Pytorch完整的模型训练套路
使用适当的库加载数据集,例如torchvision、TensorFlow的tf.data等。
将数据集分为训练集和测试集,并进行必要的预处理,如归一化、数据增强等。
创建机器学习模型,可以是深度神经网络、传统机器学习模型或其它模型类型。
定义模型架构,包括输入层、隐藏层和输出层的结构、激活函数、损失函数等。
定义适当的损失函数来计算模型预测结果于真实标签之间的差异。
选择适当的优化器算法来更新模型参数,如随机梯度下降(SGD)、Adam等。
从训练集中获取一批样本数据,并将其输入模型进行前向传播。
计算损失函数,并根据损失函数进行反向传播和参数更新。
重复以上步骤,直到达到预定的训练次数或达到收敛条件。
从测试集中获取一批样本数据,并将其输入模型进行前向传播。
计算损失函数或评估指标,用于评估模型在测试集上的性能。
使用适当的工具或库记录训练过程中的损失值、准确率、评估指标等。
- 结束训练步骤
根据训练结束条件、例如达到预定的训练次数或收敛条件,结束训练。可以保存模型参数或整个模型,以便日后部署和使用。
以CIFAR10为例实践
import torch
import torchvision
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
'''数据集加载'''
train_data = torchvision.datasets.CIFAR10(root='dataset',train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root='dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 训练数据集的长度
train_data_size = len(train_data)
print(f"训练数据集的长度为:{train_data_size}")
# 测试数据集的长度
test_data_size = len(test_data)
print(f"测试数据集的长度:{test_data_size}")
#利用DataLoader加载数据集
train_dataloader = DataLoader(test_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度为:50000
测试数据集的长度:10000
‘’‘创建模型’‘’
以上篇文章《Pytorch损失函数、反向传播和优化器、Sequential使用》中的BS()为例
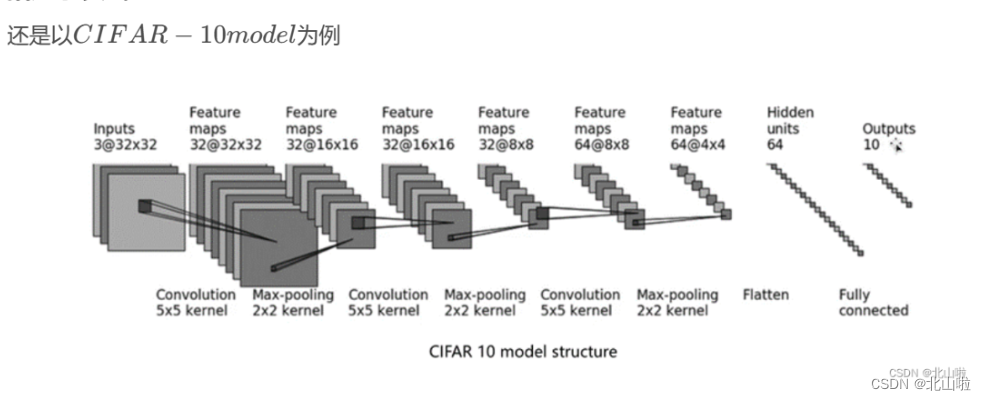
'''创建模型'''
class BS(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3,
out_channels=32,
kernel_size=5,
stride=1,
padding=2), #stride和padding计算得到
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,
out_channels=32,
kernel_size=5,
stride=1,
padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=32,
out_channels=64,
kernel_size=5,
padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Flatten(), #in_features变为64*4*4=1024
nn.Linear(in_features=1024, out_features=64),
nn.Linear(in_features=64, out_features=10),
)
def forward(self,x):
x = self.model(x)
return x
bs = BS()
print(bs)
BS(
(model): Sequential(
(0): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=1024, out_features=64, bias=True)
(8): Linear(in_features=64, out_features=10, bias=True)
)
)
'''定义损失函数和优化器'''
# 使用交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 1e-2 #学习率0.01
optimizer = torch.optim.SGD(bs.parameters(), lr=learning_rate)
"""
训练循环步骤
"""
# 开始设置训练神经网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
writer = SummaryWriter(".logs") #Tensorboard可视化
for i in range(epoch):
print("----第{}轮训练开始----".format(i))
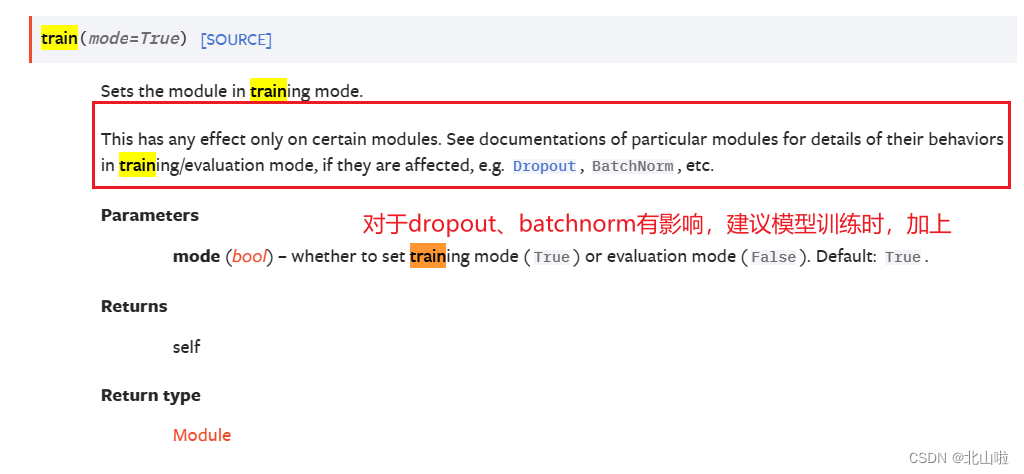
#bs.train() # bs.train()#有batchnorm、dropout层需要调用。官方文档见torch.nn.Module
'''训练步骤开始'''
for data in train_dataloader:
imgs, targets = data
outputs = bs(imgs)
loss = loss_fn(outputs, targets)
optimizer.zero_grad() # 首先要梯度清零
loss.backward() #得到梯度
optimizer.step() #进行优化
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step,loss.item()))
writer.add_scalar("train_loss", loss.item(),total_train_step)
'''测试步骤开始'''
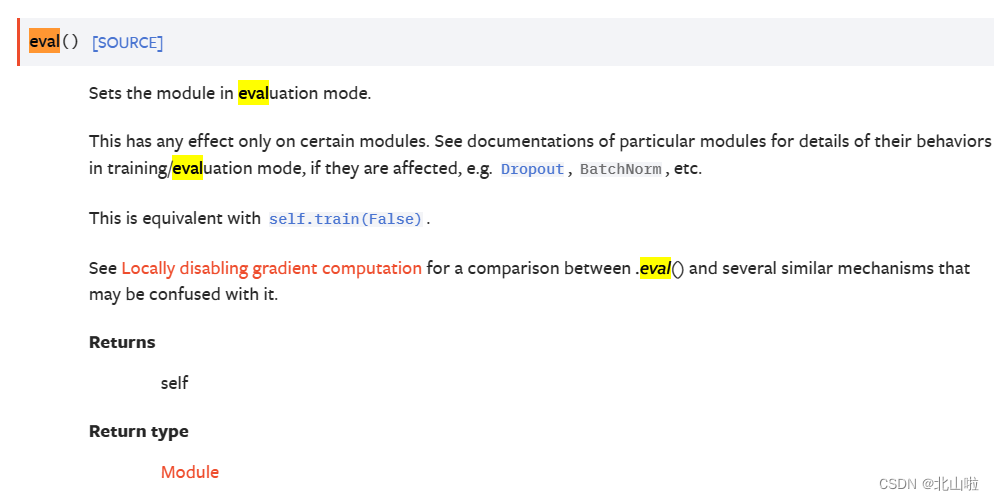
#bs.eval() # bs.train()#有batchnorm、dropout层需要调用。官方文档见torch.nn.Module
total_test_loss = 0
#total_accuracy
total_accuracy = 0
with torch.no_grad():#torch.no_grad()是一个上下文管理器,用来禁止梯度的计算,通常用来网络推断中,它可以减少计算内存的使用量。
for imgs, targets in test_dataloader:
outputs = bs(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item() #.item()取出数字
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
"""测试过程的记录和输出"""
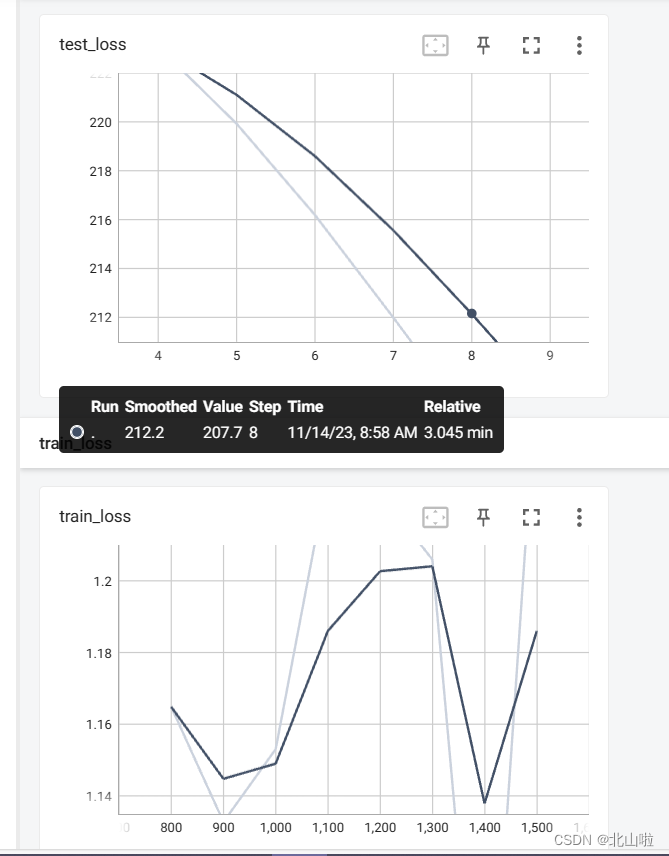
print("整体测试集上损失函数loss:{}".format(total_test_loss))
print("整体测试集上正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar('test_accuracy',total_accuracy/test_data_size)
total_test_step = total_test_step + 1
torch.save(bs, "test_{}.pth".format(i))
print("模型已保存")
"""
结束训练步骤
"""
writer.close()
补充.item()
- .item()
import torch
a = torch.tensor(5)
print(a)
print(a.item())
tensor(5)
5
原文地址:https://blog.csdn.net/qq_45176548/article/details/134529377
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_10927.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!