更倾向于使用深度学习和自然语言处理等技术。无论是采用何种技术手段,对豆瓣电影数据的研究都为我们提供了更好的了解电影市场和用户需求的机会。
研究目的
本研究旨在通过对豆瓣电影的数据抓取、清洗及大数据分析可视化,深入了解电影市场的趋势和消费者需求,为电影从业人员提供决策参考,同时也为观众提供更好的电影选择建议。具体目的包括以下几个方面:
(1)了解电影市场的概况和趋势
通过对豆瓣电影的数据分析,了解电影市场的总体情况,包括电影类型、制片国家、票房收入、用户评分等方面,进而掌握市场趋势和潜在的商业机会。比如,从分析豆瓣电影的数据可以看出,近年来科幻类电影的市场需求不断增长,这为相关电影从业人员提供了重要的决策参考。
(2)分析电影类型与用户评分的关系
通过对豆瓣电影的数据进行分析,可以了解不同类型电影的用户评分情况,并从中探索电影类型和用户评分之间的关系。比如,我们可以分析喜剧类电影和动作类电影的用户评分情况,并尝试找出影响用户评分的因素,为电影从业人员提供指导和建议。
(3)探究电影制片国家与用户评分的关系
通过对豆瓣电影的数据进行分析,可以了解不同制片国家的电影在用户评分方面的表现,并从中探索制片国家和用户评分之间的关系。比如,我们可以分析中国电影和美国电影的用户评分情况,并尝试找出影响用户评分的因素,为电影从业人员提供指导和建议。
(4)分析电影票房收入与用户评分的关系
通过对豆瓣电影的数据进行分析,可以了解电影票房收入与用户评分之间的关系,并从中探索影响票房收入的因素。比如,我们可以分析票房收入高的电影与用户评分高的电影之间的关系,并尝试找出影响票房收入的因素,为电影从业人员提供指导和建议。
(5)制作电影数据可视化图表
通过对豆瓣电影的数据进行可视化处理,制作出各种图表和可视化工具,为电影从业人员和观众提供更加直观和易懂的数据呈现方式,帮助他们更好地了解电影市场的趋势和消费者需求。比如,我们可以制作出电影类型分布图、电影票房收入排名图、电影评分分布图等多种图表,以便更好地展现豆瓣电影的数据。
(6)探索用户对电影的喜好和需求
通过对豆瓣电影的用户评分数据进行分析,可以深入了解用户对电影的喜好和需求,从而为电影从业人员提供更好的决策参考。比如,我们可以分析用户对某一电影类型的偏好、对电影评分的时间分布等因素,从中找出用户需求的规律,为电影从业人员提供更好的服务和产品。
总之,本研究旨在通过对豆瓣电影的数据进行抓取、清洗及大数据分析可视化,深入了解电影市场的趋势和消费者需求,为电影从业人员提供更好的决策参考,同时也为观众提供更好的电影选择建议。
研究意义
近年来,随着人们对电影的需求不断增加,电影产业发展迅速,数据挖掘、分析和可视化也逐渐成为了电影行业的重要组成部分。豆瓣电影是一个包含丰富电影信息和用户评价的平台,通过对其数据进行抓取清洗和分析可视化,可以得到很多有价值的结论,对电影行业发展具有重要的研究意义。
首先,豆瓣电影数据的抓取和清洗可以帮助我们深入了解电影行业的市场需求和消费趋势。通过抓取豆瓣电影的电影基本信息、评价数据等,可以分析不同类型电影的受欢迎程度、影评的评价趋势等。例如,通过对豆瓣电影TOP250的分析可以发现,豆瓣电影用户更喜欢国外电影和文艺片,且高分电影的排名更容易受到用户的短期评价波动的影响。
其次,对豆瓣电影数据的分析和可视化可以帮助电影从业者更好地制定市场策略和推广方案。通过对电影的评价数据和用户画像数据的分析,可以了解电影受众的喜好和需求,从而针对性地制定市场营销策略和宣传推广方案。例如,对某部电影的豆瓣评价数据进行情感分析,可以了解电影在不同类型受众中的好评度,从而制定更有效的宣传策略。
第三,豆瓣电影数据的分析还可以帮助我们了解电影行业的影响力和发展趋势。通过对电影上映时间、票房和评价数据的分析,可以了解电影的受欢迎程度和影响力,并推测电影市场的未来发展趋势。例如,通过对电影上映时间的分析可以发现,国产电影在国内市场的影响力正在逐渐增强,同时,好莱坞电影的票房占比也在不断增加,这为电影从业者制定未来发展战略提供了重要的参考。
最后,豆瓣电影数据的抓取和分析可以为电影评论、推荐等应用提供基础数据和支撑,有助于提升电影观影体验。例如,通过对用户历史评分数据的分析,可以为用户推荐更符合其口味的电影,从而提升用户观影体验。
综上,豆瓣电影数据的抓取、清洗、分析和可视化在电影行业的研究中具有重要的作用和意义,可以帮助我们更好地了解电影市场、推动电影产业发展、提升电影观影体验等方面,具体有以下几个方面的研究意义:
(1)帮助电影行业更好地了解市场需求和消费趋势。通过对豆瓣电影数据的分析,可以了解不同类型电影的受欢迎程度和影评的评价趋势,从而更好地了解市场需求和消费趋势。
(2)帮助电影从业者制定更有效的市场营销策略和宣传推广方案。通过对电影的评价数据和用户画像数据的分析,可以了解电影受众的喜好和需求,从而针对性地制定市场营销策略和宣传推广方案。
(3)帮助电影行业了解电影的影响力和发展趋势。通过对电影上映时间、票房和评价数据的分析,可以了解电影的受欢迎程度和影响力,并推测电影市场的未来发展趋势。
(4)提升电影观影体验。通过对用户历史评分数据的分析,可以为用户推荐更符合其口味的电影,从而提升用户观影体验。
(5)推动电影产业的发展。通过对电影数据的抓取、清洗、分析和可视化,可以更好地推动电影产业的发展,促进电影产业的数字化和智能化发展。
因此,本文旨在通过对豆瓣电影数据的抓取、清洗、分析和可视化,深入研究电影市场的需求和消费趋势、制定更有效的市场营销策略和宣传推广方案、了解电影的影响力和发展趋势、提升电影观影体验以及推动电影产业的数字化和智能化发展等方面,为电影行业提供有价值的数据支撑和参考,从而更好地推动电影产业的发展和提升用户观影体验。
研究总体设计
本研究旨在通过综合运用Python、Hadoop和数据分析等技术手段,实现对豆瓣电影网站的数据抓取、清洗和分析,为后续的大数据分析提供有力支持。具体而言,研究设计如下:
一、数据抓取 通过Python的网络爬虫技术,设计出规则获取豆瓣电影网站的电影数据JSON数据包。采用正态分布的延时措施,避免IP被禁。最终将非结构化数据转化为结构化数据。
二、数据清洗 对抓取的数据进行空值检测与处理、字符串约束、字段值扩充等操作,使数据更加准确和可靠。
三、数据存储 使用Hadoop中的Hive组件进行数据存储,并采用MapReduce执行方法对大量数据进行分析。
四、数据分析 在数据存储完成后,对电影数据进行结构化分析、喜爱程度分析、趋势分析等。从多维度角度分析数据集的价值,同时也了解Hive中的结构化查询方法。
五、数据可视化 通过Hadoop中的flume组件和HDFS自动加载存储数据,并编写shell脚本进行一键化加载和分析,最终通过可视化展示分析结果,使得研究具备更好的可读性和可视化效果。
总的来说,本研究的总体设计包括数据抓取、数据清洗、数据存储、数据分析和数据可视化五个部分。通过综合运用Python、Hadoop和数据分析等技术手段,实现对豆瓣电影网站的数据抓取、清洗和分析,从而为后续的大数据分析提供有力支持。

数据获取
网络爬虫介绍
Python是一种通用的高级编程语言,其在网络爬虫方面具有出色的表现,因此被广泛应用于网络爬虫的开发。网络爬虫是一种程序,可以自动地从网络上爬取数据,并将这些数据进行处理、分析、存储等操作。Python的网络爬虫具有以下优势:
省略…
豆瓣电影数据的采集
豆瓣电影是一家备受欢迎的电影评分网站,提供大量电影信息。为了获取这些信息,需要使用网络爬虫技术对豆瓣电影官网进行分析,爬取每部电影的数据。在此过程中,我们发现豆瓣电影的数据是通过动态点击不断获取的。经过解析,我们找到了一个包含页面信息和字段的JSON数据包。
省略…
数据预处理
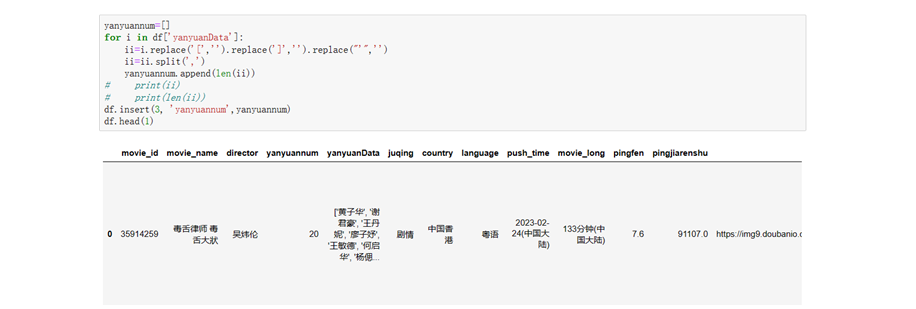
使用爬虫获取的数据满足大数据分析的基本条件,但对于某些字段需要进一步处理。例如,在电影名称中,需要去除逗号以便于在后续导入到Hive仓库中使用CSV格式并使用逗号分隔导入数据时不会出现错位数据,从而不会影响分析结果。此外,需要对某些字段的值进行扩展和约束。例如,电影时长中包含中文,演员信息中包含大量人员。我们可以使用以下方法对数据进行预处理和结构化处理:
省略…
数据导入及环境配置
Flume介绍
Flume是一种可靠、高可用的分布式系统,用于在数据源和目的地之间可靠地收集、聚合和移动大量数据。Flume是Apache软件基金会下的开源软件,最初由Cloudera公司开发。它主要用于将数据从不同来源收集到Hadoop分布式存储系统中,以便进行大数据分析。
Flume基于流式数据流模型,它将数据源分为三个主要组件:source、channel和sink。source是数据源,它从外部系统中接收数据并将其转换为可处理的格式。channel是数据在Flume中的缓冲区,用于暂时存储数据并确保数据在传输过程中不会丢失。sink是数据的目的地,它将数据发送到指定的位置,例如HDFS、HBase或其他存储系统。
Flume支持多种数据源和目的地,包括文件、日志、syslog、Avro、Kafka和Netcat等。Flume还提供了一系列插件,可以方便地扩展其功能,例如拦截器、转换器和序列化器等。
Flume的优点在于它具有高度可靠性、可扩展性和容错性。它可以轻松处理大量的数据流,并可靠地将其传输到指定的目的地。此外,Flume具有灵活的配置和管理功能,可以根据具体的需求对其进行定制和配置。
总之,Flume是一款非常适合大规模数据收集和传输的工具,特别是对于需要将数据移动到Hadoop分布式存储系统中进行处理和分析的企业和组织而言,Flume是非常有价值的工具。
Hive介绍
Hive是一个开源的数据仓库解决方案,基于Hadoop的分布式计算技术。Hive提供了一个SQL-like查询语言(HQL),允许用户使用类SQL语句来查询和管理大规模的分布式数据。这使得Hive成为一个强大的工具,可用于处理大数据集和实现数据分析、ETL(Extract, Transform, Load)和数据挖掘等任务。
Hive的核心组件是一个数据存储和查询引擎,它可以处理包括结构化、半结构化和非结构化数据在内的各种类型的数据。Hive将数据存储在Hadoop分布式文件系统(HDFS)中,并将数据处理任务转换为Hadoop MapReduce任务进行执行。这种设计使得Hive能够利用Hadoop的强大分布式计算能力,从而能够轻松地处理海量数据。
Hive的查询语言HQL与标准SQL相似,但它还支持一些Hadoop特有的语句和功能。例如,Hive可以使用自定义函数(UDF)和用户定义的聚合函数(UDAF)来扩展其查询语言。此外,Hive还支持复杂数据类型和嵌套查询,以帮助用户更轻松地处理大规模的数据集。
Hive还提供了一个用户友好的Web界面和命令行界面,使得用户可以方便地使用Hive进行数据管理和查询。此外,Hive还可以与其他开源的数据处理工具,如Pig和Spark等集成使用,以实现更复杂的数据处理任务。
总之,Hive是一个强大的数据仓库解决方案,可用于处理大规模数据集和实现数据分析、ETL和数据挖掘等任务。
MySQL介绍
MySQL是一种开源的关系型数据库管理系统(RDBMS),它是一种用于存储和管理数据的软件,通常用于在网站和应用程序中管理数据。MySQL支持大多数操作系统,并且可以与多种编程语言集成。MySQL有许多功能,包括事务处理、触发器、存储过程、视图和安全性,可以帮助用户在应用程序中高效地存储和管理数据。
MySQL的特点之一是其可扩展性。MySQL可以扩展到多台服务器上,以提高处理大量数据和用户请求的能力。MySQL还具有快速读取和写入数据的优势,这使得它成为许多大型网站和应用程序的首选数据库之一。此外,MySQL具有较低的成本,因为它是一个开源软件,并且拥有庞大的开发者社区,可以提供支持和帮助。
省略…
Pyecharts介绍
Pyecharts是一个基于Python语言的开源数据可视化库,提供了一系列数据可视化的工具和组件,支持多种图表类型,包括折线图、柱状图、散点图、饼图、地图等。Pyecharts通过简单易用的API,方便用户快速创建并定制自己的数据可视化图表。
Pyecharts主要特点如下:
(1)开源:Pyecharts是一个开源的数据可视化库,所有的代码都可以在GitHub上获取。
(2)多种图表类型:Pyecharts支持多种图表类型,包括折线图、柱状图、散点图、饼图、地图等。
(3)多种数据格式支持:Pyecharts支持多种数据格式,包括常见的CSV、JSON、Excel等格式。
(4)易于使用:Pyecharts通过简单易用的API,方便用户快速创建并定制自己的数据可视化图表。
(5)自定义主题:Pyecharts提供了多个主题,用户可以根据自己的需求选择或自定义自己的主题。
(6)与Jupyter Notebook集成:Pyecharts与Jupyter Notebook集成,方便用户在Notebook中进行数据可视化操作。
Pyecharts可以用于数据分析和可视化,从而更好地展示研究结果和结论。例如,可以使用Pyecharts创建柱状图或折线图来展示数据的趋势和变化,使用饼图展示数据的比例关系,使用地图展示区域分布等等。此外,Pyecharts还提供了丰富的交互功能,如鼠标悬停、缩放、拖拽等,可以让数据可视化更加生动、直观。
总之,Pyecharts是一个功能强大、易于使用的数据可视化库,可以为研究者提供有力的支持和工具,帮助他们更好地进行数据分析和可视化,从而更好地展示研究结果和结论。
环境配置及数据加载
为了提高效率并方便大量程序处理环境下的项目部署,我们可以编写脚本来自动创建文件夹、开启服务以及监听窗口。这样就可以避免每个shell都需要手动输入,节省了大量时间。这种方法经常被使用,能够帮助我们更好地理解和快速地部署项目工程。
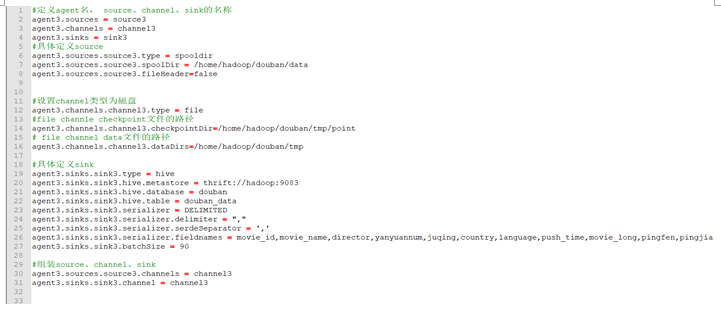
Flume代理的配置文件定义了名为agent3的代理,其中包括源(source)、通道(channel)和汇(sink)的名称。 source3是一个类型为spooldir的源,从/home/hadoop/douban/data目录中读取数据,不使用文件头(file header)。 agent3的通道类型设置为文件(file),并指定了checkpoint文件和data文件的路径。 Hive sink的名称为sink3,将数据写入到名为douban_data的Hive表中,该表位于名为douban的Hive数据库中。该sink使用DELIMITED序列化器,指定字段之间的分隔符(delimiter)和Serde之间的分隔符(serde separator),以及要写入Hive表的字段名称。批量大小(batchSize)设置为90。 最后,source3与channel3关联,sink3与channel3关联,以便数据可以从source3通过channel3传递到sink3。 在Hive中,可以使用以下建表语句来建立表格。

启动Hive Metastore服务和Flume监听的步骤如下:
(1)启动Hive Metastore服务,监听端口号9083,使用命令:hive —service metastore -p 9083。Hive Metastore是Hive的元数据存储服务,负责管理Hive表格的元数据信息,如表格结构、分区信息、文件系统位置等。数据存储在HDFS中,元数据存储在Hive Metastore中。运行该命令可以启动Hive Metastore服务,并连接到该服务以管理和查询Hive表格。
(2)启动Flume监听,使用命令:flume-ng agent —conf conf —conf–file file_hive.properties –name agent3 -Dflume.hadoop.logger=INFO,console。Flume是一个数据采集、传输和存储系统,可将不同来源的数据传输到不同的目的地。该命令启动一个名为agent3的Flume agent,使用指定的配置文件file_hive.properties,具体的数据源和目的地信息需要在配置文件中指定。
(3)将数据移动到之前建立的文件夹下,即可完成数据的自动导入。
省略…

大数据分析及可视化
豆瓣影评结构化分析
豆瓣电影类型占比分析
豆瓣电影导演排行榜分析
不同国家的电影数据分析
电影演员阵容数量分析
电影时长分析
不同语种的电影统计分析
不同时间维度下统计分析
电影评价人数可视化分析
文本可视化分析

总结
本研究综合运用了Python、Hadoop和数据分析等技术手段,实现了高效的数据抓取和分析,并对数据进行了清洗和可视化展示。通过本研究的实践和探索,我们深刻地认识到了数据分析在当今信息化社会中的重要性和应用价值。
在本研究中,我们以豆瓣电影网站为例,通过Python的网络爬虫技术实现了数据抓取,并对数据进行了合理的清洗和约束,使得非结构化的数据转化为了结构化的数据,为后续的大数据分析打下了基础。在数据分析方面,我们运用Hadoop中的Hive组件进行了结构化分析、喜爱程度分析、趋势分析等多维度的分析,从不同的角度探索了数据集的价值和意义。同时,我们还通过Hadoop中的flume组件和HDFS实现了自动化加载和存储数据,并采用MapReduce执行方法对大量数据进行了分析,提高了数据处理的效率和速度。
值得一提的是,在本研究中,我们还通过可视化手段对分析结果进行了展示,使得研究具备了更好的可读性和可视化效果。利用Pyecharts等可视化工具,我们将电影的关键字和主题、情感色彩、人物关系网络等以图表或词云的形式进行了展示,让观众可以更加直观地了解数据分析结果。
综上所述,本研究的贡献主要体现在以下几个方面:
一、实现了高效的数据抓取和分析。通过Python的网络爬虫技术,我们成功地抓取了豆瓣电影网站的数据,并通过清洗和约束使得数据变得更加准确和可靠。同时,我们还运用Hadoop中的Hive组件和MapReduce执行方法对数据进行了多维度的分析,为后续的大数据分析提供了有力的支持。
二、采用了可视化手段对分析结果进行了展示。通过Pyecharts等可视化工具,我们将数据分析结果以图表或词云的形式进行了展示,使得研究具备了更好的可读性和可视化效果。
三、探索了数据分析在当今信息化社会中的应用价值。通过本研究的实践和探索,我们深刻地认识到了数据分析在当今信息化社会中的重要性和应用价值,为相关领域的发展提供了参考和借鉴。
总之,本总之,本研究通过综合运用Python、Hadoop和数据分析等技术手段,实现了对豆瓣电影网站数据的高效抓取和分析,并对数据进行了清洗和可视化展示。在实践和探索中,我们发现数据分析在当今信息化社会中的应用价值越来越高,对各行各业的发展起到了至关重要的作用。数据分析不仅可以帮助企业和组织更好地了解市场和用户需求,还可以帮助政府制定更加科学和精准的政策,促进社会的进步和发展。
当然,本研究还存在一些局限性和不足之处,需要进一步的改进和完善。首先,在数据抓取方面,我们需要更加完善的延时措施和IP代理池,以避免被网站屏蔽和限制;其次,在数据清洗方面,我们需要更加严格的约束和规范,以确保数据的准确性和可靠性;最后,在数据分析方面,我们需要更加深入的挖掘和分析,以获取更多的有价值的信息和洞察。
针对上述问题和不足之处,我们将在后续的研究中进行进一步的探索和完善,以期更好地发挥数据分析在信息化社会中的应用价值,为人类社会的发展和进步作出更大的贡献。
每文一语
快乐的源泉在于不断的前行!
原文地址:https://blog.csdn.net/weixin_47723732/article/details/131417531
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10827.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!