译者:飞龙
本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。
真相一旦入眼,你就再也无法视而不见。——《黑客帝国》
一、GO:学起来简单,但很难掌握
本章涵盖
犯错是每个人生活的一部分。正如阿尔伯特·爱因斯坦曾经说过的,
最终重要的不是我们犯了多少错误,而是我们从错误中学习的能力。这个断言也适用于编程。我们在一门语言中获得的资历并不是一个神奇的过程;它包括犯许多错误,并从中吸取教训。这本书的目的就是围绕这个想法。它将帮助你,读者,成为一个更熟练的 Go 开发者,通过观察和学习人们在语言的许多领域中犯的 100 个常见错误。
这一章快速回顾了为什么GO这么多年来成为主流。我们将讨论为什么尽管GO被认为简单易学,但掌握它的细微差别却很有挑战性。最后,我们将介绍本书涵盖的概念。
1.1 Go 大纲
如果你正在读这本书,很可能你已经爱上了 Go。因此,本节提供了一个简短的提示,是什么让 Go 成为如此强大的语言。
在过去的几十年里,软件工程有了长足的发展。大多数现代系统不再是由一个人编写的,而是由多个程序员组成的团队编写的——有时甚至是数百人,如果不是数千人的话。如今,代码必须具有可读性、表达性和可维护性,以保证系统的持久性。同时,在我们这个快速发展的世界中,最大限度地提高灵活性和缩短上市时间对于大多数组织来说至关重要。编程也应该遵循这一趋势,公司努力确保软件工程师在阅读、编写和维护代码时尽可能地高效。
为了应对这些挑战,谷歌在 2007 年创建了 Go 编程语言。从那时起,许多组织已经采用这种语言来支持各种用例:API、自动化、数据库、CLI(命令行界面)等等。今天许多人认为 Go 是云的语言。
就特性而言,Go 没有类型继承、没有异常、没有宏、没有部分函数、不支持惰性变量求值或不变性、没有运算符重载、没有模式匹配等等。为什么语言中缺少这些特性?官方的 Go FAQ (go.dev/doc/faq)给了我们一些启示:
为什么 Go 没有特征 X?您最喜欢的功能可能会丢失,因为它不合适,因为它影响编译速度或设计的清晰度,或者因为它会使基本的系统模型太难。
通过特性的数量来判断编程语言的质量可能不是一个准确的标准。至少,这不是GO的目标。相反,当组织大规模采用一种语言时,Go 利用了一些基本特征。其中包括以下内容:
-
稳定性——虽然 Go 经常更新(包括改进和安全补丁),但它仍然是一种稳定的语言。有些人甚至认为这是这门语言最好的特性之一。
-
表现性——我们可以通过我们如何自然和直观地编写和读取代码来定义编程语言中的表现性。数量减少的关键字和解决常见问题的有限方法使 Go 成为大型代码库的一种表达性语言。
-
编译——作为开发人员,还有什么比等待构建来测试我们的应用更让人恼火的呢?快速编译一直是语言设计者有意识的目标。这反过来又提高了生产率。
Go 是从底层开始构建的,具有可靠的特性,比如具有 goroutines 和通道的出色的并发原语。不太需要依赖外部库来构建高效的并发应用。观察并发性在这些日子里是多么重要,也证明了为什么 Go 对于现在和可预见的将来都是如此合适的语言。
一些人也认为 Go 是一种简单的语言。从某种意义上说,这并不一定是错的。例如,一个新手可以在不到一天的时间里学会这门语言的主要特征。那么,如果GO很简单,为什么要读一本以错误概念为中心的书呢?
1.2 简单并不意味着容易
简单和容易是有细微差别的。简单,应用于一项技术,意思是学习或理解起来不复杂。然而,容易意味着我们不需要太多努力就可以实现任何事情。GO学起来简单,但不一定容易掌握。
让我们以并发性为例。2019 年,一项专注于并发 bug 的研究发表了:“理解 Go 中真实世界的并发 bug。¹” 这项研究是首次对并发 bug 的系统分析。它关注多个流行的 Go 存储库,比如 Docker、gRPC 和 Kubernetes。这项研究中最重要的一点是,大多数阻塞错误都是由通过通道的消息传递范式的不正确使用引起的,尽管人们认为消息传递比共享内存更容易处理,更不容易出错。
对于这样的外卖,应该有什么合适的反应?我们应该认为语言设计者在消息传递方面是错误的吗?我们是否应该重新考虑如何处理项目中的并发性?当然不是。
这不是一个对抗信息传递和共享内存并决定谁是赢家的问题。然而,作为 Go 开发人员,我们需要彻底了解如何使用并发性,它对现代处理器的影响,何时支持一种方法,以及如何避免常见的陷阱。这个例子强调了虽然像通道和 goroutines 这样的概念很容易学习,但在实践中却不是一个容易的话题。
这个主题——简单并不意味着容易——可以推广到 Go 的许多方面,而不仅仅是并发性。因此,要成为精通GO的开发者,我们必须对这门语言的许多方面有透彻的理解,这需要时间、精力和错误。
这本书旨在通过深入研究 100 个 Go 错误来帮助我们加速迈向熟练的旅程。
1.3 100 个 Go 错误
我们为什么要读一本关于常见GO错误的书?为什么不用一本挖掘不同主题的普通书来加深我们的知识呢?
在 2011 年的一篇文章中,神经科学家证明了大脑生长的最佳时间是我们面临错误的时候。我们都经历过从一个错误中学习的过程,并且在几个月甚至几年后回忆起那个事件,当一些背景与它相关时?正如珍妮特·梅特卡夫(Janet Metcalfe)在另一篇文章中介绍的那样,这种情况的发生是因为错误具有促进效应。主要意思是我们不仅能记住错误,还能记住错误周围的上下文。这是从错误中学习如此高效的原因之一。
为了加强这种促进作用,本书尽可能多地用真实世界的例子来说明每个错误。这本书不仅仅是关于理论;它还帮助我们更好地避免错误,做出更明智、更有意识的决策,因为我们现在理解了它们背后的基本原理。
告诉我,我会忘记。教我,我会记住。让我参与进来,我会学到东西。
——未知
这本书提出了七大类错误。总的来说,这些错误可以归类为
1.3.1 错误
第一种错误可能也是最明显的错误是软件错误。2020 年,Synopsys 进行的一项研究估计,仅在美国,软件错误的成本就超过 2 万亿美元⁴。
此外,错误还会导致悲剧性的影响。例如,我们可以提到加拿大原子能有限公司(AECL)生产的 Therac-25 放射治疗机。由于比赛条件,这台机器给病人的辐射剂量超过预期数百倍,导致三名病人死亡。因此,软件错误不仅仅是钱的问题。作为开发人员,我们应该记住我们的工作是多么有影响力。
这本书涵盖了大量可能导致各种软件错误的案例,包括数据竞争、泄漏、逻辑错误和其他缺陷。虽然准确的测试应该是尽早发现这类 bug 的一种方式,但我们有时可能会因为时间限制或复杂性等不同因素而错过案例。因此,作为一名 Go 开发者,确保我们避免常见的错误是至关重要的。
1.3.2 不必要的复杂性
下一类错误与不必要的复杂性有关。软件复杂性的一个重要部分来自于这样一个事实,即作为开发人员,我们努力思考想象中的未来。与其现在就解决具体的问题,不如构建进化的软件来解决未来出现的任何用例。然而,在大多数情况下,这样做弊大于利,因为这会使代码库变得更加复杂,难以理解和推理。
回到过去,我们可以想到许多用例,在这些用例中,开发人员可能倾向于为未来需求设计抽象,比如接口或泛型。这本书讨论了我们应该小心不要用不必要的复杂性伤害代码库的主题。
1.3.3 可读性较弱
另一种错误是削弱可读性。正如 Robert C. Martin 在他的书《Clean Code:A Handbook of Agile Software crafts》中所写的,花在阅读和写作上的时间比远远超过 10 比 1。我们大多数人开始在可读性不那么重要的单独项目上编程。然而,今天的软件工程是有时间维度的编程:确保我们在几个月、几年,甚至几十年后仍然可以使用和维护应用。
在用 Go 编程时,我们可能会犯很多会损害可读性的错误。这些错误可能包括嵌套代码、数据类型表示,或者在某些情况下没有使用命名结果参数。通过这本书,我们将学习如何编写可读的代码,并关心未来的读者(包括我们未来的自己)。
1.3.4 次优或不适应的组织
无论是在进行一个新项目时,还是因为我们获得了不准确的反应,另一种错误是次优地和单向地组织我们的代码和项目。这样的问题会使项目更难推理和维护。这本书涵盖了GO中的一些常见错误。例如,我们将了解如何构建一个项目,以及如何处理实用工具包或init函数。总之,查看这些错误应该有助于我们更有效、更习惯地组织我们的代码和项目。
1.3.5 缺乏 API 便利性
另一种类型的错误是犯一些削弱 API 对客户的便利性的常见错误。如果一个 API 不是用户友好的,它将缺乏表现力,因此更难理解,更容易出错。
我们可以考虑许多情况,比如过度使用any类型,使用错误的创建模式来处理选项,或者盲目应用影响我们 API 可用性的面向对象编程的标准实践。这本书涵盖了一些常见的错误,这些错误阻止我们向用户公开方便的 API。
1.3.6 优化不足的代码
优化不足的代码是开发人员犯的另一种错误。这可能是由于各种原因造成的,比如不理解语言特征,甚至缺乏基础知识。性能是这个错误最明显的影响之一,但不是唯一的。
我们可以考虑为其他目标优化代码,比如准确性。例如,这本书提供了一些确保浮点运算准确的常用技术。与此同时,我们将讨论大量可能对性能代码产生负面影响的情况,例如,由于并行化执行不佳,不知道如何减少分配,或者数据对齐的影响。我们将通过不同的棱镜解决优化问题。
1.3.7 缺乏生产力
在大多数情况下,当我们着手一个新项目时,我们能选择的最佳语言是什么?我们工作效率最高的一个。熟悉一门语言的工作方式并充分利用它是达到熟练的关键。
在本书中,我们将介绍许多案例和具体的例子,这些案例和例子将帮助我们在 Go 中工作时更有效率。例如,我们将着眼于编写高效的测试来确保我们的代码工作,依靠标准库来提高效率,并充分利用分析工具和 linters。现在,是时候深入研究这 100 个常见的GO错误了。
总结
-
GO学起来简单,但不容易掌握。这就是为什么我们需要加深我们的知识来最有效地使用语言。
¹ T. Tu,X. Liu 等,“理解 Go 中真实世界的并发 bug”,发表于 2019 年 4 月 13 日-17 日的 ASPLOS 2019。
J. S. Moser,H. S. Schroder 等人,“注意你的错误:将成长心态与适应性后错误调整联系起来的神经机制的证据”,《心理科学》,第 22 卷,第 12 期,第 1484-1489 页,2011 年 12 月。
³ J. Metcalfe,“从错误中学习”,《心理学年度评论》,第 68 卷,第 465–489 页,2017 年 1 月。
⁴ Synopsys,“美国软件质量差的代价:2020 年报告。”2020. news.synopsys.com/2021-01-06-Synopsys-Sponsored-CISQ-Research-Estimates-Cost-of-Poor-Software-Quality-in-the-US-2-08-Trillion-in-2020 。
R. C. Martin,《干净的代码:敏捷软件工艺手册》。普伦蒂斯霍尔,2008 年。
二、代码和项目组织
本章涵盖
以一种干净、惯用和可维护的方式组织 Go 代码库并不是一件容易的事情。理解所有与代码和项目组织相关的最佳实践需要经验,甚至是错误。要避免哪些陷阱(例如,变量隐藏和嵌套代码滥用)?我们如何构造包?我们何时何地使用接口或泛型、init函数和实用工具包?在这一章中,我们检查常见的组织错误。
2.1 #1:意外的变量隐藏
变量的作用域指的是变量可以被引用的地方:换句话说,就是应用中名字绑定有效的部分。在 Go 中,块中声明的变量名可以在内部块中重新声明。这个原理叫做变量隐藏,容易出现常见错误。
以下示例显示了由于隐藏变量而产生的意外副作用。它以两种不同的方式创建 HTTP 客户端,这取决于一个tracing布尔值:
var client *http.Client // ❶
if tracing {
client, err := createClientWithTracing() // ❷
if err != nil {
return err
}
log.Println(client)
} else {
client, err := createDefaultClient() // ❸
if err != nil {
return err
}
log.Println(client)
}
// Use client
❷ 创建一个启用了跟踪的 HTTP 客户端。(client变量在此块中被隐藏。)
❸ 创建一个默认的 HTTP 客户端。(client变量在这个块中也被隐藏。)
在这个例子中,我们首先声明一个client变量。然后,我们在两个内部块中使用短变量声明操作符(:=)将函数调用的结果分配给内部client变量——而不是外部变量。因此,外部变量总是nil。
注意这段代码会编译,因为内部的client变量会在日志调用中使用。如果没有,我们就会出现client declared and not used等编译错误。
我们如何确保给原始的client变量赋值呢?有两种不同的选择。
var client *http.Client
if tracing {
c, err := createClientWithTracing() // ❶
if err != nil {
return err
}
client = c // ❷
} else {
// Same logic
}
这里,我们将结果赋给一个临时变量c,它的范围只在if块内。然后,我们将它赋回给client变量。同时,我们对else部分做同样的工作。
第二个选项使用内部程序块中的赋值运算符(=)将函数结果直接赋给client变量。然而,这需要创建一个error变量,因为赋值操作符只有在已经声明了变量名的情况下才起作用。例如:
var client *http.Client
var err error // ❶
if tracing {
client, err = createClientWithTracing() // ❷
if err != nil {
return err
}
} else {
// Same logic
}
❶ 声明了一个err变量
❷ 使用赋值操作符给*http赋值。客户端直接返回到client变量
不用先赋给一个临时变量,我们可以直接把结果赋给client。
两种选择都完全有效。这两个选项之间的主要区别是,我们在第二个选项中只执行一个赋值,这可能被认为更容易阅读。同样,使用第二个选项,我们可以在if / else语句之外共同化和实现错误处理,如下例所示:
if tracing {
client, err = createClientWithTracing()
} else {
client, err = createDefaultClient()
}
if err != nil {
// Common error handling
}
当在内部块中重新声明变量名时,会出现变量隐藏,但是我们看到这种做法容易出错。强加一个禁止隐藏变量的规则取决于个人喜好。例如,有时重用现有的变量名(如err)来处理错误会很方便。然而,总的来说,我们应该保持谨慎,因为我们现在知道我们可能会面临这样的场景:代码可以编译,但是接收值的变量不是预期的变量。在本章的后面,我们还将看到如何检测隐藏变量,这可能有助于我们发现可能的错误。
2.2 #2:不必要的嵌套代码
应用于软件的心智模型是系统行为的内部表示。在编程时,我们需要维护心智模型(例如,关于整体代码交互和功能实现)。基于多种标准,如命名、一致性、格式等,代码被限定为可读的。可读代码需要较少的认知努力来维护心智模型;因此,它更容易阅读和维护。
可读性的一个重要方面是嵌套层次的数量。让我们做一个练习。假设我们正在进行一个新项目,需要理解下面的join函数是做什么的:
func join(s1, s2 string, max int) (string, error) {
if s1 == "" {
return "", errors.New("s1 is empty")
} else {
if s2 == "" {
return "", errors.New("s2 is empty")
} else {
concat, err := concatenate(s1, s2) // ❶
if err != nil {
return "", err
} else {
if len(concat) > max {
return concat[:max], nil
} else {
return concat, nil
}
}
}
}
}
func concatenate(s1 string, s2 string) (string, error) {
// ...
}
❶ 调用concatenate函数来执行某些特定的连接,但可能会返回错误
这个join函数连接两个字符串,如果长度大于max,则返回一个子字符串。同时,它处理对s1和s2的检查,以及对concatenate的调用是否返回错误。
从实现的角度来看,这个函数是正确的。然而,建立一个包含所有不同情况的心智模型可能不是一件简单的任务。为什么?因为嵌套层次的数量。
现在,让我们使用相同的函数,但以不同的方式再次尝试这个练习:
func join(s1, s2 string, max int) (string, error) {
if s1 == "" {
return "", errors.New("s1 is empty")
}
if s2 == "" {
return "", errors.New("s2 is empty")
}
concat, err := concatenate(s1, s2)
if err != nil {
return "", err
}
if len(concat) > max {
return concat[:max], nil
}
return concat, nil
}
func concatenate(s1 string, s2 string) (string, error) {
// ...
}
你可能已经注意到,尽管做着和以前一样的工作,但构建这个新版本的心智模型需要的认知负荷更少。这里我们只维护两个嵌套层次。正如 Mat Ryer 在 Go Time 播客(medium.com/@matryer/line-of-sight-in-code-186dd7cdea88)中提到的:
向左对齐幸福路径;您应该很快能够向下扫描一列,以查看预期的执行流。
由于嵌套的if / else语句,在第一个版本中很难区分预期的执行流。相反,第二个版本需要向下扫描一列来查看预期的执行流,向下扫描第二列来查看边缘情况是如何处理的,如图 2.1 所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jLhqM96X-1684395314253)(…/…/OEBPS/Images/CH02_F01_Harsanyi.png)]
图 2.1 为了理解预期的执行流程,我们只需浏览一下快乐路径列。
一般来说,函数需要的嵌套层次越多,阅读和理解起来就越复杂。让我们看看这条规则的一些不同应用,以优化我们的代码可读性:
-
当一个
if块返回时,我们应该在所有情况下省略else块。例如,我们不应该写if foo() { // ... return true } else { // ... }相反,我们像这样省略了
else块:if foo() { // ... return true } // ...在这个新版本中,先前在
else块中的代码被移到顶层,使其更容易阅读。 -
if s != "" { // ... } else { return errors.New("empty string") }if s == "" { // ❶ return errors.New("empty string") } // ...❶翻转了
if条件这个新版本更容易阅读,因为它将快乐路径保留在左边,并减少了块数。
编写可读的代码对每个开发人员来说都是一个重要的挑战。努力减少嵌套块的数量,将快乐路径放在左边,尽可能早地返回,这些都是提高代码可读性的具体方法。
在下一节中,我们将讨论 Go 项目中一个常见的误用:init函数。
2.3 #3:误用init函数
有时我们会在 Go 应用中误用init函数。潜在的后果是糟糕的错误管理或更难理解的代码流。让我们重温一下什么是init函数。然后,我们将会看到它的用法是否被推荐。
2.3.1 概念
init函数是用于初始化应用状态的函数。它不接受任何参数,也不返回任何结果(一个func()函数)。当一个包被初始化时,包中所有的常量和变量声明都会被求值。然后,执行init函数。下面是一个初始化main包的例子:
package main
import "fmt"
var a = func() int {
fmt.Println("var") // ❶
return 0
}()
func init() {
fmt.Println("init") // ❷
}
func main() {
fmt.Println("main") // ❸
}
❶ 首先被执行
❷ 其次被执行
❸ 最后被执行
var
init
main
初始化软件包时会执行init函数。在下面的例子中,我们定义了两个包,main和redis,其中main依赖于redis。首先,主要的。从main包开始:
package main
import (
"fmt"
"redis"
)
func init() {
// ...
}
func main() {
err := redis.Store("foo", "bar") // ❶
// ...
}
package redis
// imports
func init() {
// ...
}
func Store(key, value string) error {
// ...
}
因为main依赖于redis,所以首先执行redis包的init函数,然后是main包的init,然后是的main函数本身。图 2.2 显示了这个顺序。
我们可以为每个包定义多个init函数。当我们这样做时,包内init函数的执行顺序是基于源文件的字母顺序。例如,如果一个包包含一个a.go文件和一个b.go文件,并且这两个文件都有一个init函数,则首先执行a.go init函数。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0T7jwTdA-1684395314255)(…/…/OEBPS/Images/CH02_F02_Harsanyi.png)]
图 2.2 首先执行redis包的init函数,然后是main的init函数,最后是的main函数。
我们不应该依赖包中init函数的排序。事实上,这可能很危险,因为源文件可能会被重命名,从而潜在地影响执行顺序。
我们也可以在同一个源文件中定义多个init函数。例如,这段代码完全有效:
package main
import "fmt"
func init() { // ❶
fmt.Println("init 1")
}
func init() { // ❷
fmt.Println("init 2")
}
func main() {
}
❶ 第一个init函数
❷ 第二个init函数
执行的第一个init函数是源代码顺序中的第一个。以下是输出结果:
init 1
init 2
我们也可以使用init函数来产生副作用。在下一个例子中,我们定义了一个main包,它对foo没有很强的依赖性(例如,没有直接使用公共函数)。然而,这个例子需要初始化foo包。我们可以这样使用_操作符:
package main
import (
"fmt"
_ "foo" // ❶
)
func main() {
// ...
}
在这种情况下,foo包在main之前初始化。因此,执行foo的init函数。
init函数的另一个特点是它不能被直接调用,如下例所示:
package main
func init() {}
func main() {
init() // ❶
}
❶ 无效引用
这段代码会产生以下编译错误:
$ go build .
./main.go:6:2: undefined: init
既然我们已经了解了init函数是如何工作的,那么让我们看看什么时候应该使用或者不使用它们。下一节将对此进行阐述。
2.3.2 何时使用init函数
首先,让我们看一个使用init函数被认为不合适的例子:持有数据库连接池。在示例中的init函数中,我们使用sql.Open打开一个数据库。我们使这个数据库成为一个全局变量,其他函数以后可以使用:
var db *sql.DB
func init() {
dataSourceName :=
os.Getenv("MYSQL_DATA_SOURCE_NAME") // ❶
d, err := sql.Open("mysql", dataSourceName)
if err != nil {
log.Panic(err)
}
err = d.Ping()
if err != nil {
log.Panic(err)
}
db = d // ❷
}
❶ 环境变量
在本例中,我们打开数据库,检查是否可以 ping 它,然后将它赋给全局变量。我们应该如何看待这个实现?让我们描述三个主要的缺点。
首先,init函数中的错误管理是有限的。事实上,由于init函数不返回错误,发出错误信号的唯一方式就是恐慌,导致应用停止。在我们的例子中,如果打开数据库失败,无论如何停止应用也是可以的。然而,不应该由包本身来决定是否停止应用。也许调用者可能更喜欢实现重试或使用回退机制。在这种情况下,在init函数中打开数据库会阻止客户端包实现它们的错误处理逻辑。
另一个重要的缺点与测试有关。如果我们向这个文件添加测试,init函数将在运行测试用例之前执行,这不一定是我们想要的(例如,如果我们在一个不需要创建这个连接的实用函数上添加单元测试)。因此,本例中的init函数使编写单元测试变得复杂。
最后一个缺点是,该示例要求将数据库连接池分配给一个全局变量。全局变量有一些严重的缺点;例如:
在大多数情况下,我们应该倾向于封装一个变量,而不是保持它的全局。
出于这些原因,之前的初始化可能应该作为普通旧函数的一部分来处理,如下所示:
func createClient(dsn string) (*sql.DB, error) { // ❶
db, err := sql.Open("mysql", dsn)
if err != nil {
return nil, err // ❷
}
if err = db.Ping(); err != nil {
return nil, err
}
return db, nil
}
❷ 返回一个错误
有必要不惜一切代价避免init函数吗?不完全是。在一些用例中,init函数仍然是有用的。例如,官方的 Go 博客(mng.bz/PW6w)使用init函数来设置静态 HTTP 配置:
func init() {
redirect := func(w http.ResponseWriter, r *http.Request) {
http.Redirect(w, r, "/", http.StatusFound)
}
http.HandleFunc("/blog", redirect)
http.HandleFunc("/blog/", redirect)
static := http.FileServer(http.Dir("static"))
http.Handle("/favicon.ico", static)
http.Handle("/fonts.css", static)
http.Handle("/fonts/", static)
http.Handle("/lib/godoc/", http.StripPrefix("/lib/godoc/",
http.HandlerFunc(staticHandler)))
}
在这个例子中,init函数不会失败(http.HandleFunc可能会恐慌,但只有在处理器是nil的情况下才会恐慌,但这里的情况不是这样)。同时,不需要创建任何全局变量,该函数不会影响可能的单元测试。因此,这个代码片段提供了一个很好的例子,说明了init函数的用处。总之,我们看到init函数会导致一些问题:
我们应该谨慎使用init函数。然而,在某些情况下,它们会很有帮助,比如定义静态配置,正如我们在本节中看到的。否则,在大多数情况下,我们应该通过特殊函数来处理初始化。
2.4 #4:过度使用获取器和设置器
在编程中,数据封装是指隐藏一个对象的值或状态。获取器和设置器是通过在未导出的对象字段上提供导出的方法来启用封装的方法。
在 Go 中,没有像我们在一些语言中看到的那样自动支持获取器和设置器。使用获取器和设置器来访问结构字段也被认为既不强制也不习惯。例如,标准库实现了这样的结构,其中一些字段可以直接访问,例如作为time.Timer结构:
timer := time.NewTimer(time.Second)
<-timer.C // ❶
尽管不推荐,我们甚至可以直接修改C(但是我们不会再接收事件了)。然而,这个例子说明了标准的 Go 库并不强制使用获取器和/或设置器,即使我们不应该修改一个字段。
另一方面,使用获取器和设置器有一些优点,包括:
-
它们隐藏了内部表现,让我们在展示时更加灵活。
如果我们陷入这些情况或者预见到一个可能的用例,同时保证向前兼容,使用获取器和设置器可以带来一些价值。例如,如果我们将它们用于一个名为balance的字段,我们应该遵循这些命名约定:
这里有一个例子:
currentBalance := customer.Balance() // ❶
if currentBalance < 0 {
customer.SetBalance(0) // ❷
}
❶ 获取器
❷ 设置器
总之,如果结构上的获取器和设置器没有带来任何价值,我们就不应该用它们来淹没我们的代码。我们应该务实,努力在效率和遵循习惯用法之间找到正确的平衡,这些习惯用法在其他编程范例中有时被认为是无可争议的。
请记住,Go 是一种独特的语言,它具有许多特性,包括简单性。然而,如果我们发现需要获取器和设置器,或者,如前所述,在保证向前兼容性的同时预见到未来的需要,使用它们没有任何问题。
2.5 #5:接口污染
在设计和构建我们的代码时,接口是 Go 语言的基石之一。然而,像许多工具或概念一样,滥用它们通常不是一个好主意。接口污染就是用不必要的抽象来淹没我们的代码,使代码更难理解。这是来自不同习惯的另一种语言的开发人员经常犯的错误。在深入探讨这个话题之前,我们先来回顾一下 Go 的接口。然后,我们将看到什么时候使用接口是合适的,什么时候它可能被认为是污染。
2.5.1 概念
接口提供了一种指定对象行为的方式。我们使用接口来创建多个对象可以实现的公共抽象。使 Go 接口如此不同的是它们被隐式地满足了。没有像implements这样明确的关键字来标记一个对象X实现了接口Y。
为了理解是什么让接口如此强大,我们将从标准库中挖掘两个流行的接口:io.Reader和io.Writer。io包为 I/O 原语提供了抽象。在这些抽象中,io.Reader与从数据源读取数据有关,io.Writer与向目标写入数据有关,如图 2.3 所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-50NZjSB4-1684395314255)(…/…/OEBPS/Images/CH02_F03_Harsanyi.png)]
图 2.3 io.Reader从数据源读取并填充一个字节切片,而io.Writer从一个字节切片写入目标。
io.Reader包含一个单个Read方法:
type Reader interface {
Read(p []byte) (n int, err error)
}
接口的定制实现应该接受一个字节切片,用它的数据填充它,并返回读取的字节数或一个错误。
另一方面,io.Writer定义了单个方法,Write:
type Writer interface {
Write(p []byte) (n int, err error)
}
io.Writer的定制实现应该将来自一个片的数据写入一个目标,并返回写入的字节数或一个错误。因此,这两个接口都提供了基本的抽象:
语言中有这两个接口的基本原理是什么?创建这些抽象的目的是什么?
假设我们需要实现一个将一个文件的内容复制到另一个文件的函数。我们可以创建一个特定的函数,将两个*os.File作为输入。或者,我们可以选择使用io.Reader和io.Writer抽象来创建一个更加通用的函数:
func copySourceToDest(source io.Reader, dest io.Writer) error {
// ...
}
这个函数将与*os.File参数一起工作(因为*os.File实现了io.Reader和io.Writer)以及实现这些接口的任何其他类型。例如,我们可以创建自己的写入数据库的io.Writer,而代码保持不变。它增加了函数的通用性;因此,它的可重用性。
此外,为这个函数编写单元测试更加容易,因为我们可以使用strings和bytes包,而提供了有用的实现,而不是处理文件:
func TestCopySourceToDest(t *testing.T) {
const input = "foo"
source := strings.NewReader(input) // ❶
dest := bytes.NewBuffer(make([]byte, 0)) // ❷
err := copySourceToDest(source, dest) // ❸
if err != nil {
t.FailNow()
}
got := dest.String()
if got != input {
t.Errorf("expected: %s, got: %s", input, got)
}
}
❶ 创建了一个io.Reader
❷ 创建了一个io.Writer
❸ 从*strings、io.Reader和io.Writer调用copySourceToDest。
在本例中,source是一个*strings.Reader,而dest是一个*bytes.Buffer。这里,我们在不创建任何文件的情况下测试copySourceToDest的行为。
在设计接口时,粒度(接口包含多少方法)也是需要记住的。Go (www.youtube.com/watch?v=PAAkCSZUG1c&t=318s)中一个众所周知的谚语与一个接口应该有多大有关:
接口越大,抽象越弱。
——罗布·派克
事实上,向接口添加方法会降低接口的可重用性。io.Reader和io.Writer是强大的抽象,因为它们不能再简单了。此外,我们还可以结合细粒度的接口来创建更高级别的抽象。io.ReadWriter就是这种情况,它结合了读者和作者的行为:
type ReadWriter interface {
Reader
Writer
}
注正如爱因斯坦所说,“一切都应该尽可能简单,但不能再简单了。”应用于接口,这意味着找到接口的完美粒度不一定是一个简单的过程。
现在让我们讨论推荐接口的常见情况。
2.5.2 何时使用接口
我们应该什么时候在 Go 中创建接口?让我们看三个具体的用例,在这些用例中,接口通常被认为是带来价值的。请注意,我们的目标并不是详尽无遗的,因为我们添加的案例越多,它们就越依赖于上下文。然而,这三个案例应该给我们一个大致的概念:
-
普通行为
-
解耦
-
限制行为
普通行为
我们将讨论的第一个选项是当多个类型实现一个公共行为时使用接口。在这种情况下,我们可以分析出接口内部的行为。如果我们看看标准库,我们可以找到许多这样的用例的例子。例如,可以通过三种方法对集合进行排序:
type Interface interface {
Len() int // ❶
Less(i, j int) bool // ❷
Swap(i, j int) // ❸
}
元素的❶数
❷ 检查了两个要素
❸ 互换了两个元素
这个接口具有很强的可重用性,因为它包含了对任何基于索引的集合进行排序的通用行为。
纵观sort包,我们可以找到几十个实现。例如,如果在某个时候我们计算了一个整数集合,并且我们想对它进行排序,我们有必要对实现类型感兴趣吗?排序算法是归并排序还是快速排序重要吗?很多时候,我们并不在意。因此,排序行为可以被抽象出来,我们可以依赖于sort.Interface。
找到正确的抽象来分解行为也可以带来很多好处。例如,sort包提供了同样依赖于sort.Interface的实用函数,比如检查集合是否已经排序。举个例子,
func IsSorted(data Interface) bool {
n := data.Len()
for i := n - 1; i > 0; i-- {
if data.Less(i, i-1) {
return false
}
}
return true
}
因为sort.Interface是正确的抽象层次,所以它非常有价值。
现在让我们看看使用接口的另一个主要用例。
退耦
另一个重要的用例是关于从实现中分离我们的代码。如果我们依赖一个抽象而不是一个具体的实现,实现本身可以被另一个代替,甚至不需要改变我们的代码。这就是利斯科夫替代原理(Robert C. Martin 的 SOLID 设计原理中的 L)。
解耦的一个好处与单元测试有关。让我们假设我们想要实现一个CreateNewCustomer方法来创建一个新客户并存储它。我们决定直接依赖于具体的实现(比如说一个mysql.Store结构):
type CustomerService struct {
store mysql.Store // ❶
}
func (cs CustomerService) CreateNewCustomer(id string) error {
customer := Customer{id: id}
return cs.store.StoreCustomer(customer)
}
❶ 取决于具体的实现
现在,如果我们想测试这个方法呢?因为customerService依赖于实际的实现来存储一个Customer,我们不得不通过集成测试来测试它,这需要构建一个 MySQL 实例(除非我们使用另一种技术,比如go-sqlmock,但这不是本节的范围)。尽管集成测试很有帮助,但这并不总是我们想要做的。为了给我们更多的灵活性,我们应该将CustomerService从实际的实现中分离出来,这可以通过这样的接口来实现:
type customerStorer interface { // ❶
StoreCustomer(Customer) error
}
type CustomerService struct {
storer customerStorer // ❷
}
func (cs CustomerService) CreateNewCustomer(id string) error {
customer := Customer{id: id}
return cs.storer.StoreCustomer(customer)
}
❶ 创建了存储抽象
因为存储一个客户现在是通过一个接口完成的,这给了我们更多的灵活性来测试这个方法。例如,我们可以
现在让我们讨论另一个用例:限制一个行为。
限制行为
我们将讨论的最后一个用例乍一看可能非常违反直觉。它是关于将一个类型限制到一个特定的行为。假设我们实现了一个定制的配置包来处理动态配置。我们通过一个IntConfig结构为int配置创建一个特定的容器,该结构还公开了两个方法:Get和Set。下面是代码的样子:
type IntConfig struct {
// ...
}
func (c *IntConfig) Get() int {
// Retrieve configuration
}
func (c *IntConfig) Set(value int) {
// Update configuration
}
现在,假设我们收到一个IntConfig,它保存了一些特定的配置,比如一个阈值。然而,在我们的代码中,我们只对检索配置值感兴趣,并且我们希望防止更新它。如果我们不想改变我们的配置包,我们怎么能强制这个配置在语义上是只读的呢?通过创建一个抽象,将行为限制为仅检索配置值:
type intConfigGetter interface {
Get() int
}
然后,在我们的代码中,我们可以依靠intConfigGetter而不是具体的实现:
type Foo struct {
threshold intConfigGetter
}
func NewFoo(threshold intConfigGetter) Foo { // ❶
return Foo{threshold: threshold}
}
func (f Foo) Bar() {
threshold := f.threshold.Get() // ❷
// ...
}
❶ intConfigGetter
❷ 读取配置
在这个例子中,配置获取器被注入到NewFoo工厂方法中。它不会影响这个函数的客户端,因为它仍然可以在实现intConfigGetter时传递一个IntConfig结构。然后,我们只能读取Bar方法中的配置,不能修改。因此,出于各种原因,我们也可以使用接口将类型限制为特定的行为,例如语义强制。
在本节中,我们看到了三个潜在的用例,其中接口通常被认为是有价值的:分解出一个公共行为,创建一些解耦,以及将一个类型限制到某个特定的行为。同样,这个列表并不详尽,但是它应该让我们对接口在 Go 中的作用有一个大致的了解。
现在,让我们结束这一节,讨论接口污染的问题。
2.5.3 接口污染
在 Go 项目中过度使用接口是很常见的。也许开发人员的背景是 C#或 Java,他们发现在具体类型之前创建接口是很自然的。然而,这并不是GO的工作方式。
正如我们所讨论的,接口是用来创建抽象的。当编程遇到抽象时,主要的警告是记住抽象应该被发现,而不是被创建。这是什么意思?这意味着如果没有直接的理由,我们就不应该开始在代码中创建抽象。我们不应该设计接口,而应该等待具体的需求。换句话说,我们应该在需要的时候创建接口,而不是在预见到可能需要的时候。
如果我们过度使用接口,主要问题是什么?答案是它们使代码流更加复杂。增加一个无用的间接层不会带来任何价值;它创建了一个毫无价值的抽象,使得代码更难阅读、理解和推理。如果我们没有添加接口的充分理由,并且不清楚接口如何使代码更好,我们应该质疑这个接口的用途。为什么不直接调用实现?
注意当我们通过一个接口调用一个方法时,我们也可能经历性能开销。它需要在哈希表的数据结构中查找,以找到接口指向的具体类型。但是在很多情况下这不是问题,因为开销很小。
总之,在我们的代码中创建抽象时,我们应该谨慎——抽象应该被发现,而不是被创建。对于我们这些软件开发人员来说,基于我们认为以后可能需要的东西,通过试图猜测什么是完美的抽象层次来过度工程化我们的代码是很常见的。应该避免这个过程,因为在大多数情况下,它用不必要的抽象污染了我们的代码,使其阅读起来更加复杂。
不要设计接口,去发现它们。
——抢派克
让我们不要试图抽象地解决问题,而是解决现在必须解决的问题。最后,但同样重要的是,如果不清楚一个接口如何使代码变得更好,我们可能应该考虑删除它以使我们的代码更简单。
下一节继续这个主题,并讨论一个常见的接口错误:在生成器端创建接口。
2.6 #6:生产者方面的接口
我们在上一节中看到了接口被认为是有价值的。但是 Go 开发者经常会误解一个问题:一个接口应该活在哪里?
在深入探讨这个主题之前,让我们确保我们在本节中使用的术语是清楚的:
-
生产者端——与具体实现定义在同一个包中的接口(见图 2.4)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HB8cn5w2-1684395314256)(…/…/OEBPS/Images/CH02_F04_Harsanyi.png)]
图 2.4 接口是在具体实现的旁边定义的。
-
消费者端——在使用它的外部包中定义的接口(参见图 2.5)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Et6tl6rc-1684395314256)(…/…/OEBPS/Images/CH02_F05_Harsanyi.png)]
图 2.5 接口是在使用的地方定义的。
常见的是,开发人员在具体实现的同时,在生产者端创建接口。这种设计可能是具有 C#或 Java 背景的开发人员的习惯。但在GO中,大多数情况下这并不是我们应该做的。
让我们讨论下面的例子。这里,我们创建一个特定的包来存储和检索客户数据。同时,仍然在同一个包中,我们决定所有的调用都必须通过以下接口:
package store
type CustomerStorage interface {
StoreCustomer(customer Customer) error
GetCustomer(id string) (Customer, error)
UpdateCustomer(customer Customer) error
GetAllCustomers() ([]Customer, error)
GetCustomersWithoutContract() ([]Customer, error)
GetCustomersWithNegativeBalance() ([]Customer, error)
}
我们可能认为我们有一些很好的理由在生产者端创建和公开这个接口。也许这是将客户端代码从实际实现中分离出来的好方法。或者,也许我们可以预见它将帮助客户创建测试替身。不管是什么原因,这都不是GO的最佳实践。
如前所述,接口在 Go 中是隐式满足的,与具有显式实现的语言相比,Go 往往是游戏规则的改变者。在大多数情况下,要遵循的方法类似于我们在上一节中描述的:抽象应该被发现,而不是被创建。这意味着不能由生产者来为所有客户强制一个给定的抽象。相反,由客户决定是否需要某种形式的抽象,然后确定满足其需求的最佳抽象级别。
在前面的例子中,也许一个客户端对解耦它的代码不感兴趣。也许另一个客户想要解耦它的代码,但是只对GetAllCustomers方法感兴趣。在这种情况下,这个客户机可以用一个方法创建一个接口,从外部包中引用Customer结构:
package client
type customersGetter interface {
GetAllCustomers() ([]store.Customer, error)
}
-
因为
customersGetter接口只在client包中使用,所以可以不导出。 -
视觉上,在图中,看起来像是循环依赖。然而,从
store到client没有依赖性,因为接口是隐式满足的。这就是为什么这种方法在具有显式实现的语言中并不总是可行的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0tpYhCdH-1684395314256)(…/…/OEBPS/Images/CH02_F06_Harsanyi.png)]
图 2.6client包通过创建自己的接口定义了它需要的抽象。
主要的一点是client包现在可以为它的需求定义最精确的抽象(这里,只有一个方法)。它涉及到接口分离原则的概念(SOLID 中的 I),该原则声明不应该强迫任何客户端依赖它不使用的方法。因此,在这种情况下,最好的方法是在生产者端公开具体的实现,让客户决定如何使用它以及是否需要抽象。
为了完整起见,让我们提一下这种方法——生产者端的接口——有时在标准库中使用。例如,encoding包定义了由其他子包如encoding/json或encoding/binary实现的接口。encoding包装在这点上有错吗?肯定不是。在这种情况下,encoding包中定义的抽象在标准库中使用,语言设计者知道预先创建这些抽象是有价值的。我们回到上一节的讨论:如果你认为抽象在想象的未来可能是有帮助的,或者至少,如果你不能证明这个抽象是有效的,就不要创建它。
在大多数情况下,接口应该位于消费者端。然而,在特定的环境中(例如,当我们知道——而不是预见——一个抽象将对消费者有帮助时),我们可能希望它在生产者一方。如果我们这样做了,我们应该努力使它尽可能的小,增加它的可重用性,使它更容易组合。
让我们在函数签名的上下文中继续讨论接口。
2.7 #7:返回接口
在设计函数签名时,我们可能需要返回一个接口或者一个具体的实现。让我们来理解为什么返回一个接口在很多情况下被认为是 Go 中的一个坏习惯。
我们刚刚介绍了为什么接口通常存在于消费者端。图 2.7 显示了如果一个函数返回一个接口而不是一个结构,依赖关系会发生什么。我们会看到它会导致一些问题。
我们将考虑两种方案:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LZDLgHCL-1684395314257)(…/…/OEBPS/Images/CH02_F07_Harsanyi.png)]
图 2.7 从store包到client包有一个依赖关系。
在store包中,我们定义了一个实现Store接口的InMemoryStore结构。同时,我们创建一个NewInMemoryStore函数来返回一个Store接口。在这个设计中,从实现包到客户机包有一个依赖关系,这听起来可能有点奇怪。
比如client包已经不能调用NewInMemoryStore函数了;否则,就会出现循环依赖。一个可能的解决方案是从另一个包中调用这个函数,并将一个Store实现注入到client。然而,被迫这样做意味着设计应该受到质疑。
此外,如果另一个客户机使用了InMemoryStore结构会怎么样?在这种情况下,也许我们想将Store接口移动到另一个包中,或者回到实现包中——但是我们讨论了为什么在大多数情况下,这不是最佳实践。这看起来像代码的味道。
因此,一般来说,返回一个接口会限制灵活性,因为我们强迫所有的客户端使用一种特定类型的抽象。大多数情况下,我们可以从 Postel 定律(datatracker.ietf.org/doc/html/rfc761)中得到启发:
做自己的事要保守,接受别人的东西要开明。
如果我们把这个习语用到GO上,那就意味着
-
返回结构而不是接口
-
如果可能的话接受接口
当然,也有一些例外。作为软件工程师,我们熟悉这样一个事实:规则从来不是 100%正确的。最相关的是类型,一个由许多函数返回的接口。我们还可以用包io检查标准库中的另一个异常:
func LimitReader(r Reader, n int64) Reader {
return &LimitedReader{r, n}
}
这里,函数返回一个导出的结构,io.LimitedReader。然而,函数签名是一个接口io.Reader。打破我们到目前为止讨论的规则的基本原理是什么?io.Reader是一个预先的抽象概念。它不是由客户定义的,但它是强制的,因为语言设计者事先知道这种抽象级别会有帮助(例如,在可重用性和可组合性方面)。
总而言之,大多数情况下,我们不应该返回接口,而应该返回具体的实现。否则,由于包的依赖性,它会使我们的设计更加复杂,并且会限制灵活性,因为所有的客户端都必须依赖相同的抽象。同样,结论类似于前面的章节:如果我们知道(不是预见)一个抽象对客户有帮助,我们可以考虑返回一个接口。否则,我们不应该强迫抽象;他们应该被客户发现。如果客户端出于某种原因需要抽象一个实现,它仍然可以在客户端这样做。
在下一节中,我们将讨论一个与使用any相关的常见错误。
2.8 #8:any什么都不代表
在 Go 中,指定零方法的接口类型被称为空接口,interface{}。到了 Go 1.18,预声明的类型any变成了空接口的别名;因此,所有的interface{}事件都可以用any代替。在很多情况下,any可以认为是一种过度概括;而且就像罗布派克说的,不传达任何东西(www.youtube.com/watch?v=PAAkCSZUG1c&t=7m36s)。让我们先提醒自己核心概念,然后我们可以讨论潜在的问题。
一个any类型可以保存任何值类型:
func main() {
var i any
i = 42 // ❶
i = "foo" // ❷
i = struct { // ❸
s string
}{
s: "bar",
}
i = f // ❹
_ = i // ❺
}
func f() {}
国际// ❶
❷ 字符串
❸ 结构
❹ 函数
在给和any类型赋值时,我们丢失了所有的类型信息,这需要一个类型断言来从i变量中获取任何有用的信息,就像前面的例子一样。让我们看另一个例子,这里使用any是不准确的。在下面,我们实现了一个Store结构和两个方法Get和Set的框架。我们使用这些方法来存储不同的结构类型,Customer和Contract:
package store
type Customer struct{
// Some fields
}
type Contract struct{
// Some fields
}
type Store struct{}
func (s *Store) Get(id string) (any, error) { // ❶
// ...
}
func (s *Store) Set(id string, v any) error { // ❷
// ...
}
❶ 返回any
❷ 接受any
虽然Store在编译方面没有任何问题,但是我们应该花一分钟来考虑一下方法签名。因为我们接受并返回any参数,所以这些方法缺乏表现力。如果未来的开发人员需要使用Store结构,他们可能需要钻研文档或阅读代码来理解如何使用这些方法。因此,接受或返回一个any类型并不能传达有意义的信息。此外,因为在编译时没有安全措施,所以没有什么可以阻止调用者用任何数据类型调用这些方法,比如一个int:
s := store.Store{}
s.Set("foo", 42)
通过使用any,我们失去了 Go 作为静态类型语言的一些好处。相反,我们应该避免any类型,尽可能使我们的签名显式化。对于我们的例子,这可能意味着为每个类型复制Get和Set方法:
func (s *Store) GetContract(id string) (Contract, error) {
// ...
}
func (s *Store) SetContract(id string, contract Contract) error {
// ...
}
func (s *Store) GetCustomer(id string) (Customer, error) {
// ...
}
func (s *Store) SetCustomer(id string, customer Customer) error {
// ...
}
在这个版本中,这些方法很有表现力,减少了不理解的风险。拥有更多的方法不一定是问题,因为客户也可以使用一个接口创建他们自己的抽象。例如,如果一个客户只对Contract方法感兴趣,它可以写这样的东西:
type ContractStorer interface {
GetContract(id string) (store.Contract, error)
SetContract(id string, contract store.Contract) error
}
有哪些any有帮助的情况?让我们看看标准库,看看函数或方法接受any参数的两个例子。第一个例子是在即encoding/json包中。因为我们可以封送任何类型,Marshal函数接受any参数:
func Marshal(v any) ([]byte, error) {
// ...
}
另一个例子是在的database/sql包中。如果查询是参数化的(例如,SELECT * FROM FOO WHERE id = ?),参数可以是任何种类。因此,它也使用any参数:
func (c *Conn) QueryContext(ctx context.Context, query string,
args ...any) (*Rows, error) {
// ...
}
总之,如果确实需要接受或返回任何可能的类型(例如,当涉及到封送或格式化时),any会很有帮助。一般来说,我们应该不惜一切代价避免过度概括我们编写的代码。也许少量的重复代码偶尔会更好,如果它改善了其他方面,比如代码的表达能力。
2.9 #9:对何时使用泛型感到困惑
Go 1.18 在语言中加入了泛型。简而言之,这允许用可以在以后指定并在需要时实例化的类型来编写代码。然而,什么时候使用泛型,什么时候不使用泛型可能会令人困惑。在这一节中,我们将描述 Go 中泛型的概念,然后看看常见的用法和误用。
2.9.1 概念
考虑以下从map[string]int类型中提取所有键的函数:
func getKeys(m map[string]int) []string {
var keys []string
for k := range m {
keys = append(keys, k)
}
return keys
}
如果我们想对另一种映射类型(如map[int]string)使用类似的函数,该怎么办?在泛型出现之前,Go 开发者有几个选择:使用代码生成、反射或复制代码。例如,我们可以编写两个函数,每个函数对应一种映射类型,或者甚至尝试扩展getKeys来接受不同的映射类型:
func getKeys(m any) ([]any, error) { // ❶
switch t := m.(type) {
default:
return nil, fmt.Errorf("unknown type: %T", t) // ❷
case map[string]int:
var keys []any
for k := range t {
keys = append(keys, k)
}
return keys, nil
case map[int]string:
// Copy the extraction logic
}
}
❶ 接受并返回任何参数
❷ 如果类型还没有实现,处理运行时错误
通过这个例子,我们开始注意到一些问题。首先,它增加了样板代码。事实上,当我们想要添加一个案例时,它需要复制的range循环。同时,函数现在接受了和any类型,这意味着我们失去了 Go 作为类型化语言的一些好处。事实上,检查一个类型是否被支持是在运行时而不是编译时完成的。因此,如果提供的类型未知,我们也需要返回一个错误。最后,因为键类型可以是int或string,我们必须返回一部分any类型来提取键类型。这种方法增加了调用方的工作量,因为客户端可能还需要执行键的类型检查或额外的转换。多亏了泛型,我们现在可以使用类型参数重构这段代码。
类型参数是我们可以在函数和类型中使用的泛型类型。例如,以下函数接受类型参数:
func foo[T any](t T) { // ❶
// ...
}
❶ T是一个类型参数。
调用foo时,我们传递一个any类型的类型实参。提供类型参数是调用实例化,工作在编译时完成。这使得类型安全成为核心语言特性的一部分,并避免了运行时开销。
让我们回到getKeys函数,使用类型参数编写一个通用版本,它可以接受任何类型的映射:
func getKeys[K comparable, V any](m map[K]V) []K { // ❶
var keys []K // ❷
for k := range m {
keys = append(keys, k)
}
return keys
}
❶ 键是可比较的,而值是任意类型的。
❷ 创建了键的切片
为了处理映射,我们定义了两种类型参数。首先,值可以是any类型:V any。然而,在 Go 中,映射键不能是和any类型。例如,我们不能使用切片:
var m map[[]byte]int
这段代码导致编译错误:invalid map key type []byte。因此,我们不接受任何键类型,而是必须限制类型参数,以便键类型满足特定的要求。这里的要求是键的类型必须具有可比性(我们可以用==或者!=)。因此,我们将K定义为comparable而不是any。
限制类型参数以匹配特定的需求被称为约束。约束是一种接口类型,可以包含
-
一套行为(方法)
-
任意类型
让我们来看看后者的一个具体例子。假设我们不想为map键类型接受任何comparable类型。例如,我们希望将限制为的int或string类型。我们可以这样定义自定义约束:
type customConstraint interface {
~int | ~string // ❶
}
func getKeys[K customConstraint, // ❷
V any](m map[K]V) []K {
// Same implementation
}
❶ 定义了一个自定义类型,将类型限制为int和string
首先,我们定义一个customConstraint接口,使用联合操作符|将和类型限制为int或string(稍后我们将讨论~的用法)。K现在是customConstraint而不是之前的comparable。
getKeys的签名要求我们可以用任何值类型的映射来调用它,但是键类型必须是int或string——例如,在调用者端:
m = map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
keys := getKeys(m)
注意 Go 可以推断出getKeys是用string类型参数调用的。前面的调用相当于:
keys := getKeys[string](m)
~int vs. int
使用~int的约束和使用int的约束有什么区别?使用int将其限制为该类型,而~int则限制所有底层类型为int的类型。为了说明,让我们设想一个约束,我们希望将一个类型限制为实现String()``string方法的任何int类型:
type customConstraint interface {
~int
String() string
}
type customInt int
func (i customInt) String() string {
return strconv.Itoa(int(i))
}
因为customInt是一个int并实现了String() string方法,所以customInt类型满足定义的约束。然而,如果我们改变约束来包含一个int而不是~int,使用customInt会导致编译错误,因为类型int没有实现String() string。
到目前为止,我们已经讨论了对函数使用泛型的例子。然而,我们也可以使用数据结构的泛型。例如,我们可以创建一个包含任何类型值的链表。为此,我们将编写一个Add方法来追加一个节点:
type Node[T any] struct { // ❶
Val T
next *Node[T]
}
func (n *Node[T]) Add(next *Node[T]) { // ❷
n.next = next
}
❶ 使用类型参数
在示例中,我们使用类型参数来定义T,并在Node中使用这两个字段。关于该方法,接收器被实例化。事实上,因为Node是泛型的,所以它也必须遵循定义的类型参数。
关于类型参数需要注意的最后一点是,它们不能与方法参数一起使用,只能与函数参数或方法接收器一起使用。例如,下面的方法不会编译:
type Foo struct {}
func (Foo) bar[T any](t T) {}
./main.go:29:15: methods cannot have type parameters
如果我们想在方法中使用泛型,那么接收者需要成为类型参数。
现在,让我们检查一下我们应该和不应该使用泛型的具体情况。
2.9.2 常见用途和误用
泛型什么时候有用?让我们讨论一些建议使用泛型的常见用法:
-
处理任何类型的切片、贴图和通道的函数——例如,合并两个通道的函数可以处理任何类型的通道。因此,我们可以使用类型参数来提取通道类型:
func merge[T any](ch1, ch2 <-chan T) <-chan T { // ... } -
分解出行为而不是类型——
sort包,例如,包含一个接口和三个方法:type Interface interface { Len() int Less(i, j int) bool Swap(i, j int) }该接口由
sort.Ints或sort .Float64s等不同的函数使用。使用类型参数,我们可以分解出排序行为(例如,通过定义一个包含切片和比较函数的结构):type SliceFn[T any] struct { // ❶ S []T Compare func(T, T) bool // ❷ } func (s SliceFn[T]) Len() int { return len(s.S) } func (s SliceFn[T]) Less(i, j int) bool { return s.Compare(s.S[i], s.S[j]) } func (s SliceFn[T]) Swap(i, j int) { s.S[i], s.S[j] = s.S[j], s.S[i] }❶使用类型参数
❷比较了两个元素
然后,因为
SliceFn结构实现了sort.Interface,我们可以使用的sort.Sort(sort.Interface)函数对提供的切片进行排序:s := SliceFn[int]{ S: []int{3, 2, 1}, Compare: func(a, b int) bool { return a < b }, } sort.Sort(s) fmt.Println(s.S) [1 2 3]在这个例子中,分解出一个行为允许我们避免为每个类型创建一个函数。
反过来说,什么时候建议我们不要使用泛型?
-
当调用类型参数的方法时——考虑一个接收
io.Writer并调用的Write方法的函数,例如:func foo[T io.Writer](w T) { b := getBytes() _, _ = w.Write(b) }在这种情况下,使用泛型不会给我们的代码带来任何价值。我们应该把
w直接变成io.Writer。 -
当它让我们的代码变得更复杂的时候——泛型从来都不是强制性的,作为 Go 开发者,我们已经没有它们十多年了。如果我们正在编写通用的函数或结构,并且我们发现它并没有使我们的代码更清晰,我们可能应该重新考虑我们对于这个特殊用例的决定。
虽然泛型在特定的情况下会有帮助,但是我们应该小心什么时候使用它们,什么时候不使用它们。一般来说,如果我们想回答什么时候不使用泛型,我们可以找到与什么时候不使用接口的相似之处。事实上,泛型引入了一种抽象形式,我们必须记住,不必要的抽象引入了复杂性。
同样,让我们不要用不必要的抽象污染我们的代码,现在让我们专注于解决具体的问题。这意味着我们不应该过早地使用类型参数。让我们等到要写样板代码的时候再考虑使用泛型。
在下一节中,我们将讨论使用类型嵌入时可能出现的问题。
2.10 #10:不知道类型嵌入可能存在的问题
当创建一个结构时,Go 提供了嵌入类型的选项。但是如果我们不理解类型嵌入的所有含义,这有时会导致意想不到的行为。在这一节中,我们将探讨如何嵌入类型,它们会带来什么,以及可能出现的问题。
在 Go 中,如果一个结构字段没有名字就被声明,那么它就被称为嵌入的。举个例子,
type Foo struct {
Bar // ❶
}
type Bar struct {
Baz int
}
❶ 嵌入字段
在Foo结构中,Bar类型是在没有关联名称的情况下声明的;因此,它是一个嵌入式字段。
我们使用嵌入来提升嵌入类型的字段和方法。因为Bar包含一个Baz字段,这个字段被提升为Foo(见图 2.8)。因此,Baz从Foo开始变为可用:
foo := Foo{}
foo.Baz = 42
请注意,Baz可从两个不同的路径获得:要么从使用Foo.Baz的提升路径获得,要么通过Bar、Foo.Bar.Baz从名义路径获得。两者都涉及同一个字段。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TVimEnQ6-1684395314257)(…/…/OEBPS/Images/CH02_F08_Harsanyi.png)]
图 2.8 baz被提升,因此可直接从S进入。
接口和嵌入
嵌入也用在接口中,与其他接口组成一个接口。在下面的例子中,io.ReadWriter由一个io.Reader和一个io.Writer组成:
type ReadWriter interface {
Reader
Writer
}
但是本节的范围只与结构中的嵌入字段相关。
现在我们已经提醒自己什么是嵌入类型,让我们看一个错误用法的例子。在下面的代码中,我们实现了一个保存一些内存数据的结构,我们希望使用互斥锁来保护它免受并发访问:
type InMem struct {
sync.Mutex // ❶
m map[string]int
}
func New() *InMem {
return &InMem{m: make(map[string]int)}
}
❶ 嵌入字段
我们决定不导出映射,这样客户端就不能直接与它交互,只能通过导出的方法。同时,互斥字段被嵌入。因此,我们可以这样实现一个Get方法:
func (i *InMem) Get(key string) (int, bool) {
i.Lock() // ❶
v, contains := i.m[key]
i.Unlock() // ❷
return v, contains
}
❶ 直接访问Lock方法
❷ Unlock方法也是如此。
因为互斥体是嵌入的,所以我们可以从i接收器直接访问Lock和Unlock方法。
我们提到过这样的例子是类型嵌入的错误用法。这是什么原因呢?由于sync.Mutex是一个嵌入式类型,所以Lock和Unlock方法将被提升。因此,这两种方法对于使用InMem的外部客户端都是可见的:
m := inmem.New()
m.Lock() // ??
这种提升可能是不可取的。在大多数情况下,互斥体是我们希望封装在一个结构中并对外部客户端不可见的东西。因此,在这种情况下,我们不应该将其作为嵌入字段:
type InMem struct {
mu sync.Mutex // ❶
m map[string]int
}
因为互斥体没有嵌入也没有导出,所以它不能从外部客户端访问。现在让我们看另一个例子,但是这次嵌入被认为是一种正确的方法。
我们想要编写一个定制的日志记录器,它包含一个io.WriteCloser并公开两个方法Write和Close。如果io.WriteCloser没有嵌入,我们需要这样写:
type Logger struct {
writeCloser io.WriteCloser
}
func (l Logger) Write(p []byte) (int, error) {
return l.writeCloser.Write(p) // ❶
}
func (l Logger) Close() error {
return l.writeCloser.Close() // ❶
}
func main() {
l := Logger{writeCloser: os.Stdout}
_, _ = l.Write([]byte("foo"))
_ = l.Close()
}
❶ 将调用转发给writeCloser
Logger必须为提供一个Write和一个Close方法,该方法只能将调用转发给io.WriteCloser。但是,如果该字段现在变成嵌入的,我们可以删除这些转发方法:
type Logger struct {
io.WriteCloser // ❶
}
func main() {
l := Logger{WriteCloser: os.Stdout}
_, _ = l.Write([]byte("foo"))
_ = l.Close()
}
❶ 指定io.WriteCloser是嵌入的
对于具有两个导出的Write和Close方法的客户端来说是一样的。但是该示例阻止实现这些附加方法来简单地转移调用。同样,随着Write和Close被提升,意味着Logger满足的io.WriteCloser接口。
嵌入与 OOP 子类化
区分嵌入和 OOP 子类有时会令人困惑。主要的区别与方法接收者的身份有关。我们来看下图。左手边代表嵌入在Y中的类型X,而右手边的Y延伸出X。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Lh235EDE-1684395314257)(…/…/OEBPS/Images/CH02_F08_UN01_Harsanyi.png)]
对于嵌入,嵌入类型仍然是方法的接收者。相反,有了子类化,子类就变成了方法的接收者。
通过嵌入,Foo的接收者仍然是X。然而,通过子类化,Foo的接收者变成了子类,Y。嵌入是构图,不是继承。
关于类型嵌入我们应该得出什么结论?首先,让我们注意到这很少是必要的,这意味着无论什么用例,我们都可以不用类型嵌入来解决它。类型嵌入主要是为了方便:在大多数情况下,是为了促进行为。
如果我们决定使用类型嵌入,我们需要记住两个主要约束:
-
它不应该仅仅作为某种语法糖来简化对字段的访问(比如用
Foo.Baz()代替Foo.Bar.Baz())。如果这是唯一的理由,让我们不要嵌入内部类型,而是使用字段。 -
它不应该促进我们想要对外部隐藏的数据(字段)或行为(方法):例如,如果它允许客户端访问一个锁定行为,该行为应该对该结构保持私有。
注意,有些人可能会认为,在导出结构的上下文中,使用类型嵌入会导致额外的维护工作。事实上,在导出的结构中嵌入一个类型意味着当这个类型发展时要保持谨慎。例如,如果我们向内部类型添加一个新方法,我们应该确保它不会破坏后面的约束。因此,为了避免这种额外的工作,团队还可以防止在公共结构中嵌入类型。
通过记住这些约束,有意识地使用类型嵌入有助于避免带有额外转发方法的样板代码。然而,让我们确保我们不仅仅是为了化妆品而这样做,也不宣传那些应该隐藏的元素。
在下一节中,我们将讨论处理可选配置的常见模式。
2.11 #11:不使用函数式选项模式
设计 API 时,可能会出现一个问题:我们如何处理可选配置?有效地解决这个问题可以提高我们的 API 的便利性。这一节将通过一个具体的例子来介绍处理可选配置的不同方法。
对于这个例子,假设我们必须设计一个库,它公开一个函数来创建一个 HTTP 服务器。这个函数接受不同的输入:一个地址和一个端口。下面显示了该函数的框架:
func NewServer(addr string, port int) (*http.Server, error) {
// ...
}
我们库的客户端已经开始使用这个函数了,大家都很高兴。但是在某个时候,我们的客户开始抱怨这个函数有些受限,并且缺少其他参数(例如,写超时和连接上下文)。然而,我们注意到添加新的函数参数破坏了兼容性,迫使客户端修改它们调用NewServer的方式。同时,我们希望以这种方式丰富与端口管理相关的逻辑(图 2.9):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6wG4NGbb-1684395314258)(…/…/OEBPS/Images/CH02_F09_Harsanyi.png)]
我们如何以一种 API 友好的方式实现这个功能?让我们看看不同的选项。
2.11.1 配置结构
因为 Go 不支持函数签名中的可选参数,第一种可能的方法是使用配置结构来传达什么是强制的,什么是可选的。例如,强制参数可以作为函数参数存在,而可选参数可以在Config结构中处理:
type Config struct {
Port int
}
func NewServer(addr string, cfg Config) {
}
此解决方案解决了兼容性问题。事实上,如果我们添加新的选项,它不会在客户端中断。然而,这种方法不能解决我们与端口管理相关的需求。事实上,我们应该记住,如果没有提供结构字段,它将被初始化为零值:
因此,在下面的示例中,两个结构是相等的:
c1 := httplib.Config{
Port: 0, // ❶
}
c2 := httplib.Config{
// ❷
}
❶ 将端口初始化为 0
❷ 端口丢失,所以它被初始化为 0。
在我们的例子中,我们需要找到一种方法来区分故意设置为 0 的端口和丢失的端口。也许一种选择是以这种方式将配置结构的所有参数作为指针来处理:
type Config struct {
Port *int
}
使用整数指针,在语义上,我们可以突出显示值0和缺失值(零指针)之间的差异。
这种选择是可行的,但也有一些缺点。首先,客户端提供一个整数指针并不方便。客户端必须创建一个变量,然后以这种方式传递指针:
port := 0
config := httplib.Config{
Port: &port, // ❶
}
❶ 提供一个整数指针
它本身并不引人注目,但是整体的 API 使用起来有点不方便。同样,我们添加的选项越多,代码就变得越复杂。
第二个缺点是,使用默认配置的库的客户端需要以这种方式传递一个空结构:
httplib.NewServer("localhost", httplib.Config{})
这段代码看起来不怎么样。读者必须理解这个神奇的结构是什么意思。
2.11.2 构建器模式
builder 模式最初是四人组设计模式的一部分,它为各种对象创建问题提供了灵活的解决方案。Config的构造与结构本身是分离的。它需要一个额外的结构ConfigBuilder,该结构接收配置和构建Config的方法。
让我们看一个具体的例子,看看它如何帮助我们设计一个友好的 API 来满足我们的所有需求,包括端口管理:
type Config struct { // ❶
Port int
}
type ConfigBuilder struct { // ❷
port *int
}
func (b *ConfigBuilder) Port(
port int) *ConfigBuilder { // ❸
b.port = &port
return b
}
func (b *ConfigBuilder) Build() (Config, error) { // ❹
cfg := Config{}
if b.port == nil { // ❺
cfg.Port = defaultHTTPPort
} else {
if *b.port == 0 {
cfg.Port = randomPort()
} else if *b.port < 0 {
return Config{}, errors.New("port should be positive")
} else {
cfg.Port = *b.port
}
}
return cfg, nil
}
func NewServer(addr string, config Config) (*http.Server, error) {
// ...
}
❶ 配置结构
❷ 配置生成器结构,包含可选端口
❸ 公共端口的设置方法
创建配置结构的❹构建方法
❺ 与港口管理相关的主要逻辑
ConfigBuilder结构保存客户端配置。它公开了一个设置端口的Port方法。通常,这样的配置方法会返回构建器本身,以便我们可以使用方法链接(例如,builder.Foo("foo").Bar("bar"))。它还公开了一个Build方法,该方法保存初始化端口值的逻辑(指针是否为nil等等)。)并在创建后返回一个Config结构。
请注意,构建器模式没有单一的可能实现。例如,有些人可能喜欢定义最终端口值的逻辑在Port方法中而不是在Build中的方法。本节的范围是呈现构建器模式的概述,而不是查看所有不同的可能变体。
然后,一个客户会以下面的方式使用我们的基于构建器的 API(我们假设我们已经把代码放在了一个httplib包中):
builder := httplib.ConfigBuilder{} // ❶
builder.Port(8080) // ❷
cfg, err := builder.Build() // ❸
if err != nil {
return err
}
server, err := httplib.NewServer("localhost", cfg) // ❹
if err != nil {
return err
}
❶ 创建一个生成器配置
❷ 设置端口
❸ 构建配置结构
❹ 传递配置结构
首先,客户端创建一个ConfigBuilder并使用它来设置一个可选字段,比如端口。然后,它调用Build方法并检查错误。如果正常,配置被传递到NewServer。
这种方法使得端口管理更加方便。不需要传递整数指针,因为Port方法接受整数。但是,如果客户端想要使用默认配置,我们仍然需要传递一个可以为空的配置结构:
server, err := httplib.NewServer("localhost", nil)
在某些情况下,另一个缺点与错误管理有关。在抛出异常的编程语言中,如果输入无效,像Port这样的构建器方法可以引发异常。如果我们想保持链接调用的能力,函数就不能返回错误。因此,我们不得不延迟在Build方法中的验证。如果一个客户端可以传递多个选项,但是我们想要精确地处理端口无效的情况,这使得错误处理变得更加复杂。
现在让我们看看另一种方法,叫做函数选项模式,它依赖于变量参数。
2.11.3 函数式选项模式
我们将讨论的最后一种方法是函数式选项模式(图 2.10)。虽然有不同的实现,但有细微的变化,主要思想如下:
-
未导出的结构保存配置:
options。 -
每个选项都是返回相同类型的函数:
type Option func(options *options) error。例如,WithPort接受一个代表端口的int参数,并返回一个代表如何更新options结构的Option类型。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TWUU5ISx-1684395314258)(…/…/OEBPS/Images/CH02_F10_Harsanyi.png)]
图 2.10WithPort选项更新最终的options结构。
下面是options结构、Option类型和WithPort选项的 Go 实现:
type options struct { // ❶
port *int
}
type Option func(options *options) error // ❷
func WithPort(port int) Option { // ❸
return func(options *options) error {
if port < 0 {
return errors.New("port should be positive")
}
options.port = &port
return nil
}
}
❶ 配置结构
❷ 表示更新配置结构的函数类型
❸ 更新端口的配置函数
这里,WithPort返回一个闭包。一个闭包是一个匿名函数,从它的正文外部引用变量;在这种情况下,port变量。闭包遵循Option类型并实现端口验证逻辑。每个配置字段都需要创建一个公共函数(按照惯例,以前缀With开始),包含类似的逻辑:如果需要,验证输入并更新配置结构。
让我们看看提供者端的最后一部分:NewServer实现。我们将把选项作为变量参数传递。因此,我们必须迭代这些选项来改变options配置结构:
func NewServer(addr string, opts ...Option) ( // ❶
*http.Server, error) {
var options options // ❷
for _, opt := range opts { // ❸
err := opt(&options) // ❹
if err != nil {
return nil, err
}
}
// At this stage, the options struct is built and contains the config
// Therefore, we can implement our logic related to port configuration
var port int
if options.port == nil {
port = defaultHTTPPort
} else {
if *options.port == 0 {
port = randomPort()
} else {
port = *options.port
}
}
// ...
}
❶ 接受可变选项参数
❷ 创建了一个空的选项结构
❹ 调用每个选项,这导致修改公共选项结构
我们首先创建一个空的options结构。然后,我们迭代每个Option参数并执行它们来改变options结构(记住Option类型是一个函数)。一旦构建了options结构,我们就可以实现关于端口管理的最终逻辑。
因为NewServer接受可变的Option参数,客户端现在可以通过在强制地址参数后传递多个选项来调用这个 API。举个例子,
server, err := httplib.NewServer("localhost",
httplib.WithPort(8080),
httplib.WithTimeout(time.Second))
但是,如果客户机需要默认配置,它不必提供参数(例如,一个空结构,正如我们在前面的方法中看到的)。客户端的调用现在可能看起来像这样:
server, err := httplib.NewServer("localhost")
这种模式就是函数式选项模式。它提供了一种方便且 API 友好的方式来处理选项。尽管构建者模式可能是一个有效的选项,但是它有一些小的缺点,这使得函数可选项模式成为 Go 中处理这个问题的惯用方法。我们还要注意,这种模式在 gRPC 等不同的 Go 库中使用。
下一节将讨论另一个常见的错误:组织不当。
2.12 #12:项目组织不当
组织一个GO项目并不是一件容易的事情。因为 Go 语言在设计包和模块方面提供了很大的自由度,所以最佳实践并没有像它们应该的那样普遍存在。本节首先讨论构建项目的一种常见方法,然后讨论一些最佳实践,展示改进我们如何组织项目的方法。
2.12.1 项目结构
Go 语言维护者对于在 Go 中构建项目没有很强的约定。然而,这些年来出现了一种布局:项目布局(github.com/golang-standards/project-layout)。
如果我们的项目足够小(只有几个文件),或者如果我们的组织已经创建了它的标准,它可能不值得使用或者迁移到project-layout。否则,可能值得考虑。让我们看一下这个布局,看看主要目录是什么:
-
/pkg——我们要公开给别人的公共代码。 -
/test——附加外部测试和测试数据。中的单元测试与源文件放在同一个包中。但是,公共 API 测试或集成测试应该位于/test中。 -
/examples——我们的应用和/或公共库的示例。
不像其他语言那样有/src目录。理由是/src太通用了;因此,这种布局倾向于使用/cmd、/internal或/pkg这样的目录。
注 2021 年,GO核心维护者之一 Russ Cox 批评了这种布局。尽管不是官方标准,但一个项目主要隶属于 GitHub golang 标准组织。无论如何,我们必须记住,关于项目结构,没有强制性的约定。这种布局可能对你有帮助,也可能没有,但这里重要的是,优柔寡断是唯一错误的决定。因此,在布局上达成一致,以保持组织中的一致性,这样开发人员就不会浪费时间从一个存储库切换到另一个存储库。
现在,让我们讨论如何组织 Go 存储库的主要逻辑。
2,12,2 包组织
在 Go 中,没有子包的概念。然而,我们可以决定在子目录中组织包。如果我们看一下标准库,net目录是这样组织的:
/net
/http
client.go
...
/smtp
auth.go
...
addrselect.go
...
net既作为一个包,又作为包含其他包的目录。但是net/http并不从net继承,也没有对net包的特定访问权限。net/http内的元素只能看到导出的net元素。子目录的主要好处是保持包在一个地方,在那里它们有很高的内聚性。
关于整体组织,有不同的学派。例如,我们应该按上下文还是按层来组织我们的应用?这取决于我们的喜好。我们可能倾向于按上下文(如客户上下文、合同上下文等)对代码进行分组。),或者我们可能倾向于遵循六边形架构原则并按技术层分组。如果我们做出的决策符合我们的用例,只要我们保持一致,它就不会是一个错误的决策。
关于包,有许多我们应该遵循的最佳实践。首先,我们应该避免过早打包,因为这可能会导致项目过于复杂。有时,最好使用简单的组织,当我们理解了项目包含的内容时,让我们的项目发展,而不是强迫我们自己预先构建完美的结构。
粒度是另一个需要考虑的基本问题。我们应该避免几十个只包含一两个文件的 nano 包。如果我们这样做了,那是因为我们可能错过了这些包之间的一些逻辑联系,使得读者更难理解我们的项目。反过来,我们也应该避免淡化包装名称意义的巨大包装。
包命名也应该仔细考虑。众所周知(作为开发者),命名很难。为了帮助客户理解一个 Go 项目,我们应该根据它们提供的东西来命名我们的包,而不是它们包含的内容。还有,命名要有意义。因此,包名应该简短,有表现力,按照惯例,应该是一个小写的单词。
关于导出什么,规则非常简单。我们应该尽可能地减少应该导出的内容,以减少包之间的耦合,并隐藏不必要的导出元素。如果我们不确定是否要导出一个元素,我们应该默认不导出它。稍后,如果我们发现我们需要导出它,我们可以调整我们的代码。让我们记住一些例外,比如导出字段,以便可以用encoding/json解组一个结构。
组织一个项目并不简单,但是遵循这些规则应该有助于使它更容易维护。然而,记住一致性对于简化可维护性也是至关重要的。因此,让我们确保代码库中的东西尽可能保持一致。
在下一节中,我们将讨论实用工具包。
2.13 #13:创建实用工具包
本节讨论一个常见的不好的实践:创建共享的包,比如utils、common和base。我们将用这种方法来检查问题,并学习如何改进我们的组织。
让我们看一个受 Go 官方博客启发的例子。它是关于实现一个集合数据结构(一个值被忽略的映射)。在 Go 中惯用的方法是通过一个带有K的map[K]struct{}类型来处理它,它可以是映射中允许的任何类型作为键,而值是一个struct{}类型。事实上,值类型为struct{}的映射表明我们对值本身不感兴趣。让我们在一个util包中公开两个方法:
package util
func NewStringSet(...string) map[string]struct{} { // ❶
// ...
}
func SortStringSet(map[string]struct{}) []string { // ❷
// ...
}
❷ 返回一个排序的键列表
客户端将像这样使用这个包:
set := util.NewStringSet("c", "a", "b")
fmt.Println(util.SortStringSet(set))
这里的问题是util没有意义。我们可以称它为common、shared或base,但是它仍然是一个没有意义的名字,不能提供任何关于这个包提供了什么的信息。
我们应该创建一个表达性的包名,比如stringset,而不是一个实用工具包。举个例子,
package stringset
func New(...string) map[string]struct{} { ... }
func Sort(map[string]struct{}) []string { ... }
在本例中,我们删除了NewStringSet和SortStringSet的后缀,它们分别变成了New和Sort。在客户端,现在看起来是这样的:
set := stringset.New("c", "a", "b")
fmt.Println(stringset.Sort(set))
注:在上一节中,我们讨论了纳米封装的概念。我们提到了在一个应用中创建几十个 nano 包会使代码路径变得更加复杂。然而,纳米包装的想法本身并不一定是坏的。如果一个小的代码组具有很高的内聚性,并且不属于其他地方,那么将它组织到一个特定的包中是完全可以接受的。没有严格的规则可以适用,通常,挑战在于找到正确的平衡。
我们甚至可以更进一步。我们可以创建一个特定的类型并将Sort作为方法公开,而不是公开实用函数,如下所示:
package stringset
type Set map[string]struct{}
func New(...string) Set { ... }
func (s Set) Sort() []string { ... }
这一变化使得客户端更加简单。只有一个对stringset包的引用:
set := stringset.New("c", "a", "b")
fmt.Println(set.Sort())
通过这个小小的重构,我们去掉了一个无意义的包名,公开了一个有表现力的 API。正如 Dave Cheney(Go 的项目成员)提到的,我们经常合理地找到处理公共设施的实用工具包。例如,如果我们决定有一个客户机和一个服务器包,那么我们应该把公共类型放在哪里呢?在这种情况下,也许一个解决方案是将客户机、服务器和公共代码组合成一个包。
命名包是应用设计的一个关键部分,我们也应该对此保持谨慎。根据经验,创建没有有意义的名字的共享包不是一个好主意;这包括实用工具包,如utils、common或base。此外,请记住,以包提供的内容而不是包包含的内容来命名包是增加其表达性的有效方法。
在下一节中,我们将讨论包和包冲突。
2.14 #14:忽略包名冲突
当一个变量名与一个已存在的包名冲突时,包冲突就会发生,阻止包被重用。让我们看一个具体的例子,一个库公开了一个 Redis 客户机:
package redis
type Client struct { ... }
func NewClient() *Client { ... }
func (c *Client) Get(key string) (string, error) { ... }
现在,让我们跳到客户端。尽管包名为redis,但在 Go 中创建一个名为redis的变量是完全有效的:
redis := redis.NewClient() // ❶
v, err := redis.Get("foo") // ❷
❶ 从redis包中调用NewClient
❷ 使用redis变量
这里,redis变量名与redis包名冲突。即使这是允许的,也应该避免。事实上,在redis变量的整个范围内,redis包将不会被访问。
假设一个限定符在整个函数中同时引用了变量和包名。在这种情况下,对于代码读者来说,知道限定符指的是什么可能是不明确的。有什么选择可以避免这样的碰撞?第一种选择是使用不同的变量名。举个例子,
redisClient := redis.NewClient()
v, err := redisClient.Get("foo")
这可能是最直接的方法。然而,如果出于某种原因,我们希望保留名为redis的变量,我们可以使用包导入。使用包导入,我们可以使用别名来改变限定符来引用redis包。举个例子,
import redisapi "mylib/redis" // ❶
// ...
redis := redisapi.NewClient() // ❷
v, err := redis.Get("foo")
❶ 为redis包创建了一个别名
❷ 通过redisapi别名访问redis包
这里,我们使用了redisapi导入别名来引用redis包,这样就可以保留我们的变量名redis。
注一个选择也可以是使用点导入来访问一个包的所有公共元素,而不用包限定符。但是,这种方法会增加混乱,在大多数情况下应该避免。
还要注意,我们应该避免变量和内置函数之间的命名冲突。例如,我们可以这样做:
copy := copyFile(src, dst) // ❶
在这种情况下,只要copy变量存在,内置函数copy就不会被访问。总之,我们应该防止变量名冲突,以避免歧义。如果我们面临冲突,我们应该找到另一个有意义的名称或使用导入别名。
在下一节中,我们将看到一个与代码文档相关的常见错误。
2.15 #15:缺少代码文档
文档是编码的一个重要方面。它简化了客户使用 API 的方式,但也有助于维护项目。在 Go 中,我们应该遵循一些规则来使我们的代码符合习惯。让我们检查一下这些规则。
首先,必须记录每个导出的元素。不管是结构、接口、函数,还是别的什么,如果导出来了,就必须有文档记录。惯例是添加注释,从导出元素的名称开始。举个例子,
// Customer is a customer representation.
type Customer struct{}
// ID returns the customer identifier.
func (c Customer) ID() string { return "" }
按照惯例,每个注释都应该是一个完整的句子,以标点符号结尾。还要记住,当我们记录一个函数(或者一个方法)时,我们应该强调函数打算做什么,而不是它是如何做的;这属于函数和注释的核心,而不是文档。此外,理想情况下,文档应该提供足够的信息,使用户不必查看我们的代码就能理解如何使用导出的元素。
不推荐使用的元素
可以这样使用// Deprecated:注释来废弃导出的元素:
// ComputePath returns the fastest path between two points.
// Deprecated: This function uses a deprecated way to compute
// the fastest path. Use ComputeFastestPath instead.
func ComputePath() {}
然后,如果开发人员使用了ComputePath函数,他们应该会得到一个警告。(大多数 ide 处理不赞成使用的注释。)
当涉及到记录变量或常数时,我们可能对传达两个方面感兴趣:它的目的和它的内容。前者应该作为代码文档存在,以便对外部客户有用。不过,后者不一定是公开的。举个例子,
// DefaultPermission is the default permission used by the store engine.
const DefaultPermission = 0o644 // Need read and write accesses.
此常数表示默认权限。代码文档传达了它的目的,而常量旁边的注释描述了它的实际内容(读写访问)。
为了帮助客户和维护者理解一个包的范围,我们也应该记录每个包。惯例是以// Package开始注释,后跟包名:
// Package math provides basic constants and mathematical functions.
//
// This package does not guarantee bit-identical results
// across architectures.
package math
包注释的第一行应该简洁。那是因为它会出现在包里(图 2.11 提供了一个例子)。然后,我们可以在下面几行中提供我们需要的所有信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yFwoGbIN-1684395314258)(…/…/OEBPS/Images/CH02_F11_Harsanyi.png)]
图 2.11 生成的 Go 标准库示例
可以在任何 Go 文件中记录一个包;没有规则。一般来说,我们应该将包文档放在与包同名的相关文件中,或者放在特定的文件中,比如doc.go。
关于包文档最后要提到的一点是,与声明不相邻的注释被省略了。例如,以下版权注释在生成的文档中不可见:
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// Package math provides basic constants and mathematical functions.
// // ❶
// This package does not guarantee bit-identical results
// across architectures.
package math
❶ 空行。之前的注释将不包括在文档中。
总之,我们应该记住,每个导出的元素都需要被记录。记录我们的代码不应该成为一种约束。我们应该抓住机会,确保它有助于客户和维护人员理解我们代码的目的。
最后,在本章的最后一节,我们将看到一个关于工具的常见错误:不使用linter。
2.16 #16:不使用linter
一个 linter 是一个自动分析代码和捕捉错误的工具。本节的范围不是给出现有linter的详尽列表;否则,它很快就会被弃用。但是我们应该理解并记住为什么linter对于大多数GO项目是必不可少的。
为了理解为什么linter很重要,让我们举一个具体的例子。在错误#1,“意外的变量阴影”,我们讨论了与变量阴影相关的潜在错误。使用vet(Go 工具集中的一个标准工具)和shadow,我们可以检测隐藏的变量:
package main
import "fmt"
func main() {
i := 0
if true {
i := 1 // ❶
fmt.Println(i)
}
fmt.Println(i)
}
❶ 阴影变量
因为vet包含在 Go 二进制文件中,所以让我们首先安装shadow,将其与 Go vet链接,然后在前面的例子中运行它:
$ go install
golang.org/x/tools/go/analysis/passes/shadow/cmd/shadow // ❶
$ go vet -vettool=$(which shadow) // ❷
./main.go:8:3:
declaration of "i" shadows declaration at line 6 // ❸
❶ 安装阴影
❷ 使用vettol参数链接到 Go vet
❸ GO兽医检测影子变量。
正如我们所看到的,vet通知我们在这个例子中变量i被隐藏了。使用适当的 linters 可以帮助我们的代码更加健壮,并检测潜在的错误。
注意短评没有涵盖本书中的所有错误。所以,建议你只是继续读下去;).
同样,本节的目标不是列出所有可用的linter。然而,如果你不是 linters 的经常用户,这里有一个你可能想每天使用的列表:
除了 linters,我们还应该使用代码格式化程序来修复代码风格。这里有一些代码格式化程序供您尝试:
同时,我们还应该看看golangci-lint(github.com/golangci/golangci-lint)。这是一个林挺工具,在许多有用的 linters 和排版工具之上提供了一个门面。此外,它允许并行运行 linters 以提高分析速度,这非常方便。
Linters 和排版工具是提高我们代码库的质量和一致性的一个强大的方法。让我们花点时间来理解我们应该使用哪一个,并确保我们自动执行它们(例如 CI 或 Git 预提交钩子)。
总结
-
避免隐藏变量有助于防止出现错误,比如引用错误的变量或迷惑读者。
-
避免嵌套层次并保持快乐路径在左侧对齐使得构建心理代码模型更容易。
-
初始化变量时,记住
init函数的错误处理有限,会使状态处理和测试更加复杂。在大多数情况下,初始化应该作为特定的函数来处理。 -
在 Go 中强制使用获取器和设置器并不符合习惯。务实一点,在效率和盲从某些习惯用法之间找到合适的平衡点,应该是应该走的路。
-
抽象应该被发现,而不是被创建。为了避免不必要的复杂性,在你需要的时候创建一个接口,而不是在你预见到需要的时候,或者如果你至少能证明抽象是有效的,就创建一个接口。
-
在客户端保留接口可以避免不必要的抽象。
-
为了防止在灵活性方面受到限制,在大多数情况下,函数不应该返回接口,而应该返回具体的实现。相反,函数应该尽可能接受接口。
-
只在需要接受或返回任何可能的类型时才使用
any,比如json. Marshal。否则,any不会提供有意义的信息,并且会导致编译时问题,因为它允许调用者调用任何数据类型的方法。 -
依赖泛型和类型参数可以防止编写样板代码来提取元素或行为。但是,不要过早地使用类型参数,只有当您看到对它们的具体需求时才使用。否则,它们会引入不必要的抽象和复杂性。
-
使用类型嵌入还有助于避免样板代码;但是,要确保这样做不会导致一些本应隐藏的字段出现可见性问题。
-
为了以 API 友好的方式方便地处理选项,请使用函数选项模式。
-
遵循诸如
project-layout这样的布局是开始构建 Go 项目的好方法,尤其是如果你正在寻找现有的约定来标准化一个新项目。 -
命名是应用设计的关键部分。创建出
common、util、shared这样的包装,并不能给读者带来多少价值。将这样的包重构为有意义的、特定的包名。 -
为了避免变量和包之间的命名冲突,导致混乱甚至错误,为每个变量使用唯一的名字。如果这不可行,可以使用导入别名来更改限定符,以区分包名和变量名,或者想一个更好的名称。
-
为了帮助客户和维护者理解你的代码的目的,记录导出的元素。
-
为了提高代码质量和一致性,使用 linters 和排版工具。
三、数据类型
本章涵盖
处理数据类型是软件工程师的一项经常性操作。本章深入探讨了与基本类型、切片和贴图相关的最常见错误。我们省略的唯一数据类型是字符串,因为后面的章节将专门讨论这种类型。
3.1 #17:用八进制字面值制造混乱
我们先来看一个对八进制字面值表示的常见误解,这种误解会导致混乱甚至 bug。您认为以下代码的输出应该是什么?
sum := 100 + 010
fmt.Println(sum)
乍一看,我们可能期望这段代码打印出100 + 10 = 110的结果。但是它打印的是 108。这怎么可能呢?
在 Go 中,以 0 开头的整数字面值被视为八进制整数(基数为 8),因此基数为 8 的 10 等于基数为 10 的 8。因此,上例中的总和等于100 + 8 = 108。这是需要记住的整数字面值的一个重要属性——例如,在读取现有代码时避免混淆。
八进制整数在不同的场景中都很有用。例如,假设我们想使用os.OpenFile打开一个文件。这个函数需要传递一个权限作为uint32。如果我们想匹配一个 Linux 权限,为了可读性,我们可以传递一个八进制数,而不是十进制数:
file, err := os.OpenFile("foo", os.O_RDONLY, 0644)
在这个例子中,0644代表一个特定的 Linux 权限(对所有人都是读的,对当前用户只写)。也可以在零后面添加一个o字符(小写字母):
file, err := os.OpenFile("foo", os.O_RDONLY, 0o644)
使用0o作为前缀,而不是仅仅使用0,意思是一样的。但是,它有助于使代码更加清晰。
注意我们也可以使用大写的O字符来代替小写的o。但是传递0O644可能会增加混乱,因为根据字符字体的不同,0可能看起来与O非常相似。
我们还应该注意其他整数字面值表示:
最后,我们还可以使用下划线字符(_)作为分隔符,以提高可读性。比如我们可以这样写 10 亿:1_000_000_000。我们也可以在其他表示中使用下划线字符(例如,0b00_00_01)。
总之,Go 处理二进制、十六进制、虚数和八进制数。八进制数以 0 开始。然而,为了提高可读性并避免未来代码读者的潜在错误,使用前缀0o使八进制数显式化。
下一节深入探讨整数,我们将讨论如何在 Go 中处理溢出。
3.2 #18:忽略整数溢出
不了解 Go 中如何处理整数溢出会导致严重的错误。本节将深入探讨这个主题。但首先,让我们提醒自己一些与整数相关的概念。
3.2.1 概念
Go 一共提供了 10 种整数类型。有四种有符号整数类型和四种无符号整数类型,如下表所示。
| 有符号整数 | 无符号整数 |
|---|---|
int8 (8 位) |
uint8 (8 位) |
int16 (16 位) |
uint16 (16 位) |
int32 (32 位) |
uint32 (32 位) |
int64 (64 位) |
uint64 (64 位) |
另外两个整数类型是最常用的:和int。这两种类型的大小取决于系统:在 32 位系统上是 32 位,在 64 位系统上是 64 位。
现在让我们讨论溢出。假设我们想要初始化一个int32到它的最大值,然后递增它。这段代码的行为应该是什么?
var counter int32 = math.MaxInt32
counter++
fmt.Printf("counter=%dn", counter)
这段代码可以编译,并且在运行时不会恐慌。然而,counter++语句会产生一个整数溢出:
counter=-2147483648
当算术运算创建的值超出了可以用给定字节数表示的范围时,就会发生整数溢出。使用 32 位来表示一个int32。下面是最大int32值(math.MaxInt32)的二进制表示:
01111111111111111111111111111111
|------31 bits set to 1-------|
因为一个int32是一个有符号的整数,左边的位代表整数的符号:0 代表正数,1 代表负数。如果我们增加这个整数,就没有空间来表示新值了。因此,这会导致整数溢出。从二进制角度来看,新值如下:
10000000000000000000000000000000
|------31 bits set to 0-------|
正如我们所看到的,位号现在等于 1,意味着负。该值是用 32 位表示的有符号整数的最小可能值。
注意最小可能的负值不是111111111111111111111111 11111111。事实上,大多数系统依靠二进制补码运算来表示二进制数(反转每一位并加 1)。这个操作的主要目标是使x+(–x)等于 0,而不管x。
在 Go 中,可以在编译时检测到的整数溢出会产生编译错误。举个例子,
var counter int32 = math.MaxInt32 + 1
constant 2147483648 overflows int32
然而,在运行时,整数溢出或下溢是无声的;这不会导致应用恐慌。将这种行为牢记在心是很重要的,因为它会导致偷偷摸摸的错误(例如,导致负结果的整数递增或正整数相加)。
在深入研究如何用常见操作检测整数溢出之前,让我们考虑一下什么时候应该关注它。在大多数情况下,比如处理请求的计数器或者基本的加法/乘法,如果使用了正确的整数类型,我们不应该太担心。但是在某些情况下,比如使用较小整数类型的内存受限项目,处理较大的数字,或者进行转换,我们可能想要检查可能的溢出。
请注意,1996 年阿丽亚娜 5 号发射失败(www.bugsnag.com/blog/bug-day-ariane-5-disaster)是由于将 64 位浮点转换为 16 位有符号整数导致溢出。
3.2.2 递增时检测整数溢出
如果我们想在基于定义的大小(int8、int16、int32、int64、uint8、uint16、uint32或uint64)的类型的递增操作期间检测整数溢出,我们可以对照math常量检查该值。例如,用一个int32:
func Inc32(counter int32) int32 {
if counter == math.MaxInt32 { // ❶
panic("int32 overflow")
}
return counter + 1
}
❶ 与math.MaxInt32作比较。
该函数检查输入是否已经等于math.MaxInt32。我们知道增量是否会导致溢出,如果是这样的话。
int和uint类型有哪些?在 Go 1.17 之前,我们必须手动构建这些常量。现在,math.MaxInt、math.MinInt和math.MaxUint是包math的一部分。如果我们必须在和int类型上测试溢出,我们可以使用math.MaxInt来完成:
func IncInt(counter int) int {
if counter == math.MaxInt {
panic("int overflow")
}
return counter + 1
}
对于uint来说,逻辑是相同的。我们可以使用math.MaxUint:
func IncUint(counter uint) uint {
if counter == math.MaxUint {
panic("uint overflow")
}
return counter + 1
}
在这一节中,我们学习了如何在增量运算后检查整数溢出。那么,加法呢?
3.2.3 加法期间检测整数溢出
如何检测加法运算中的整数溢出?答案是重用math.MaxInt:
func AddInt(a, b int) int {
if a > math.MaxInt-b { // ❶
panic("int overflow")
}
return a + b
}
❶ 检查是否会发生整数溢出
在示例中,a和b是两个操作数。如果a大于math.MaxInt - b,运算将导致整数溢出。现在,让我们看看乘法运算。
3.2.4 在乘法期间检测整数溢出
乘法处理起来有点复杂。我们必须根据最小整数math.MinInt进行检查:
func MultiplyInt(a, b int) int {
if a == 0 || b == 0 { // ❶
return 0
}
result := a * b
if a == 1 || b == 1 { // ❷
return result
}
if a == math.MinInt || b == math.MinInt { // ❸
panic("integer overflow")
}
if result/b != a { // ❹
panic("integer overflow")
}
return result
}
❶ 如果其中一个操作数等于 0,它直接返回 0。
❷ 检查操作数之一是否等于 1
❸ 检查是否有一个操作数等于数学。米尼特
❹ 检查乘法运算是否会导致整数溢出
用乘法检查整数溢出需要多个步骤。首先,我们需要测试操作数之一是否等于0、1或math.MinInt。然后我们将乘法结果除以b。如果结果不等于原始因子(a,则意味着发生了整数溢出。
总之,整数溢出(和下溢)是 Go 中的无声操作。如果我们想检查溢出以避免偷偷摸摸的错误,我们可以使用本节中描述的实用函数。还要记住 Go 提供了一个处理大数的包:math/big。如果一个int还不够,这可能是一个选择。
我们将在下一节继续讨论浮点的基本 Go 类型。
3.3 #19:不理解浮点
在GO中,有两种浮点类型(如果我们省略虚数的话):float32和float64。发明浮点的概念是为了解决整数的主要问题:它们不能表示小数值。为了避免糟糕的意外,我们需要知道浮点运算是实数运算的近似。让我们来看看使用近似值的影响以及如何提高精确度。为此,我们来看一个乘法示例:
var n float32 = 1.0001
fmt.Println(n * n)
我们可能期望这段代码打印出1.0001 * 1.0001 = 1.00020001的结果,对吗?但是,在大多数 x86 处理器上运行它会打印出 1.0002。我们该如何解释?我们需要先了解浮点运算。
让我们以float64型为例。请注意,在math.SmallestNonzeroFloat64(最小值float64)和math.MaxFloat64(最大值float64)之间有无限多个实数值。相反,float64类型有有限的位数:64。因为让无限的值适合一个有限的空间是不可能的,我们必须使用近似值。因此,我们可能会失去精度。同样的逻辑也适用于和float32型。
Go 中的浮点遵循 IEEE-754 标准,一些位代表尾数,其他位代表指数。尾数是基值,而指数是应用于尾数的乘数。在单精度浮点类型(float32)中,8 位表示指数,23 位表示尾数。在双精度浮点类型(float64)中,指数和尾数的值分别是 11 位和 52 位。剩余的位用于符号。要将浮点转换为小数,我们使用以下计算方法:
sign * 2^exponent * mantissa
图 3.1 将 1.0001 表示为一个float32。指数使用 8 位超额/偏差符号:01111111 指数值表示2^0,而尾数等于 1.000100016593933。(注意,本节的范围不是解释转换是如何工作的。)因此,十进制值等于1 × 2^0 × 1.000100016593933。因此,我们在单精度浮点值中存储的不是 1.0001,而是 1.000100016593933。缺乏精度会影响存储值的准确性。

图 3.1float32中 1.0001 的表示
一旦我们理解了float32和float64是近似值,这对我们作为开发者意味着什么呢?第一个含义与比较有关。使用==操作符来比较两个浮点数会导致不准确。相反,我们应该比较它们的差异,看它是否小于某个小错误值。例如,testify测试库(github.com/stretchr/testify)有一个InDelta函数来断言两个值在彼此给定的增量内。
还要记住,浮点计算的结果取决于实际的处理器。大多数处理器都有一个浮点单元(FPU)来处理这样的计算。不能保证在一台机器上执行的结果在另一台具有不同 FPU 的机器上是相同的。使用 delta 比较两个值是在不同机器上实现有效测试的一种解决方案。
浮点数的种类
Go 还有三种特殊的浮点数:
根据 IEEE-754,NaN 是唯一满足f != f的浮点数。下面是一个构建这些特殊类型的数字以及输出的示例:
var a float64
positiveInf := 1 / a
negativeInf := -1 / a
nan := a / a
fmt.Println(positiveInf, negativeInf, nan)
+Inf -Inf NaN
我们可以用math.IsInf检查一个浮点数是否无穷大,用math.IsNaN检查它是否为 NaN。
到目前为止,我们已经看到十进制到浮点的转换会导致精度的损失。这是转换造成的错误。还要注意,错误会在一系列浮点运算中累积。
让我们来看一个例子,其中有两个函数以不同的顺序执行相同的操作序列。在我们的例子中,f1通过将一个float64初始化为 10,000 开始,然后重复地将 1.0001 加到这个结果上(n次)。反之,f2执行相同的操作,但顺序相反(最后加 10,000):
func f1(n int) float64 {
result := 10_000.
for i := 0; i < n; i++ {
result += 1.0001
}
return result
}
func f2(n int) float64 {
result := 0.
for i := 0; i < n; i++ {
result += 1.0001
}
return result + 10_000.
}
现在,让我们在 x86 处理器上运行这些函数。然而这一次,我们将改变n。
n |
确切的结果 | f1 |
f2 |
|---|---|---|---|
| 10 | 10010.001 | 10010.000999999993 | 10010.001 |
| 1k | 11000.1 | 11000.099999999293 | 11000.099999999982 |
| 1m | 1.0101e+06 | 1.0100999999761417e+06 | 1.010099999766762 e+06 |
注意n越大,不精确性越大。不过我们也可以看到f2的精度比f1好。请记住,浮点计算的顺序会影响结果的准确性。
当执行一连串的加法和减法时,我们应该将运算分组,以便在加或减幅度不接近的值之前加或减幅度相似的值。因为f2加了 10000,最后产生的结果比f1更准确。
a × (b + c)
我们知道,这个计算等于
a × b + a × c
让我们用与b和c不同数量级的a来运行这两个计算:
a := 100000.001
b := 1.0001
c := 1.0002
fmt.Println(a * (b + c))
fmt.Println(a*b + a*c)
200030.00200030004
200030.0020003
精确的结果是 200,030.002。因此,第一种计算的准确性最差。事实上,当执行涉及加、减、乘或除的浮点计算时,我们必须首先完成乘法和除法运算才能获得更好的精度。有时,这可能会影响执行时间(在前面的示例中,它需要三个操作,而不是两个)。在这种情况下,这是准确性和执行时间之间的选择。
Go 的float32和float64是近似值。因此,我们必须牢记一些规则:
下一节开始我们对切片的研究。它讨论了两个至关重要的概念:切片的长度和容量。
3.4 #20:不了解切片长度和容量
Go 开发者混淆切片长度和容量或者没有彻底理解它们是很常见的。吸收这两个概念对于有效处理核心操作是必不可少的,比如切片初始化和用append添加元素、复制或切片。这种误解可能导致次优地使用切片,甚至导致内存泄漏(我们将在后面的章节中看到)。
在 Go 中,一个切片由一个数组支持。这意味着切片的数据连续存储在一个数组数据结构中。切片还处理在后备数组已满时添加元素或在后备数组几乎为空时收缩后备数组的逻辑。
在内部,一个片包含一个指向后备数组的指针,加上一个长度和一个容量。长度是切片包含的元素数量,而容量是支持数组中的元素数量。让我们来看几个例子,让事情更清楚。首先,让我们用给定的长度和容量初始化一个切片:
s := make([]int, 3, 6) // ❶
❶ 长度为三,容量为六的切片
第一个参数代表长度,是必需的。但是,代表容量的第二个参数是可选的。图 3.2 显示了这段代码在内存中的结果。

图 3.2 一个三长度、六容量的切片
在本例中,make创建了一个包含六个元素(容量)的数组。但是因为长度被设置为3,Go 只初始化前三个元素。此外,因为切片是一个[]int类型的,前三个元素被初始化为一个int : 0的零值。灰色元素已分配但尚未使用。
如果我们打印这个切片,我们得到长度范围内的元素,[0 0 0]。如果我们将s[1]设置为1,切片的第二个元素会更新,而不会影响其长度或容量。图 3.3 说明了这一点。
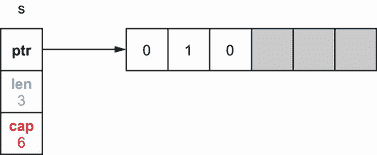
图 3.3 更新切片的第二个元素:s[1] = 1
然而,访问长度范围之外的元素是被禁止的,即使它已经在内存中被分配了。例如,s[4] = 0会导致以下恐慌:
panic: runtime error: index out of range [4] with length 3
s = append(s, 2)
这段代码向现有的s切片追加一个新元素。它使用第一个灰显的元素(已分配但尚未使用)来存储元素2,如图 3.4 所示。
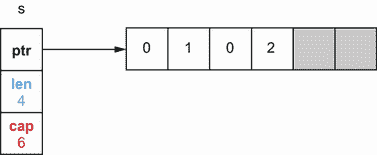
图 3.4 将元素添加到s
切片的长度从 3 更新为 4,因为切片现在包含四个元素。现在,如果我们再添加三个元素,使得支持数组不够大,会发生什么呢?
s = append(s, 3, 4, 5)
fmt.Println(s)
如果我们运行这段代码,我们会看到切片能够处理我们的请求:
[0 1 0 2 3 4 5]
因为数组是固定大小的结构,所以它可以存储新元素,直到元素 4。当我们想要插入元素 5 时,数组已经满了:Go 内部通过将容量加倍,复制所有元素,然后插入元素 5 来创建另一个数组。图 3.5 显示了这个过程。
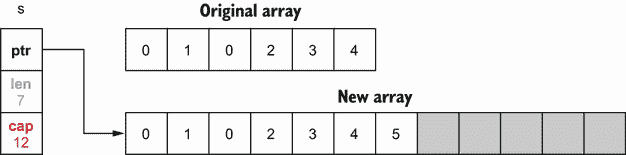
图 3.5 由于初始后备数组已满,Go 创建另一个数组并复制所有元素。
注意在 Go 中,一个切片的大小增加一倍,直到它包含 1,024 个元素,之后增长 25%。
切片现在引用新的支持数组。之前的后备数组会怎么样?如果不再被引用,如果被分配到堆上,它最终会被垃圾收集器(GC)释放。(我们在错误#95“不理解栈和堆”中讨论堆内存,我们在错误#99“不理解 GC 如何工作”中查看 GC 如何工作)
切片会发生什么?切片是在数组或切片上做的操作,提供半开范围;包括第一个索引,而排除第二个索引。以下示例显示了影响,图 3.6 显示了内存中的结果:
s1 := make([]int, 3, 6) // ❶
s2 := s1[1:3] // ❷
❶ 长度为三,容量为六的切片
❷ 从索引 1 到 3 的切片

图 3.6 切片s1和s2引用了具有不同长度和容量的相同支持数组。
首先,s1被创建为三长度、六容量的切片。当通过切片s1创建s2时,两个切片引用同一个后备数组。然而,s2从不同的索引 1 开始。所以它的长度和容量(一个两长度,五容量切片)和s1不一样。如果我们更新s1[1]或s2[0],变化是对同一个数组进行的,因此,在两个切片中都可见,如图 3.7 所示。
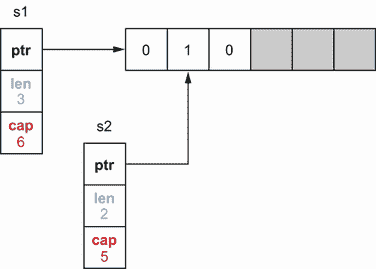
图 3.7 因为s1和s2是由同一个数组支持的,更新一个公共元素会使变化在两个切片中都可见。
现在,如果我们向s2追加一个元素会发生什么?下面的代码也改变了s1吗?
s2 = append(s2, 2)
共享后备数组被修改,但只有s2的长度改变。图 3.8 显示了向s2追加一个元素的结果。

图 3.8 将元素添加到s2
s1仍然是三长度、六容量的切片。因此,如果我们打印s1和s2,添加的元素仅对s2可见:
s1=[0 1 0], s2=[1 0 2]
理解这种行为很重要,这样我们在使用append时就不会做出错误的假设。
注意在这些例子中,支持数组是内部的,Go 开发者不能直接使用。唯一的例外是通过对现有数组切片来创建切片。
最后要注意的一点是:如果我们一直将元素追加到s2直到后备数组满了会怎么样?就内存而言,状态会是什么?让我们再添加三个元素,这样后备数组将没有足够的容量:
s2 = append(s2, 3)
s2 = append(s2, 4)
s2 = append(s2, 5) // ❶
❶ 在这个阶段,后备数组已经满了。
这段代码导致创建另一个后备数组。图 3.9 显示了内存中的结果。

图 3.9 将元素追加到s2直到后备数组已满
s1和s2现在引用了两个不同的数组。由于s1仍然是一个三长度、六容量的片,它仍然有一些可用的缓冲区,所以它继续引用初始数组。此外,新的支持数组是通过从s2的第一个索引复制初始数组制成的。这就是为什么新数组从元素1开始,而不是0。
总而言之,切片长度是切片中可用元素的数量,而切片容量是后备数组中元素的数量。将一个元素添加到一个完整的片(length == capacity)会导致创建一个具有新容量的新后备数组,从以前的数组中复制所有元素,并将片指针更新到新数组。
在下一节中,我们将长度和容量的概念用于片初始化。
3.5 #21:低效的切片初始化
在使用make初始化一个片时,我们看到我们必须提供一个长度和一个可选容量。忘记为这两个参数传递合适的值是一个普遍的错误。让我们精确地看看什么时候这被认为是合适的。
假设我们想要实现一个convert函数,将一个Foo的片映射到一个Bar的片,两个片将具有相同数量的元素。这是第一个实现:
func convert(foos []Foo) []Bar {
bars := make([]Bar, 0) // ❶
for _, foo := range foos {
bars = append(bars, fooToBar(foo)) // ❷
}
return bars
}
❶ 创建结果切片
❷ 将一个Foo转换成一个Bar,并将其添加到切片中
首先,我们使用make([]Bar, 0)初始化一个空的Bar元素片段。然后,我们使用append来添加Bar元素。起初,bars是空的,所以添加第一个元素会分配一个大小为 1 的后备数组。每当后备数组满了,Go 就通过加倍其容量来创建另一个数组(在上一节中讨论过)。
当我们添加第三个元素、第五个元素、第九个元素等等时,这种因为当前数组已满而创建另一个数组的逻辑会重复多次。假设输入切片有 1,000 个元素,该算法需要分配 10 个后备数组,并将总共 1,000 多个元素从一个数组复制到另一个数组。这导致了 GC 清理所有这些临时后备数组的额外工作。
就性能而言,没有什么好的理由不帮助 Go 运行时。对此有两种不同的选择。第一种选择是重用相同的代码,但分配给定容量的片:
func convert(foos []Foo) []Bar {
n := len(foos)
bars := make([]Bar, 0, n) // ❶
for _, foo := range foos {
bars = append(bars, fooToBar(foo)) // ❷
}
return bars
}
❶ 用零长度和给定的容量初始化
❷ 追加一个新元素并更新bar
唯一的变化是创建容量等于n、长度为foos的bars。
在内部,Go 预分配了一个由n个元素组成的数组。因此,增加 n 个元素意味着重用相同的后备数组,从而大大减少分配的数量。第二种选择是分配给定长度的bars:
func convert(foos []Foo) []Bar {
n := len(foos)
bars := make([]Bar, n) // ❶
for i, foo := range foos {
bars[i] = fooToBar(foo) // ❷
}
return bars
}
❶ 用给定的长度初始化
❷ 设置切片的元素i
因为我们用长度初始化切片,所以已经分配了n个元素并将其初始化为零值Bar。因此,要设置元素,我们必须使用bars[i]而不是append。
哪个选项最好?让我们用这三个解决方案和 100 万个元素的输入片段运行一个基准测试:
BenchmarkConvert_EmptySlice-4 22 49739882 ns/op // ❶
BenchmarkConvert_GivenCapacity-4 86 13438544 ns/op // ❷
BenchmarkConvert_GivenLength-4 91 12800411 ns/op // ❸
❶ 第一个解决方案是空切片
❷ 第二个解决方案使用给定容量并追加
❸ 第三个解决方案使用给定长度,并设置元素i
正如我们所看到的,第一个解决方案对性能有重大影响。当我们不断分配数组和复制元素时,第一个基准测试比另外两个几乎慢了 400%。比较第二个和第三个解决方案,第三个方案大约快 4%,因为我们避免了重复调用内置的append函数,与直接赋值相比,它的开销很小。
如果设置一个容量并使用append比设置一个长度并分配给一个直接索引效率更低,为什么我们看到这种方法在 Go 项目中使用?我们来看 Pebble 中的一个具体例子,这是蟑螂实验室(github.com/cockroachdb/pebble)开发的一个开源键值存储。
一个名为collectAllUserKeys的函数需要遍历一片结构来格式化一个特定的字节切片。结果切片的长度将是输入切片的两倍:
func collectAllUserKeys(cmp Compare,
tombstones []tombstoneWithLevel) [][]byte {
keys := make([][]byte, 0, len(tombstones)*2)
for _, t := range tombstones {
keys = append(keys, t.Start.UserKey)
keys = append(keys, t.End)
}
// ...
}
这里,有意识的选择是使用给定的容量和append。有什么道理?如果我们使用给定的长度而不是容量,代码将如下所示:
func collectAllUserKeys(cmp Compare,
tombstones []tombstoneWithLevel) [][]byte {
keys := make([][]byte, len(tombstones)*2)
for i, t := range tombstones {
keys[i*2] = t.Start.UserKey
keys[i*2+1] = t.End
}
// ...
}
注意处理切片索引的代码看起来有多复杂。鉴于这个函数对性能不敏感,我们决定选择最容易读取的选项。
切片和条件
如果不能精确知道切片的未来长度会怎样?例如,如果输出切片的长度取决于某个条件,那该怎么办?
func convert(foos []Foo) []Bar {
// bars initialization
for _, foo := range foos {
if something(foo) { // ❶
// Add a bar element
}
}
return bars
}
❶ 只有在特定条件有效时才添加Foo元素。
在这个例子中,一个Foo元素被转换成一个Bar,并仅在特定条件下(if something(foo))被添加到切片中。我们应该将bars初始化为一个空片还是给定长度或容量?
这里没有严格的规定。这是一个传统的软件问题:CPU 和内存哪个更好交易?也许如果something(foo)在 99%的情况下为真,那么用一个长度或容量初始化bars是值得的。这取决于我们的用例。
将一种切片类型转换成另一种切片类型是 Go 开发人员经常进行的操作。正如我们所看到的,如果未来片的长度是已知的,就没有理由先分配一个空片。我们的选择是分配具有给定容量或给定长度的存储片。在这两种解决方案中,我们已经看到第二种方案要稍微快一些。但是在某些情况下,使用给定的容量和append会更容易实现和读取。
下一节将讨论nil和空切片之间的区别,以及为什么它对 Go 开发者很重要。
3.6 #22:对nil切片和空切片感到困惑
Go 开发者相当频繁地混合nil和空切片。根据具体的使用情况,我们可能希望使用其中的一个。同时,一些库对两者进行了区分。要精通切片,我们需要确保不混淆这些概念。在查看示例之前,让我们先讨论一些定义:
-
如果切片长度等于
0,则切片为空。 -
如果切片等于
nil,则该片为零。
现在,让我们看看初始化切片的不同方法。你能猜出下面代码的输出吗?每次,我们将打印切片是空还是零:
func main() {
var s []string // ❶
log(1, s)
s = []string(nil) // ❷
log(2, s)
s = []string{} // ❸
log(3, s)
s = make([]string, 0) // ❹
log(4, s)
}
func log(i int, s []string) {
fmt.Printf("%d: empty=%ttnil=%tn", i, len(s) == 0, s == nil)
}
❶ 选项 1 (nil值)
❷ 选项 2
❸ 选项 3
❹ 选项 4
此示例打印以下内容:
1: empty=true nil=true
2: empty=true nil=true
3: empty=true nil=false
4: empty=true nil=false
所有切片都是空的,意味着长度等于0。因此,nil切片也是一个空切片。但是,只有前两个是nil切片。如果我们有多种初始化切片的方法,我们应该选择哪一种?有两件事需要注意:
-
nil切片和空切片的主要区别之一是分配。初始化一个nil切片不需要任何分配,而对于一个空的片来说就不是这样了。 -
不管一个片是否为零,调用
append内置函数都有效。举个例子,
var s1 []string
fmt.Println(append(s1, "foo")) // [foo]
因此,如果一个函数返回一个片,我们不应该像在其他语言中那样,出于防御原因返回一个非零集合。因为一个零片不需要任何分配,我们应该倾向于返回一个零片而不是一个空片。让我们看看这个函数,它返回一段字符串:
func f() []string {
var s []string
if foo() {
s = append(s, "foo")
}
if bar() {
s = append(s, "bar")
}
return s
}
如果foo和bar都为假,我们得到一个空切片。为了防止在没有特殊原因的情况下分配一个空片,我们应该选择选项 1 ( var s []string)。我们可以将选项 4 ( make([]string, 0))与零长度字符串一起使用,但是这样做与选项 1 相比并不会带来任何价值;它需要一个分配。
但是,在我们必须生成一个已知长度的切片的情况下,我们应该使用选项 4,s := make([]string, length),如本例所示:
func intsToStrings(ints []int) []string {
s := make([]string, len(ints))
for i, v := range ints {
s[i] = strconv.Itoa(v)
}
return s
}
正如错误#21“低效的片初始化”中所讨论的,我们需要在这样的场景中设置长度(或容量),以避免额外的分配和拷贝。现在,示例中剩下了两个选项,这两个选项研究了初始化切片的不同方法:
-
选项 2:
s := []string(nil) -
选项 3:
s := []string{}
选项 2 并不是使用最广泛的。但是它作为语法糖是有帮助的,因为我们可以在一行中传递一个nil切片——例如,使用append:
s := append([]int(nil), 42)
如果我们使用选项 1 ( var s []string),它将需要两行代码。这可能不是有史以来最重要的可读性优化,但仍然值得了解。
请注意,在错误#24“没有正确制作切片副本”中,我们将看到一个附加到nil切片的基本原理。
现在,我们来看选项 3: s := []string{}。建议使用此表单创建具有初始元素的切片:
s := []string{"foo", "bar", "baz"}
但是,如果我们不需要用初始元素创建切片,我们就不应该使用这个选项。它带来了与选项 1 ( var s []string)相同的好处,只是切片不是零;因此,它需要分配。因此,应避免没有初始要素的选项 3。
注意,有些 linters 可以在没有初始值的情况下捕捉选项 3,并建议将其更改为选项 1。然而,我们应该记住,这也将语义从非零片改变为零片。
我们还应该提到,一些库区分nil和空片。例如,encoding/json包装就是这种情况。下面的示例封送两个结构,一个包含nil切片,另一个包含非零的空切片:
var s1 []float32 // ❶
customer1 := customer{
ID: "foo",
Operations: s1,
}
b, _ := json.Marshal(customer1)
fmt.Println(string(b))
s2 := make([]float32, 0) // ❷
customer2 := customer{
ID: "bar",
Operations: s2,
}
b, _ = json.Marshal(customer2)
fmt.Println(string(b))
❶ nil切片
❷ 非nil,空切片
运行此示例时,请注意这两个结构的封送处理结果是不同的:
{"ID":"foo","Operations":null}
{"ID":"bar","Operations":[]}
这里,一个nil切片作为一个null元素被封送,而一个非nil的空片作为一个空数组被封送。如果我们在区分null和[]的严格 JSON 客户端的环境中工作,记住这种区别是很重要的。
encoding/json包并不是标准库中唯一做出这种区分的包。例如,如果我们比较一个nil和一个非零的空片,那么reflect.DeepEqual返回false,这是在单元测试的上下文中需要记住的。在任何情况下,当使用标准库或外部库时,我们应该确保当使用一个或另一个版本时,我们的代码不会导致意外的结果。
总结一下,在GO中,nil和空切片是有区别的。nil切片等于nil,而空切片的长度为零。nil切片是空的,但空切片不一定是nil。同时,nil切片不需要任何分配。在本节中,我们已经看到了如何通过使用
如果我们初始化没有元素的切片,那么应该避免最后一个选项[]string{}。最后,让我们检查一下我们使用的库是否区分了nil和空片以防止意外行为。
在下一节中,我们将继续这一讨论,并了解在调用函数后检查空片的最佳方式。
3.7 #23:未正确检查切片是否为空
我们在上一节看到了nil和空切片是有区别的。记住这些概念后,检查切片是否包含元素的惯用方法是什么?没有明确的答案会导致微妙的错误。
在这个例子中,我们调用一个返回一部分float32的getOperations函数。只有当切片包含元素时,我们才希望调用一个handle函数。这是第一个(错误的)版本:
func handleOperations(id string) {
operations := getOperations(id)
if operations != nil { // ❶
handle(operations)
}
}
func getOperations(id string) []float32 {
operations := make([]float32, 0) // ❷
if id == "" {
return operations // ❸
}
// Add elements to operations
return operations
}
❶ 检查operations切片是否为nil
❷ 初始化operations切片
❸ 如果提供的id为空,将返回operations
我们通过检查operations切片是否不是nil来确定切片是否有元素。但是这段代码有一个问题:getOperations从不返回一个nil切片;相反,它返回一个空切片。因此,operations != nil检查将始终为true。
在这种情况下我们该怎么办?一种方法可能是修改getOperations以在id为空时返回一个nil切片:
func getOperations(id string) []float32 {
operations := make([]float32, 0)
if id == "" {
return nil // ❶
}
// Add elements to operations
return operations
}
❶ 返回nil而不是operations
如果id为空,我们返回nil,而不是返回operations。这样,我们实现的关于测试片无效匹配的检查。然而,这种方法并不适用于所有情况——我们并不总是处于可以改变被调用者的环境中。例如,如果我们使用一个外部库,我们就不会创建一个拉取请求来将空变成nil切片。
那么我们如何检查一个片是空的还是零呢?解决方法是检查长度:
func handleOperations(id string) {
operations := getOperations(id)
if len(operations) != 0 { // ❶
handle(operations)
}
}
❶ 检查切片长度
我们在上一节中提到,根据定义,空切片的长度为零。同时,nil切片总是空的。因此,通过检查切片的长度,我们涵盖了所有场景:
-
如果切片为
nil,len(operations) != 0为false。 -
如果切片不是
nil而是空的,len(operations) != 0也是false。
因此,检查长度是最好的选择,因为我们不能总是控制我们调用的函数所采用的方法。与此同时,正如 Go wiki 所言,在设计接口时,我们应该避免区分nil和空切片,这会导致微妙的编程错误。当返回切片时,如果我们返回一个nil或空的切片,应该不会产生语义或技术上的差异。对于调用者来说,这两个词的意思应该是一样的。这个原理同样适用于映射。要检查映射是否为空,要检查它的长度,而不是它是否是nil。
3.8 #24:没有正确制作切片副本
copy内置函数允许将元素从源片复制到目标片。虽然它是一个方便的内置函数,但 Go 开发者有时会误解它。让我们来看一个导致复制错误数量的元素的常见错误。
在下面的示例中,我们创建了一个切片,并将其元素复制到另一个切片中。这段代码的输出应该是什么?
src := []int{0, 1, 2}
var dst []int
copy(dst, src)
fmt.Println(dst)
如果我们运行这个例子,它打印的是[],而不是[0 1 2]。我们错过了什么?
为了有效地使用copy,必须了解复制到目标切片的元素数量对应于以下值中的最小值:
-
源切片的长度
-
目标切片的长度
在前面的例子中,src是一个三长度切片,但是dst是一个零长度切片,因为它被初始化为零值。因此,copy函数复制了最小数量的元素(在 3 和 0 之间):在这种情况下为 0。结果切片是空的。
如果我们要执行完整拷贝,目标切片的长度必须大于或等于源切片的长度。这里,我们根据源切片设置长度:
src := []int{0, 1, 2}
dst := make([]int, len(src)) // ❶
copy(dst, src)
fmt.Println(dst)
❶ 创建一个dst切片,但具有给定的长度
因为dst现在是一个长度等于 3 的初始化切片,所以它复制了三个元素。这一次,如果我们运行代码,它会打印出[0 1 2]。
注意另一个常见的错误是在调用copy时颠倒参数的顺序。请记住,目的地是前一个参数,而来源是后一个参数。
我们还要提到,使用copy内置函数并不是复制切片元素的唯一方式。有不同的选择,最著名的可能是下面的,它使用了append:
src := []int{0, 1, 2}
dst := append([]int(nil), src...)
我们将源切片中的元素添加到一个nil切片中。因此,这段代码创建了一个三长度、三容量的切片副本。这种方法的优点是可以在一行中完成。然而,使用copy更符合习惯,因此更容易理解,尽管它需要额外的一行。
将元素从一个片复制到另一个片是相当频繁的操作。使用copy时,我们必须记住复制到目的地的元素数量对应于两个切片长度之间的最小值。还要记住,复制切片还有其他选择,所以如果我们在代码库中找到它们,我们也不应该感到惊讶。
我们继续讨论使用append时常见错误的切片。
3.9 #25:使用切片附加的意外副作用
本节讨论使用append时的一个常见错误,在某些情况下可能会产生意想不到的副作用。在下面的例子中,我们初始化一个s1切片,通过切片s1创建s2,通过向s2追加一个元素创建s3:
s1 := []int{1, 2, 3}
s2 := s1[1:2]
s3 := append(s2, 10)
我们初始化一个包含三个元素的s1切片,从切片s1中创建s2。然后我们在s3上调用append。这段代码结尾的这三个切片应该是什么状态?你能猜到吗?
在第二行之后,创建了s2之后,图 3.10 显示了内存中两个片的状态。s1是一个三长度、三容量的片,s2是一个一长度、两容量的片,两者都由我们已经提到的相同数组支持。使用append添加一个元素检查切片是否已满(长度==容量)。如果未满,append函数通过更新后备数组并返回长度增加 1 的切片来添加元素。
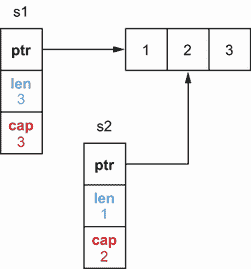
图 3.10 两个存储片都由相同的数组支持,但长度和容量不同。
在这个例子中,s2还没有满;它可以再接受一个元素。图 3.11 显示了这三个切片的最终状态。

图 3.11 所有切片都由同一个数组支持。
在后备数组中,我们更新了最后一个元素来存储10。因此,如果我们打印所有切片,我们会得到以下输出:
s1=[1 2 10], s2=[2], s3=[2 10]
虽然我们没有直接更新s1[2]或s2[1],但是s1切片的内容已经被修改。我们应该记住这一点,以避免意想不到的后果。
让我们通过将切片操作的结果传递给一个函数来看看这个原则的影响。在下面的例子中,我们用三个元素初始化一个切片,并调用一个只有前两个元素的函数:
func main() {
s := []int{1, 2, 3}
f(s[:2])
// Use s
}
func f(s []int) {
// Update s
}
在这个实现中,如果f更新了前两个元素,那么这些变化对于main中的片是可见的。然而,如果f调用append,它会更新切片的第三个元素,尽管我们只传递了两个元素。举个例子,
func main() {
s := []int{1, 2, 3}
f(s[:2])
fmt.Println(s) // [1 2 10]
}
func f(s []int) {
_ = append(s, 10)
}
如果我们出于防御原因想要保护第三个元素,意思是确保f不会更新它,我们有两个选择。
func main() {
s := []int{1, 2, 3}
sCopy := make([]int, 2)
copy(sCopy, s) // ❶
f(sCopy)
result := append(sCopy, s[2]) // ❷
// Use result
}
func f(s []int) {
// Update s
}
❶ 把s的前两个元素复制到sCopy下
❷ 将s[2]附加到sCopy上以构建结果切片
因为我们传递了一个副本给f,所以即使这个函数调用了append,也不会导致前两个元素范围之外的副作用。这个选项的缺点是,它使代码阅读起来更复杂,并且增加了一个额外的副本,如果切片很大,这可能是一个问题。
第二个选项可用于将潜在副作用的范围仅限于前两个元素。这个选项涉及到所谓的全切片表达式 : s[low:high:max]。该语句创建一个类似于用s[low:high]创建的片,除了产生的片的容量等于max - low。这里有一个调用f时的例子:
func main() {
s := []int{1, 2, 3}
f(s[:2:2]) // ❶
// Use s
}
func f(s []int) {
// Update s
}
❶ 使用完整切片表达式传递子切片
这里,传递给f的切片不是s[:2]而是s[:2:2]。因此,切片的容量为 2–0 = 2,如图 3.12 所示。
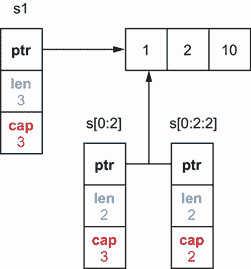
图 3.12 s[0:2]创建了一个两长度、三容量的切片,而s[0:2:2]创建了一个两长度、两容量的切片。
当通过s[:2:2]时,我们可以将效果范围限制在前两个元素。这样做还可以避免我们必须执行切片拷贝。
使用切片时,我们必须记住,我们可能会面临导致意外副作用的情况。如果结果切片的长度小于其容量,append可以改变原始切片。如果我们想限制可能的副作用的范围,我们可以使用切片复制或完整切片表达式,这将阻止我们进行复制。
在下一节中,我们将继续讨论片,但是是在潜在内存泄漏的背景下。
3.10 #26:切片和内存泄漏
本节说明了在某些情况下,对现有切片或数组进行切片会导致内存泄漏。我们讨论两种情况:一种是容量泄漏,另一种与指针有关。
3.10.1 泄漏容量
对于第一种情况,泄漏容量,让我们设想实现一个定制的二进制协议。一条消息可以包含 100 万字节,前 5 个字节代表消息类型。在我们的代码中,我们使用这些消息,出于审计目的,我们希望在内存中存储最新的 1,000 种消息类型。这是我们功能的框架:
func consumeMessages() {
for {
msg := receiveMessage() // ❶
// Do something with msg
storeMessageType(getMessageType(msg)) // ❷
}
}
func getMessageType(msg []byte) []byte { // ❸
return msg[:5]
}
❶ 收到赋值给msg的新[]byte切片
❸ 通过对消息进行切片来计算消息类型
getMessageType函数通过对输入切片进行切片来计算消息类型。我们测试了这个实现,一切正常。然而,当我们部署应用时,我们注意到应用消耗了大约 1 GB 的内存。这怎么可能呢?
使用msg[:5]在msg上的切片操作创建了一个五长度切片。但是,其容量与初始切片保持不变。剩余的元素仍然分配在内存中,即使最终msg没有被引用。让我们看一个例子,它有一个 100 万字节的大消息,如图 3.13 所示。

图 3.13 一次新的循环迭代后,msg不再使用。但是它的后备数组还是会被msg[:5]使用。
切片操作后,切片的支持数组仍包含 100 万字节。因此,如果我们在内存中保存 1,000 条消息,而不是存储大约 5 KB,我们将保存大约 1 GB。
我们能做些什么来解决这个问题?我们可以制作切片副本来代替切片msg:
func getMessageType(msg []byte) []byte {
msgType := make([]byte, 5)
copy(msgType, msg)
return msgType
}
因为我们执行复制,msgType是一个五长度、五容量的片段,不管接收到的消息有多大。因此,我们每种消息类型只存储 5 个字节。
全切片表达式和容量泄漏
用全切片表达式来解决这个问题怎么样?让我们看看这个例子:
func getMessageType(msg []byte) []byte {
return msg[:5:5]
}
这里,getMessageType返回初始切片的缩小版本:一个五长度、五容量的切片。但是 GC 能够从字节 5 中回收不可访问的空间吗?Go 规范没有正式指定行为。然而,通过使用runtime.Memstats,我们可以记录关于内存分配器的统计数据,比如在堆上分配的字节数:
func printAlloc() {
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d KBn", m.Alloc/1024)
}
如果我们在调用getMessageType和runtime.GC()之后调用这个函数来强制运行垃圾收集,不可访问的空间不会被回收。整个后备数组仍然存在于内存中。因此,使用完整切片表达式不是一个有效的选项(除非 Go 的未来更新解决了这个问题)。
根据经验,记住对一个大的切片或数组进行切片可能会导致潜在的高内存消耗。剩余的空间不会被 GC 回收,我们可以保留一个大的后备数组,尽管只使用了很少的元素。使用切片拷贝是防止这种情况的解决方案。
3.10.2 切片和指针
我们已经看到切片会因为切片容量而导致泄漏。但是元素呢,它们仍然是支持数组的一部分,但是在长度范围之外。GC 收集它们吗?
让我们使用一个包含字节切片的Foo结构来研究这个问题:
type Foo struct {
v []byte
}
我们希望在每个步骤之后检查内存分配,如下所示:
我们想看看内存在调用keepFirstTwoElementsOnly和垃圾收集之后的表现。下面是 Go 中的场景(我们重用了前面提到的printAlloc函数):
func main() {
foos := make([]Foo, 1_000) // ❶
printAlloc()
for i := 0; i < len(foos); i++ { // ❷
foos[i] = Foo{
v: make([]byte, 1024*1024),
}
}
printAlloc()
two := keepFirstTwoElementsOnly(foos) // ❸
runtime.GC() // ❹
printAlloc()
runtime.KeepAlive(two) // ❺
}
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
return foos[:2]
}
❶ 分配 1000 个元素的切片
❷ 为每个元素分配一个 1 MB 的切片
❸ 只保留了前两个元素
❹ 运行 GC 来强制清理堆
❺ 保留了对这两个变量的引用
在这个例子中,我们分配了foos片,为每个元素分配一个 1 MB 的片,然后调用keepFirstTwoElementsOnly和一个 GC。最后,我们使用runtime .KeepAlive在垃圾收集之后保留一个对two变量的引用,这样它就不会被收集。
我们可能期望 GC 收集剩余的 998 个Foo元素和为片分配的数据,因为这些元素不再能被访问。然而,事实并非如此。例如,代码可以输出以下内容:
83 KB
1024072 KB
1024072 KB // ❶
切片手术后的// ❶
第一个输出分配了大约 83 KB 的数据。的确,我们分配了 1000 个Foo的零值。第二个结果为每个片分配 1 MB,这增加了内存。但是,请注意,在最后一步之后,GC 没有收集剩余的 998 个元素。原因是什么?
使用切片时,一定要记住这条规则:如果元素是指针或带有指针字段的结构,那么元素不会被 GC 回收。在我们的例子中,因为Foo包含一个切片(切片是后备数组顶部的指针),所以剩余的 998 个Foo元素和它们的切片没有被回收。因此,即使这 998 个元素不能被访问,只要被引用了由keepFirstTwoElementsOnly返回的变量,它们就留在内存中。
有哪些选项可以确保我们不会泄露剩余的Foo元素?同样,第一个选项是创建切片的副本:
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
res := make([]Foo, 2)
copy(res, foos)
return res
}
因为我们复制了切片的前两个元素,GC 知道这 998 个元素将不再被引用,现在可以被收集了。
如果我们想要保持 1000 个元素的底层容量,还有第二个选择,就是将剩余元素的切片显式标记为nil:
func keepFirstTwoElementsOnly(foos []Foo) []Foo {
for i := 2; i < len(foos); i++ {
foos[i].v = nil
}
return foos[:2]
}
这里,我们返回一个 2 长度、1000 容量的切片,但是我们将剩余元素的切片设置为nil。因此,GC 可以收集 998 个后备数组。
哪个选项是最好的?如果我们不想将容量保持在 1000 个元素,第一个选项可能是最好的。然而,决定也可以取决于元素的比例。图 3.14 提供了一个我们可以选择的选项的可视化例子,假设一个切片包含了我们想要保存i元素的n元素。
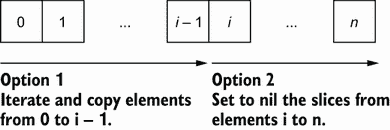
图 3.14 选项 1 迭代到i,而选项 2 从i开始迭代。
第一个选项创建一个i元素的副本。因此,它必须从元素 0 迭代到i。第二个选项将剩余的片设置为零,因此它必须从元素i迭代到n。如果性能很重要,并且i比 0 更接近于n,我们可以考虑第二个选项。这需要迭代更少的元素(至少,可能值得对这两个选项进行基准测试)。
在本节中,我们看到了两个潜在的内存泄漏问题。第一个是对现有存储片或数组进行切片以保留容量。如果我们处理大的切片并重新切片以只保留一小部分,那么大量的内存将仍然被分配但未被使用。第二个问题是,当我们使用带有指针的切片操作或带有指针字段的结构时,我们需要知道 GC 不会回收这些元素。在这种情况下,有两种选择,要么执行复制,要么显式地将剩余的元素或它们的字段标记为nil。
现在,让我们在初始化的上下文中讨论映射。
3.11 #27:低效的映射初始化
本节讨论了一个类似于切片初始化的问题,但是使用了贴图。但是首先,我们需要知道关于如何在 Go 中实现映射的基础知识,以理解为什么调整映射初始化是重要的。
3.11.1 概念
一个映射提供了一个无序的键值对集合,其中所有的键都是不同的。在 Go 中,映射是基于哈希表数据结构的。在内部,哈希表是一个桶的数组,每个桶是一个指向键值对数组的指针,如图 3.15 所示。
图 3.15 中的哈希表后面是一个由四个元素组成的数组。如果我们检查数组索引,我们会注意到一个由单个键值对(元素)组成的桶:"two" / 2。每个桶有八个元素的固定大小。

图 3.15 关注桶 0 的散列表示例
每个操作(读取、更新、插入、删除)都是通过将一个键与一个数组索引相关联来完成的。这个步骤依赖于散列函数。这个函数是稳定的,因为我们希望它返回相同的桶,给定相同的键,保持一致。在前面的例子中,hash("two")返回 0;因此,该元素存储在数组索引 0 引用的桶中。
如果我们插入另一个元素,并且散列键返回相同的索引,Go 将另一个元素添加到相同的桶中。图 3.16 显示了这个结果。
图 3.16 hash("six")返回 0;因此,元素存储在同一个桶中。
在插入一个已经满了的桶(桶溢出)的情况下,Go 创建另一个包含八个元素的桶,并将前一个桶链接到它。图 3.17 给出了这个结果。

图 3.17 在桶溢出的情况下,Go 分配一个新的桶,并将前一个桶链接到它。
关于读取、更新和删除,Go 必须计算相应的数组索引。然后 Go 依次遍历所有的键,直到找到提供的键。因此,这三个操作的最坏情况时间复杂度是O(p),其中p是桶中元素的总数(默认为一个桶,溢出时为多个桶)。
现在让我们讨论一下为什么有效地初始化映射很重要。
3.12.2 初始化
为了理解与低效的映射初始化相关的问题,让我们创建一个包含三个元素的map[string]int类型:
m := map[string]int{
"1": 1,
"2": 2,
"3": 3,
}
在内部,这个映射由一个包含单个条目的数组支持:因此,只有一个桶。如果我们增加 100 万个元素会发生什么?在这种情况下,单个条目是不够的,因为在最坏的情况下,找到一个键意味着要遍历数千个桶。这就是为什么映射应该能够自动增长以应对元素的数量。
当一个映射增长时,它的桶的数量会翻倍。映射成长的条件是什么?
当一个映射增长时,所有的键被再次分配给所有的桶。这就是为什么在最坏的情况下,插入一个键可以是一个O(n)操作,其中n是图中元素的总数。
我们看到,当使用切片时,如果我们预先知道要添加到切片中的元素数量,我们可以用给定的大小或容量初始化它。这避免了必须不断重复代价高昂的切片增长操作。这个想法对于映射来说是类似的。事实上,我们可以使用make内置函数来在创建映射时提供初始大小。例如,如果我们想要初始化一个包含一百万个元素的映射,可以这样做:
m := make(map[string]int, 1_000_000)
有了映射,我们可以只给内置函数make一个初始大小,而不是容量,就像切片一样:因此,只有一个参数。
通过指定大小,我们提供了一个关于预期进入映射的元素数量的提示。在内部,使用适当数量的存储桶来创建映射,以存储一百万个元素。这节省了大量的计算时间,因为映射不必动态创建存储桶和处理重新平衡存储桶。
此外,指定一个尺寸n并不意味着用最大数量的n元素来制作映射。如果需要,我们仍然可以添加多于 n 个元素。相反,这意味着要求 Go 运行时为至少n个元素分配一个映射空间,如果我们事先已经知道元素的大小,这是很有帮助的。
为了理解为什么指定大小很重要,让我们运行两个基准测试。第一个示例在没有设置初始大小的情况下在一个映射中插入一百万个元素,而我们用一个大小来初始化第二个映射:
BenchmarkMapWithoutSize-4 6 227413490 ns/op
BenchmarkMapWithSize-4 13 91174193 ns/op
第二个版本,初始大小,大约快 60%。通过提供一个大小,我们可以防止映射增长以适应插入的元素。
因此,就像切片一样,如果我们预先知道映射将包含的元素数量,我们应该通过提供初始大小来创建它。这样做避免了潜在的映射增长,这在计算上是相当繁重的,因为它需要重新分配足够的空间和重新平衡所有的元素。
让我们继续关于映射的讨论,看看一个导致内存泄漏的常见错误。
3.12 #28:映射和内存泄漏
在 Go 中使用映射时,我们需要了解映射如何增长和收缩的一些重要特征。让我们深入研究这个问题,以防止可能导致内存泄漏的问题。
首先,为了查看此问题的具体示例,让我们设计一个场景,其中我们将使用以下映射:
m := make(map[int][128]byte)
m的每个值都是一个 128 字节的数组。我们将执行以下操作:
-
分配一个空映射。
-
添加 100 万个元素。
-
移除所有元素,并运行 GC。
在每一步之后,我们想要打印堆的大小(这次使用 MB)。这向我们展示了这个例子在内存方面的表现:
n := 1_000_000
m := make(map[int][128]byte)
printAlloc()
for i := 0; i < n; i++ { // ❶
m[i] = randBytes()
}
printAlloc()
for i := 0; i < n; i++ { // ❷
delete(m, i)
}
runtime.GC() // ❸
printAlloc()
runtime.KeepAlive(m) // ❹
❶ 添加 100 万个元素
❷ 删除一百万个元素
❹ 保留了一个对m的引用,这样映射就不会被收集
我们分配一个空的映射,添加一百万个元素,删除一百万个元素,然后运行一个 GC。我们还确保使用runtime .KeepAlive保存对映射的引用,这样映射就不会被收集。让我们运行这个例子:
0 MB // ❶
461 MB // ❷
293 MB // ❸
❶ 在m被分配后
❷ 我们添加 100 万个元素后
❸ 在我们移除一百万个元素后
我们能观察到什么?起初,堆的大小是最小的。然后,在映射上添加了一百万个元素后,它会显著增长。但是,如果我们期望在移除所有元素后堆的大小会减小,那么这不是映射在 Go 中的工作方式。最后,即使 GC 已经收集了所有的元素,堆的大小仍然是 293 MB。所以内存缩小了,但并不像我们预期的那样。有什么道理?
我们在上一节中讨论了一个映射由八个元素的桶组成。在幕后,Go映射是一个指向runtime.hmap结构的指针。该结构包含多个字段,包括一个B字段,给出了映射中的桶数:
type hmap struct {
B uint8 // log_2 of # of buckets
// (can hold up to loadFactor * 2^B items)
// ...
}
添加 100 万个元素后,B的值等于 18,这意味着2^18 = 262144个桶。当我们去掉 100 万个元素,B的值是多少?还是 18。因此,映射仍然包含相同数量的桶。
原因是映射中的存储桶数量不能减少。因此,从映射中删除元素不会影响现有存储桶的数量;它只是将桶中的槽归零。一张映射只能成长,只能有更多的桶;它从不缩水。
在前面的例子中,我们从 461 MB 增加到 293 MB,因为收集了元素,但是运行 GC 并不影响映射本身。甚至额外桶(由于溢出而创建的桶)的数量也保持不变。
让我们后退一步,讨论一下映射不能缩小的事实何时会成为问题。想象使用map[int][128]byte构建一个缓存。这个映射包含每个客户 ID,一个 128 字节的序列。现在,假设我们想要保留最后 1000 名客户。映射大小将保持不变,所以我们不应该担心映射不能缩小的事实。
然而,假设我们想要存储一个小时的数据。与此同时,我们公司决定在黑色星期五进行一次大促销:一小时后,我们可能会有数百万客户连接到我们的系统。但是在黑色星期五之后的几天,我们的映射将包含与高峰时间相同数量的桶。这解释了为什么我们会经历高内存消耗,而在这种情况下不会显著减少。
如果我们不想手动重启服务来清理映射消耗的内存量,有什么解决方案?一种解决方案可以是定期重新创建当前映射的副本。比如每个小时,我们可以建立一个新的映射,复制所有的元素,释放上一个。这种方法的主要缺点是,在复制之后直到下一次垃圾收集之前,我们可能会在短时间内消耗两倍于当前的内存。
另一个解决方案是改变映射类型来存储数组指针:map[int]*[128]byte。它没有解决我们将会有相当数量的桶的事实;然而,每个桶条目将为该值保留指针的大小,而不是 128 字节(在 64 位系统上是 8 字节,在 32 位系统上是 4 字节)。
回到最初的场景,让我们按照每个步骤比较每个映射类型的内存消耗。下表显示了这种比较。
| 步骤 | map[int][128]byte |
map[int]*[128]byte |
|---|---|---|
| 分配一个空映射。 | 0 MB | 0 MB |
| 添加 100 万个元素。 | 461 MB | 182 MB |
| 移除所有元素并运行 GC。 | 293 MB | 38 MB |
正如我们所看到的,删除所有元素后,使用map[int]*[128]byte类型所需的内存量明显减少。此外,在这种情况下,由于一些减少内存消耗的优化,高峰时间所需的内存量不太重要。
注意如果一个键或者一个值超过 128 个字节,Go 不会把它直接存储在映射桶中。相反,Go 存储一个指针来引用键或值。
正如我们已经看到的,向一个映射添加n个元素,然后删除所有元素意味着在内存中保持相同数量的存储桶。所以,我们必须记住,因为 Go 映射的大小只会增加,所以它的内存消耗也会增加。没有自动化的策略来缩小它。如果这导致高内存消耗,我们可以尝试不同的选项,如强制 Go 重新创建映射或使用指针检查是否可以优化。
在本章的最后一节,我们来讨论在 Go 中比较数值。
3.13 #29:不正确地比较值
比较数值是软件开发中常见的操作。我们经常实现比较:编写一个函数来比较两个对象,测试来比较一个值和一个期望值,等等。我们的第一反应可能是在任何地方都使用==操作符。但是正如我们将在本节中看到的,情况不应该总是这样。那么什么时候使用==比较合适,有哪些替代方案呢?
要回答这些问题,我们先来看一个具体的例子。我们创建一个基本的customer结构并使用==来比较两个实例。在您看来,这段代码的输出应该是什么?
type customer struct {
id string
}
func main() {
cust1 := customer{id: "x"}
cust2 := customer{id: "x"}
fmt.Println(cust1 == cust2)
}
比较这两个customer结构是 Go 中的有效操作,它会打印true。现在,如果我们稍微修改一下customer结构,添加一个切片字段,会发生什么呢?
type customer struct {
id string
operations []float64 // ❶
}
func main() {
cust1 := customer{id: "x", operations: []float64{1.}}
cust2 := customer{id: "x", operations: []float64{1.}}
fmt.Println(cust1 == cust2)
}
❶ 新字段
我们可能希望这段代码也能打印出true。然而,它甚至不能编译:
invalid operation:
cust1 == cust2 (struct containing []float64 cannot be compared)
该问题与==和!=操作器的工作方式有关。这些运算符不适用于切片或贴图。因此,因为customer结构包含一个片,所以它不能编译。
了解如何使用==和!=进行有效的比较是非常重要的。我们可以在可比的操作数上使用这些操作符:
-
布尔型——比较两个布尔型是否相等。
-
字符串——比较两个字符串是否相等。
-
通道——比较两个通道是否由同一个对
make的调用创建,或者是否都是nil。 -
指针——比较两个指针是否指向内存中的同一个值或者是否都是
nil。 -
结构和数组——比较它们是否由相似的类型组成。
注意我们也可以使用⇐、>=、<和>操作符,对数字类型使用这些操作符来比较值,对字符串使用这些操作符来比较它们的词汇顺序。
在最后一个例子中,我们的代码编译失败,因为结构是在不可比较的类型(片)上构成的。
我们还需要知道将==和!=与any类型一起使用可能出现的问题。例如,允许比较分配给any类型的两个整数:
var a any = 3
var b any = 3
fmt.Println(a == b)
该代码打印:
true
但是如果我们初始化两个customer类型(最新版本包含一个切片字段)并将值赋给any类型会怎么样呢?这里有一个例子:
var cust1 any = customer{id: "x", operations: []float64{1.}}
var cust2 any = customer{id: "x", operations: []float64{1.}}
fmt.Println(cust1 == cust2)
这段代码可以编译。但是由于两种类型不能比较,因为customer结构包含一个切片字段,这导致了运行时的错误:
panic: runtime error: comparing uncomparable type main.customer
考虑到这些行为,如果我们必须比较两个切片、两个映射或者两个包含不可比较类型的结构,有什么选择呢?如果我们坚持使用标准库,一个选择是对reflect包使用运行时反射。
反射是元编程的一种形式,它指的是应用自省和修改其结构和行为的能力。比如GO,我们可以用reflect.DeepEqual。该函数通过递归遍历两个值来报告两个元素是否完全相等。它接受的元素是基本类型加上数组、结构、切片、映射、指针、接口和函数。
注意reflect.DeepEqual根据我们提供的类型有特定的行为。使用之前,请仔细阅读文档。
让我们重新运行第一个例子,添加reflect.DeepEqual:
cust1 := customer{id: "x", operations: []float64{1.}}
cust2 := customer{id: "x", operations: []float64{1.}}
fmt.Println(reflect.DeepEqual(cust1, cust2))
尽管customer结构包含不可比较的类型(slice ),但它会像预期的那样运行,打印true。
但是,在使用reflect.DeepEqual的时候,有两点需要记住。首先,它区分了空集合和nil集合,正如错误#22 中所讨论的,“混淆nil和空切片。”这是个问题吗?不一定;这取决于我们的用例。例如,如果我们想要比较两个解组操作(比如从 JSON 到 Go 结构)的结果,我们可能想要提高这个差异。但是为了有效地使用reflect.DeepEqual,记住这种行为是值得的。
另一个问题是在大多数语言中相当标准的东西。因为这个函数使用反射,即在运行时自省值以发现它们是如何形成的,所以它有一个性能损失。用不同大小的结构在本地做几个基准测试,平均来说,reflect.DeepEqual比==慢 100 倍左右。这可能是支持在测试环境中而不是在运行时使用它的原因。
如果性能是一个关键因素,另一个选择可能是实现我们自己的比较方法。下面是一个比较两个customer结构并返回布尔值的例子:
func (a customer) equal(b customer) bool {
if a.id != b.id { // ❶
return false
}
if len(a.operations) != len(b.operations) { // ❷
return false
}
for i := 0; i < len(a.operations); i++ { // ❸
if a.operations[i] != b.operations[i] {
return false
}
}
return true
}
❶ 比较id字段
❷ 检查两个切片的长度
❸ 比较了两个切片的每个元素
在这段代码中,我们用对customer结构的不同字段的自定义检查来构建我们的比较方法。在由 100 个元素组成的切片上运行本地基准测试表明,我们的定制equal方法比reflect.DeepEqual快大约 96 倍。
一般来说,我们应该记住==操作符是非常有限的。例如,它不适用于切片和贴图。在大多数情况下,使用reflect.DeepEqual是一种解决方案,但是主要的问题是性能损失。在单元测试的上下文中,一些其他的选项是可能的,比如使用带有go-cmp (github.com/google/go-cmp)或者testify (github.com/stretchr/testify)的外部库。然而,如果性能在运行时至关重要,实现我们的定制方法可能是最好的解决方案。
一个额外的注意:我们必须记住标准库有一些现有的比较方法。例如,我们可以使用优化的bytes.Compare函数来比较两个字节切片。在实现一个定制方法之前,我们需要确保我们不会重复发明轮子。
总结
-
阅读现有代码时,请记住以 0 开头的整数是八进制数。此外,为了提高可读性,通过在八进制整数前面加上前缀
0o,使它们显式。 -
因为在 Go 中整数溢出和下溢是静默处理的,所以你可以实现自己的函数来捕捉它们。
-
在给定的增量内进行浮点比较可以确保你的代码是可移植的。
-
执行加法或减法时,将具有相似数量级的运算分组,以提高精确度。还有,先做乘除,再做加减。
-
理解切片长度和容量之间的区别应该是 Go 开发人员核心知识的一部分。切片长度是切片中可用元素的数量,而切片容量是后备数组中元素的数量。
-
创建切片时,如果长度已知,用给定的长度或容量初始化切片。这减少了分配的数量并提高了性能。同样的逻辑也适用于映射,您需要初始化它们的大小。
-
如果两个不同的函数使用由同一数组支持的片,使用复制或完整片表达式是防止
append产生冲突的一种方式。但是,如果您想要收缩一个大的切片,只有切片复制可以防止内存泄漏。 -
使用指针切片或带有指针字段的结构,可以通过将切片操作排除的元素标记为
nil来避免内存泄漏。 -
为了防止常见的混淆,例如在使用
encoding/json或reflect包时,您需要理解nil切片和空切片之间的区别。两者都是零长度、零容量的片,但是只有零片不需要分配。 -
要检查切片是否不包含任何元素,请检查其长度。无论切片是
nil还是空的,该检查都有效。映射也是如此。 -
为了设计明确的 API,你不应该区分
nil和空切片。 -
一张映射在内存中可以一直增长,但永远不会缩小。因此,如果它导致一些内存问题,您可以尝试不同的选项,例如强制 Go 重新创建映射或使用指针。
-
要比较 Go 中的类型,如果两个类型是可比较的,可以使用
==和!=操作符:布尔值、数字、字符串、指针、通道和结构完全由可比较的类型组成。否则,您可以使用reflect.DeepEqual并付出反射的代价,或者使用定制的实现和库。
司、控制结构
本章涵盖
Go 中的控制结构类似于 C 或 Java 中的控制结构,但在很多方面有很大的不同。比如GO中没有do或while循环,只有一个广义的for。本章深入探讨与控制结构相关的最常见错误,重点关注循环range,这是一个常见的误解来源。
4.1 #30:忽略元素在范围循环中被复制的事实
range循环是迭代各种数据结构的便捷方式。我们不必处理索引和终止状态。Go 开发人员可能会忘记或者没有意识到range循环是如何赋值的,从而导致常见的错误。首先,让我们提醒自己如何使用一个range循环;然后我们来看看值是如何赋值的。
4.1.1 概念
一个range循环允许迭代不同的数据结构:
-
字符串
-
数组
-
指向数组的指针
-
切片
-
映射
-
接收通道
与经典的for循环相比,range循环是迭代这些数据结构中所有元素的一种便捷方式,这要归功于它简洁的语法。它也更不容易出错,因为我们不必手动处理条件表达式和迭代变量,这可以避免诸如一个接一个的错误之类的错误。下面是一个对字符串片段进行迭代的示例:
s := []string{"a", "b", "c"}
for i, v := range s {
fmt.Printf("index=%d, value=%sn", i, v)
}
这段代码循环遍历切片的每个元素。在每次迭代中,当我们迭代一个片时,range产生一对值:一个索引和一个元素值,分别分配给i和v。一般来说,range为每个数据结构生成两个值,除了接收通道,它为接收通道生成一个元素(值)。
在某些情况下,我们可能只对元素值感兴趣,而对索引不感兴趣。因为不使用局部变量会导致编译错误,所以我们可以使用空白标识符来替换索引变量,如下所示:
s := []string{"a", "b", "c"}
for _, v := range s {
fmt.Printf("value=%sn", v)
}
多亏了空白标识符,我们通过忽略索引并只将元素值赋给v来迭代每个元素。
如果我们对值不感兴趣,我们可以省略第二个元素:
for i := range s {}
既然我们已经用一个range循环刷新了我们的思维,让我们看看在一次迭代中返回什么样的值。
4.1.2 值的复制
理解在每次迭代中如何处理值对于有效使用range循环至关重要。让我们用一个具体的例子来看看它是如何工作的。
我们创建一个包含单个balance字段的account结构:
type account struct {
balance float32
}
接下来,我们创建一片account结构,并使用一个range循环遍历每个元素。在每次迭代中,我们递增每个account的balance:
accounts := []account{
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000
}
根据这段代码,您认为以下两个选项中的哪一个显示了切片的内容?
-
[{100} {200} {300}] -
[{1100} {1200} {1300}]
答案是[{100} {200} {300}]。在本例中,range循环不影响切片的内容。我们来看看为什么。
在 Go 中,我们分配的所有内容都是副本:
牢记这一点以避免常见错误是至关重要的,包括那些与range循环相关的错误。事实上,当一个range循环遍历一个数据结构时,它会将每个元素复制到值变量(第二项)。
回到我们的例子,迭代每个account元素导致一个结构体副本被赋给值变量a。因此,用a.balance += 1000增加余额只会改变值变量(a),而不会改变切片中的元素。
那么,如果我们想要更新切片元素呢?有两个主要选项。第一种选择是使用片索引访问元素。这可以通过使用索引而不是值变量的经典for循环或range循环来实现:
for i := range accounts { // ❶
accounts[i].balance += 1000
}
for i := 0; i < len(accounts); i++ { // ❷
accounts[i].balance += 1000
}
❶ 使用索引变量来访问切片的元素
❷ 使用传统的for循环
我们应该支持哪一个?这要看上下文。如果我们想检查每个元素,第一个循环读写起来会更短。但是如果我们需要控制想要更新哪个元素(比如两个中的一个),我们应该使用第二个循环。
更新切片元素:第三个选项
另一种选择是继续使用range循环并访问值,但是将切片类型修改为一个account指针切片:
accounts := []*account{ // ❶
{balance: 100.},
{balance: 200.},
{balance: 300.},
}
for _, a := range accounts {
a.balance += 1000 // ❷
}
❶ 将切片类型更新为[]*account
❷ 直接更新切片元素
在这种情况下,正如我们提到的,a变量是存储在切片中的account指针的副本。但是由于两个指针引用同一个结构,a.balance += 1000语句更新切片元素。
然而,这种选择有两个主要缺点。首先,它需要更新切片类型,这并不总是可能的。第二,如果性能很重要,我们应该注意到,由于缺乏可预测性,迭代指针片对 CPU 来说可能效率较低(我们将在错误#91“不理解 CPU 缓存”中讨论这一点)。
一般来说,我们应该记住range循环中的值元素是一个副本。因此,如果值是我们需要改变的结构,我们将只更新副本,而不是元素本身,除非我们修改的值或字段是指针。更好的选择是使用一个range循环或者一个经典的for循环通过索引访问元素。
在下一节中,我们继续使用range循环,看看如何计算提供的表达式。
4.2 #31:忽略参数在范围循环中的求值方式
range循环语法需要一个表达式。比如在for i, v := range exp,exp就是表达式。正如我们所见,它可以是一个字符串、一个数组、一个指向数组的指针、一个切片、一个映射或一个通道。现在,我们来讨论下面这个问题:这个表达式是如何评价的?使用range循环时,这是避免常见错误的要点。
让我们看看下面的例子,它将一个元素附加到我们迭代的切片上。你相信循环会终止吗?
s := []int{0, 1, 2}
for range s {
s = append(s, 10)
}
为了理解这个问题,我们应该知道当使用一个range循环时,所提供的表达式只计算一次,在循环开始之前。在这个上下文中,“求值”意味着提供的表达式被复制到一个临时变量,然后range迭代这个变量。在本例中,当对s表达式求值时,结果是一个切片副本,如图 4.1 所示。

图 4.1 s被复制到range使用的临时变量中。
range循环使用这个临时变量。原始切片s也在每次迭代期间更新。因此,在三次迭代之后,状态如图 4.2 所示。
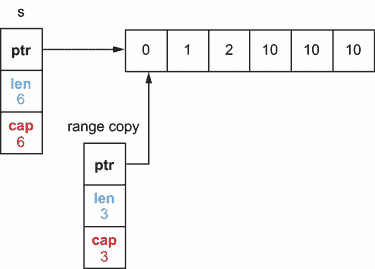
图 4.2 临时变量仍然是一个三长度的切片;因此,迭代完成。
每一步都会追加一个新元素。然而,在三个步骤之后,我们已经检查了所有的元素。实际上,range使用的临时切片仍然是三长度切片。因此,循环在三次迭代后完成。
这种行为与传统的for循环有所不同:
s := []int{0, 1, 2}
for i := 0; i < len(s); i++ {
s = append(s, 10)
}
在这个例子中,循环永远不会结束。在每次迭代中,len(s)表达式被求值,因为我们不断添加元素,所以我们永远不会到达终止状态。为了准确地使用 Go 循环,记住这一点是很重要的。
回到range操作符,我们应该知道我们描述的行为(表达式只计算一次)也适用于所有提供的数据类型。作为一个例子,让我们用另外两种类型来看看这种行为的含义:通道和数组。
4.2.1 通道
让我们看一个基于使用range循环迭代一个通道的具体例子。我们创建了两个 goroutines,都将元素发送到两个不同的通道。然后,在父 goroutine 中,我们使用一个range循环在一个通道上实现一个消费者,该循环试图在迭代期间切换到另一个通道:
ch1 := make(chan int, 3) // ❶
go func() {
ch1 <- 0
ch1 <- 1
ch1 <- 2
close(ch1)
}()
ch2 := make(chan int, 3) // ❷
go func() {
ch2 <- 10
ch2 <- 11
ch2 <- 12
close(ch2)
}()
ch := ch1 // ❸
for v := range ch { // ❹
fmt.Println(v)
ch = ch2 // ❺
}
❶ 创建包含元素 0、1 和 2 的第一个通道
❷ 创建了包含元素 10、11 和 12 的第二个通道
❸ 将第一个通道分配给ch
❹ 通过遍历ch创建了一个通道消费者
❺ 将第二通道分配给ch
在这个例子中,同样的逻辑适用于如何求值range表达式。提供给range的表达式是一个指向ch1的ch通道。因此,range对ch求值,执行对临时变量的复制,并迭代这个通道中的元素。尽管有ch = ch2语句,但是range一直在ch1上迭代,而不是ch2:
0
1
2
然而,ch = ch2声明并不是没有效果。因为我们将ch赋给了第二个变量,如果我们在这段代码后调用close(ch),它将关闭第二个通道,而不是第一个。
现在让我们来看看range操作符在使用数组时只对每个表达式求值一次的影响。
4.2.2 数组
对数组使用range循环有什么影响?因为range表达式是在循环开始之前计算的,所以分配给临时循环变量的是数组的副本。让我们通过下面的例子来看看这个原则的实际应用,这个例子在迭代过程中更新了一个特定的数组索引:
a := [3]int{0, 1, 2} // ❶
for i, v := range a { // ❷
a[2] = 10 // ❸
if i == 2 { // ❹
fmt.Println(v)
}
}
❶ 创建了一个由三个元素组成的数组
❷ 迭代数组
❸ 更新了最后一个元素
❹ 打印最后一个元素的内容
这段代码将最后一个索引更新为 10。但是,如果我们运行这段代码,它不会打印10;相反,它打印出2,如图 4.3 所示。

图 4.3 range迭代数组副本(左),同时循环修改a(右)。
正如我们提到的,range操作符创建了数组的副本。同时,循环不更新副本;它更新原始数组:a。所以最后一次迭代时v的值是2,而不是10。
如果我们想打印最后一个元素的实际值,我们可以用两种方法:
-
通过从索引中访问元素:
a := [3]int{0, 1, 2} for i := range a { a[2] = 10 if i == 2 { fmt.Println(a[2]) // ❶ } }❶ 访问
[2]而不是范围值变量因为我们访问的是原始数组,这段代码打印的是
2而不是10。 -
使用数组指针:
a := [3]int{0, 1, 2} for i, v := range &a { // ❶ a[2] = 10 if i == 2 { fmt.Println(v) } }❶ 的范围超过 1000 英镑,而不是 1000 英镑
我们将数组指针的副本分配给
range使用的临时变量。但是因为两个指针引用同一个数组,所以访问v也会返回10。
两个选项都有效。然而,第二个选项不会导致复制整个数组,这可能是在数组非常大的情况下需要记住的事情。
总之,range循环只对提供的表达式求值一次,在循环开始之前,通过复制(不考虑类型)。我们应该记住这种行为,以避免常见的错误,例如,可能导致我们访问错误的元素。
在下一节中,我们将看到如何使用带有指针的range循环来避免常见错误。
4.3 #32:忽略在范围循环中使用指针元素的影响
本节着眼于使用带有指针元素的range循环时的一个具体错误。如果我们不够谨慎,可能会导致我们引用错误的元素。让我们检查一下这个问题以及如何修复它。
在开始之前,让我们澄清一下使用指针元素切片或映射的基本原理。主要有三种情况:
-
就语义而言,使用指针语义存储数据意味着共享元素。例如,以下方法包含将元素插入缓存的逻辑:
type Store struct { m map[string]*Foo } func (s Store) Put(id string, foo *Foo) { s.m[id] = foo // ... } -
有时我们已经在操作指针了。因此,在集合中直接存储指针而不是值会很方便。
-
如果我们存储大型结构,并且这些结构经常发生改变,我们可以使用指针来避免每次改变的复制和插入:
func updateMapValue(mapValue map[string]LargeStruct, id string) { value := mapValue[id] // ❶ value.foo = "bar" mapValue[id] = value // ❷ } func updateMapPointer(mapPointer map[string]*LargeStruct, id string) { mapPointer[id].foo = "bar" // ❸ }❶拷贝
❷插页
❸直接改变了映射元素
因为
updateMapPointer接受指针映射,所以foo字段的改变可以在一个步骤中完成。
现在是时候讨论一下range循环中指针元素的常见错误了。我们将考虑以下两种结构:
-
一个代表客户的
Customer结构 -
一个
Store,它保存了一个Customer指针的映射
type Customer struct {
ID string
Balance float64
}
type Store struct {
m map[string]*Customer
}
下面的方法迭代一片Customer元素,并将它们存储在m映射中:
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
s.m[customer.ID] = &customer // ❶
}
}
❶ 将customer指针存储在映射中
在这个例子中,我们使用操作符range对输入切片进行迭代,并将Customer指针存储在映射中。但是这种方法能达到我们预期的效果吗?
让我们用三个不同的Customer结构来调用它,试一试:
s.storeCustomers([]Customer{
{ID: "1", Balance: 10},
{ID: "2", Balance: -10},
{ID: "3", Balance: 0},
})
如果我们打印映射,下面是这段代码的结果:
key=1, value=&main.Customer{ID:"3", Balance:0}
key=2, value=&main.Customer{ID:"3", Balance:0}
key=3, value=&main.Customer{ID:"3", Balance:0}
正如我们所看到的,不是存储三个不同的Customer结构,而是存储在映射中的所有元素都引用同一个Customer结构:3。我们做错了什么?
使用range循环迭代customers片,不管元素的数量,创建一个具有固定地址的单个customer变量。我们可以通过在每次迭代中打印指针地址来验证这一点:
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
fmt.Printf("%pn", &customer) // ❶
s.m[customer.ID] = &customer
}
}
0xc000096020
0xc000096020
0xc000096020
❶ 打印customer地址
为什么这很重要?让我们检查一下每个迭代:
-
在第一次迭代中,
customer引用第一个元素:Customer 1。我们存储了一个指向customer结构的指针。 -
在第二次迭代中,
customer现在引用了另一个元素:Customer 2。我们还存储了一个指向customer结构的指针。 -
最后,在最后一次迭代中,
customer引用最后一个元素:Customer 3。同样,相同的指针存储在映射中。
在迭代结束时,我们已经在映射中存储了同一个指针三次(见图 4.4)。这个指针的最后一个赋值是对切片的最后一个元素的引用:Customer 3。这就是为什么所有映射元素都引用同一个Customer。
图 4.4customer变量有一个常量地址,所以我们在映射中存储了相同的指针。
那么,我们如何解决这个问题呢?有两种主要的解决方案。第一个类似于我们在错误 1 中看到的,“非预期的变量隐藏”它需要创建一个局部变量:
func (s *Store) storeCustomers(customers []Customer) {
for _, customer := range customers {
current := customer // ❶
s.m[current.ID] = ¤t // ❷
}
}
❷ 将这个指针存储在映射中
在这个例子中,我们不存储引用customer的指针;相反,我们存储一个引用current的指针。current是在每次迭代中引用唯一Customer的变量。因此,在循环之后,我们在映射中存储了引用不同Customer结构的不同指针。另一种解决方案是使用片索引存储引用每个元素的指针:
func (s *Store) storeCustomers(customers []Customer) {
for i := range customers {
customer := &customers[i] // ❶
s.m[customer.ID] = customer // ❷
}
}
❶ 给customer分配一个i元素的指针
❷ 存储customer指针
在这个解决方案中,customer现在是一个指针。因为它是在每次迭代中初始化的,所以它有一个唯一的地址。因此,我们在映射中存储不同的指针。
当使用一个range循环迭代一个数据结构时,我们必须记住所有的值都被分配给一个具有唯一地址的唯一变量。因此,如果我们在每次迭代中存储一个引用这个变量的指针,我们将会在这样一种情况下结束:我们存储了引用同一个元素的同一个指针:最新的元素。我们可以通过在循环范围内强制创建一个局部变量或者创建一个指针通过它的索引引用一个切片元素来解决这个问题。两种解决方案都可以。还要注意,我们将切片数据结构作为输入,但是问题与映射类似。
在下一节中,我们将看到与映射迭代相关的常见错误。
4.4 #33:在映射迭代过程中做出错误的假设
对映射进行迭代是误解和错误的常见来源,主要是因为开发人员做出了错误的假设。在本节中,
我们讨论两种不同的情况:
-
排序
-
迭代期间的映射更新
我们将看到两个基于错误假设的常见错误。
4.4.1 排序
关于排序,我们需要了解映射数据结构的一些基本行为:
此外,当迭代一个映射时,我们根本不应该做任何排序假设。让我们来看看这句话的含义。
我们将考虑图 4.5 所示的映射,由四个桶组成(元素代表键)。后备数组的每个索引引用一个给定的桶。
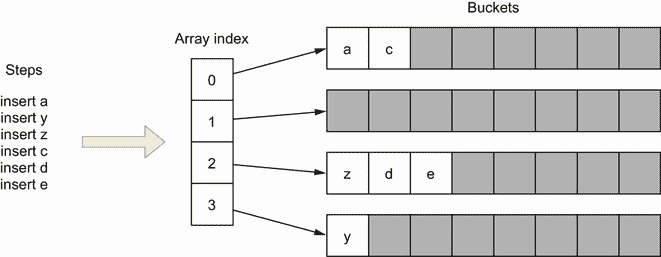
图 4.5 有四个桶的映射
现在,让我们使用一个range循环来迭代这个映射,并打印所有的键:
for k := range m {
fmt.Print(k)
}
我们提到过数据不是按键排序的。因此,我们不能期望这段代码打印出acdeyz。与此同时,我们说过映射不保留插入顺序。因此,我们也不能期望代码打印出ayzcde。
但是我们至少可以期望代码按照键当前存储在映射中的顺序打印键吧?不,这个也不行。在 Go 中,映射上的迭代顺序不是指定的。也不能保证从一次迭代到下一次迭代的顺序是相同的。我们应该记住这些映射行为,这样我们就不会把代码建立在错误的假设上。
我们可以通过运行前面的循环两次来确认所有这些语句:
zdyaec
czyade
正如我们所看到的,每次迭代的顺序都是不同的。
注意尽管迭代顺序没有保证,但迭代分布并不均匀。这就是为什么官方的 Go 规范声明迭代是未指定的,而不是随机的。
那么为什么 Go 有如此惊人的方法来迭代映射呢?这是语言设计者有意识的选择。他们想添加一些随机性,以确保开发人员在使用映射时不会依赖任何排序假设(见 mng.bz/M2JW )。
因此,作为 Go 开发者,我们不应该在迭代一个映射时对排序做任何假设。然而,让我们注意使用来自标准库或外部库的包会导致不同的行为。例如,当encoding/json包将一个映射整理到 JSON 中时,它按照键的字母顺序对数据进行重新排序,而不考虑插入顺序。但这并不是 Go映射本身的属性。如果需要排序,我们应该依赖其他数据结构,比如二进制堆(GoDS 库在 github.com/emirpasic/gods 包含有用的数据结构实现)。
现在让我们看看第二个错误,它与迭代映射时更新映射有关。
4.4.2 迭代期间的映射插入
在 Go 中,允许在迭代过程中更新映射(插入或删除元素);它不会导致编译错误或运行时错误。然而,在迭代过程中向映射中添加条目时,我们应该考虑另一个方面,以避免不确定的结果。
让我们来看看下面这个迭代一个map[int]bool的例子。如果偶对值为真,我们添加另一个元素。你能猜到这段代码的输出是什么吗?
m := map[int]bool{
0: true,
1: false,
2: true,
}
for k, v := range m {
if v {
m[10+k] = true
}
}
fmt.Println(m)
这段代码的结果是不可预测的。如果我们多次运行此代码,下面是一些结果示例:
map[0:true 1:false 2:true 10:true 12:true 20:true 22:true 30:true]
map[0:true 1:false 2:true 10:true 12:true 20:true 22:true 30:true 32:true]
map[0:true 1:false 2:true 10:true 12:true 20:true]
为了理解其中的原因,我们必须阅读 Go 规范对迭代过程中的新映射条目的描述:
如果映射条目是在迭代过程中创建的,它可能是在迭代过程中生成的,也可能被跳过。对于创建的每个条目,以及从一次迭代到下一次迭代,选择可能会有所不同。
因此,当一个元素在迭代过程中被添加到一个映射中时,它可能会在后续的迭代过程中产生,也可能不会产生。作为 Go 开发者,我们没有任何方法来强制执行这种行为。它也可能因迭代而异,这就是为什么我们三次得到不同的结果。
记住这种行为以确保我们的代码不会产生不可预测的输出是很重要的。如果我们想在迭代时更新映射,并确保添加的条目不是迭代的一部分,一种解决方案是处理映射的副本,如下所示:
m := map[int]bool{
0: true,
1: false,
2: true,
}
m2 := copyMap(m) // ❶
for k, v := range m {
m2[k] = v
if v {
m2[10+k] = true // ❷
}
}
fmt.Println(m2)
❶ 创建了初始映射的副本
❷ 更新m2而不是m
在本例中,我们将正在读取的映射与正在更新的映射分离开来。事实上,我们一直在迭代m,但是更新是在m2完成的。这个新版本创建了可预测和可重复的输出:
map[0:true 1:false 2:true 10:true 12:true]
总而言之,当我们使用映射时,我们不应该依赖以下内容:
-
数据按键排序
-
插入顺序的保留
-
确定性迭代顺序
-
在添加元素的同一次迭代中产生的元素
记住这些行为应该有助于我们避免基于错误假设的常见错误。
在下一节中,我们将看到一个在中断循环时经常犯的错误。
4.5 #34:忽略break语句的工作方式
一个break语句是常用来终止一个循环的执行。当循环与switch或select一起使用时,开发人员经常会犯破坏错误语句的错误。
让我们看看下面的例子。我们在和for循环中实现了一个switch。如果循环索引的值为2,我们想要中断循环:
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break // ❶
}
}
❶ 如果i等于 2,就break。
这段代码乍一看可能没错;然而,它并没有做我们所期望的。break语句没有终止循环:相反,它终止了语句switch。因此,这段代码不是从 0 迭代到 2,而是从 0 迭代到 4: 0 1 2 3 4。
要记住的一个基本规则是,break语句终止最里面的for、switch或select语句的执行。在前面的例子中,它终止了switch语句。
那么我们如何编写代码来打破循环而不是switch语句的?最惯用的方法是使用标签:
loop: // ❶
for i := 0; i < 5; i++ {
fmt.Printf("%d ", i)
switch i {
default:
case 2:
break loop // ❷
}
}
这里,我们将标签与for循环联系起来。然后,因为我们向break语句提供了loop标签,所以它中断了循环,而不是切换。因此,这个新版本将打印0 1 2,正如我们所料。
带标签的break是不是跟goto一样?
一些开发人员可能会质疑带有标签的break是否是惯用的,并将它视为一个花哨的goto语句。然而,事实并非如此,标准库中使用了这样的代码。例如,我们在从缓冲区读取行时,在net/http包中看到这个:
readlines:
for {
line, err := rw.Body.ReadString('n')
switch {
case err == io.EOF:
break readlines
case err != nil:
t.Fatalf("unexpected error reading from CGI: %v", err)
}
// ...
}
这个例子使用了一个带有readlines的表达性标签来强调循环的目标。因此,我们应该考虑使用标签来中断语句,这是 Go 中惯用的方法。
循环内的select也可能会中断错误的语句。在下面的代码中,我们想在两种情况下使用select,如果上下文取消,则中断循环:
for {
select {
case <-ch:
// Do something
case <-ctx.Done():
break // ❶
}
}
如果上下文取消,❶会中断
这里最里面的for、switch或select语句是的select语句,而不是for循环。因此,循环重复。同样,为了打破循环本身,我们可以使用一个标签:
loop: // ❶
for {
select {
case <-ch:
// Do something
case <-ctx.Done():
break loop // ❷
}
}
❶ 定义了一个loop标签
❷ 终止附加到loop标签的循环,而不是select
现在,正如预期的那样,break语句中断了循环,而不是select。
注意,我们也可以使用带标签的continue来进入带标签循环的下一次迭代。
在循环中使用语句switch或select时,我们应该保持谨慎。当使用break时,我们应该始终确保我们知道它将影响哪个语句。正如我们所见,使用标签是强制中断特定语句的惯用解决方案。
在本章的最后一节,我们继续讨论循环,但这次是结合关键字defer来讨论。
4.6 #35:在循环中使用defer
defer语句延迟一个调用的执行,直到周围的函数返回。它主要用于减少样板代码。例如,如果一个资源最终必须关闭,我们可以使用defer来避免在每个return之前重复关闭调用。然而,一个常见的错误是没有意识到在循环中使用defer的后果。让我们来研究一下这个问题。
我们将实现一个打开一组文件的函数,其中的文件路径是通过一个通道接收的。因此,我们必须遍历这个通道,打开文件,并处理闭包。这是我们的第一个版本:
func readFiles(ch <-chan string) error {
for path := range ch { // ❶
file, err := os.Open(path) // ❷
if err != nil {
return err
}
defer file.Close() // ❸
// Do something with file
}
return nil
}
❶ 迭代通道
❷ 打开文件
注意我们将讨论如何处理错误#54“不处理延迟错误”中的延迟错误
这种实现有一个很大的问题。我们必须回忆一下,当包围函数返回时,defer调度一个函数调用。在这种情况下,延迟调用不是在每次循环迭代中执行,而是在readFiles函数返回时执行。如果readFiles没有返回,文件描述符将永远保持打开,导致泄漏。
有什么办法可以解决这个问题?一种可能是去掉defer,手动处理文件关闭。但是如果我们那样做,我们将不得不放弃 Go 工具集的一个方便的特性,仅仅因为我们在一个循环中。那么,如果我们想继续使用defer,有哪些选择呢?我们必须围绕defer创建另一个在每次迭代中调用的周围函数。
例如,我们可以实现一个readFile函数来保存接收到的每个新文件路径的逻辑:
func readFiles(ch <-chan string) error {
for path := range ch {
if err := readFile(path); err != nil { // ❶
return err
}
}
return nil
}
func readFile(path string) error {
file, err := os.Open(path)
if err != nil {
return err
}
defer file.Close() // ❷
// Do something with file
return nil
}
❶ 调用包含主逻辑的readFile函数
❷ 延迟调用file.Close
在这个实现中,当readFile返回时,调用defer函数,这意味着在每次迭代结束时。因此,在父readFiles函数返回之前,我们不会打开文件描述符。
另一种方法是让readFile函数成为一个闭包:
func readFiles(ch <-chan string) error {
for path := range ch {
err := func() error {
// ...
defer file.Close()
// ...
}() // ❶
if err != nil {
return err
}
}
return nil
}
❶ 运行提供的闭包
但本质上,这仍然是相同的解决方案:在每次迭代中添加另一个周围函数来执行defer调用。普通的旧函数的优点是可能更清晰一点,我们也可以为它编写一个特定的单元测试。
当使用defer时,我们必须记住,当周围的函数返回时,它调度一个函数调用。因此,在一个循环中调用defer将会堆叠所有的调用:它们不会在每次迭代中执行,例如,如果循环没有终止,这可能会导致内存泄漏。解决这个问题最方便的方法是在每次迭代中引入另一个要调用的函数。但是如果性能是至关重要的,一个缺点是函数调用增加了开销。如果我们有这样的情况,并且我们想要防止这种开销,我们应该去掉defer并且在循环之前手动处理延迟调用。
总结
-
循环
range中的值元素是一个副本。因此,例如,要改变一个结构,可以通过它的索引或者通过一个经典的for循环来访问它(除非你想要修改的元素或者字段是一个指针)。 -
了解传递给
range操作符的表达式在循环开始前只计算一次,可以帮助您避免常见的错误,如通道或片迭代中的低效赋值。 -
使用局部变量或使用索引访问元素,可以防止在循环内复制指针时出错。
-
为了在使用映射时确保可预测的输出,请记住映射数据结构
- 不按键排序数据
- 不保留插入顺序
- 没有确定的迭代顺序
- 不保证在一次迭代中添加的元素会在这次迭代中产生
-
使用带标签的
break或continue强制中断特定语句。这对循环中的switch或select语句很有帮助。 -
提取函数内部的循环逻辑会导致在每次迭代结束时执行一个
defer语句。
原文地址:https://blog.csdn.net/wizardforcel/article/details/130748489
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_12653.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!