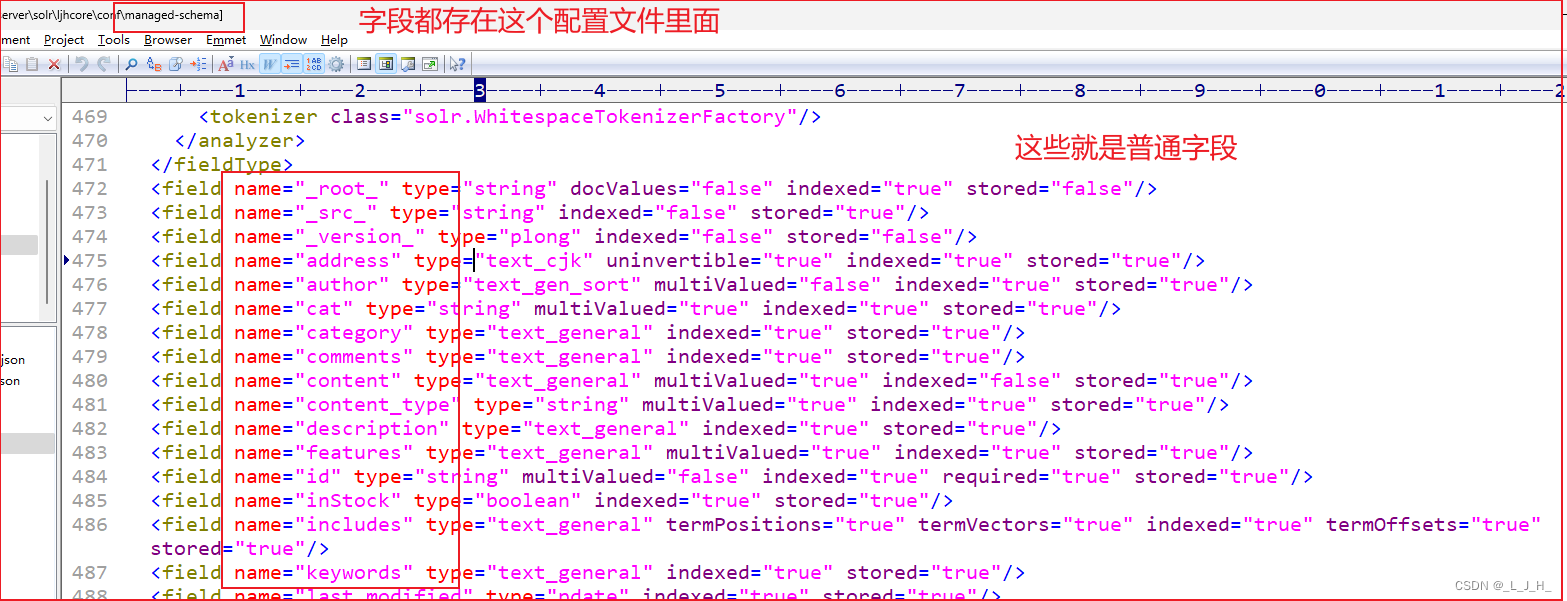
一、全文检索查询
1、match查询
语法:
2、multi_match查询
语法:
3、match和mult_match的区别
二、精确查询
1、term查询:
语法:
2、range查询:(范围查询)
语法:
三、地理查询
1、geo_bounding_box查询:
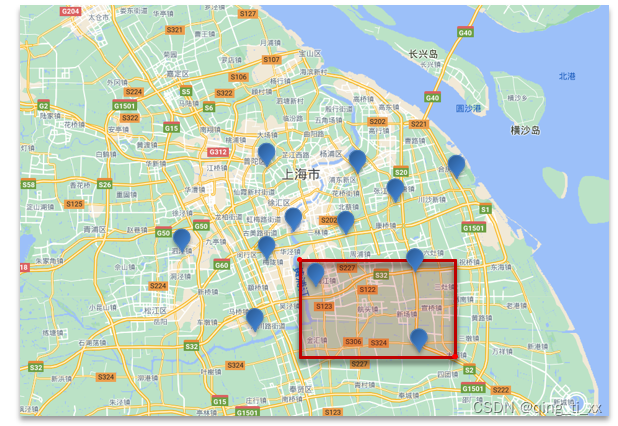
语法:
2、geo_distance查询:
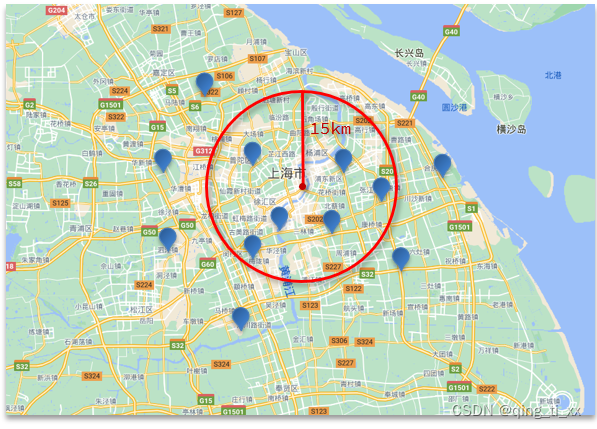
语法:
四、复合查询
1、fuction score:
(1)词条频率

(2)TF-IDF算法

(3)BM25算法

2、总结

五、Function Score Query
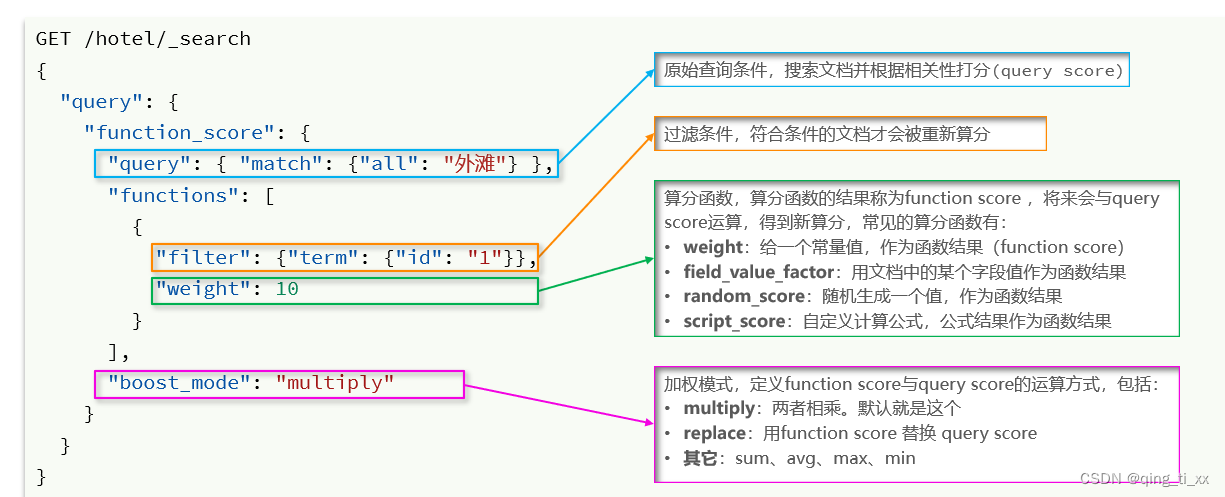
1、bool查询

声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。