数据仓库是一个面向主题的、集成的、非易失的、随时间变化的,用来支持管理人员决策的数据集合,数据仓库中包含了粒度化的企业数据。
数据仓库的体系结构通常包含4个层次:数据源、数据存储和管理、数据服务以及数据应用。
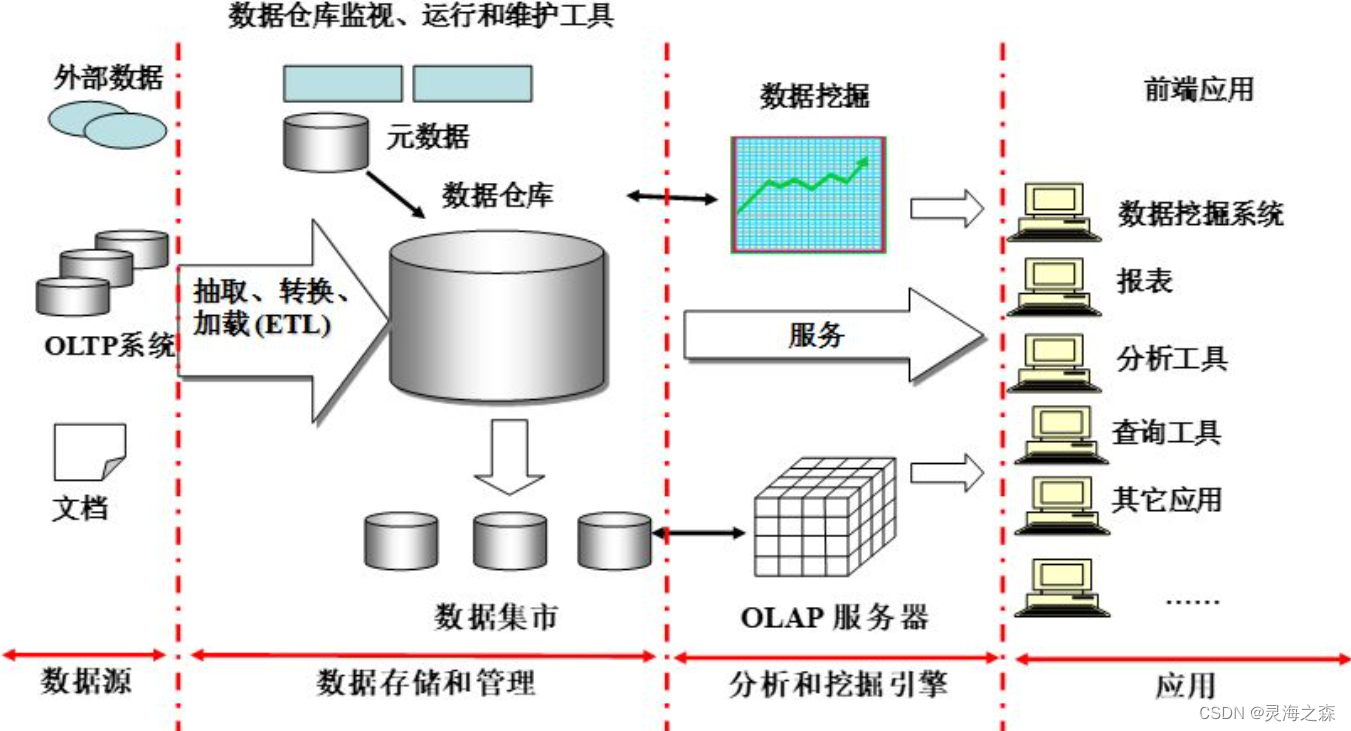
- 数据源:数据仓库的数据来源,包括外部数据、现有业务系统和文档资料等。
- 数据存储和管理:为数据提供的存储和管理,包括数据仓库、数据集市、数据仓库监视、运行与维护工具和元数据管理等。
- 数据服务:为前端工具和应用提供数据服务,包括直接从数据仓库中获取数据提供给前端使用,或者通过OLAP服务器为前端应用提供更为复杂的数据服务。
- 数据应用:直接面向最终用户,包括数据工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。
1.概述
Hive是建立在Hadoop之上的一种数仓工具。该工具的功能是将结构化、半结构化的数据文件映射为一张数据库表,基于数据库表,提供了一种类似SQL的查询模型(HQL),用于访问和分析存储在Hadoop文件中的大型数据集。
Hive本身并不具备存储功能,其核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop集群中执行。
2.数据模型
①库
MySQL中默认数据库是default,用户可以创建不同的database,在database下也可以创建不同的表。Hive也可以分为不同的数据(仓)库,和传统数据库保持一致。在传统数仓中创建database。默认的数据库也是default。Hive中的库相当于关系数据库中的命名空间,它的作用是将用户和数据库的表进行隔离。
②表
Hive中的表所对应的数据是存储在HDFS中,而表相关的元数据是存储在关系数据库中。Hive中的表分为内部表和外部表两种类型,两者的区别在于数据的访问和删除:
内部表的加载数据和创建表的过程是分开的,在加载数据时,实际数据会被移动到数仓目录中,之后对数据的访问是在数仓目录实现。而外部表加载数据和创建表是同一个过程,对数据的访问是读取HDFS中的数据;
内部表删除时,因为数据移动到了数仓目录中,因此删除表时,表中数据和元数据会被同时删除。外部表因为数据还在HDFS中,删除表时并不影响数据。
创建表时不做任何指定,默认创建的就是内部表。想要创建外部表,则需要使用External进行修饰
③分区
分区是一个优化的手段,目的是减少全表扫描,提高查询效率。在Hive中存储的方式就是表的主目录文件夹下的子文件夹,子文件夹的名字表示所定义的分区列名字。
④分桶
分桶和分区的区别在于:分桶是针对数据文件本身进行拆分,根据表中字段(例如,编号ID)的值,经过hash计算规则,将数据文件划分成指定的若干个小文件。分桶后,HDFS中的数据文件会变为多个小文件。分桶的优点是优化join查询和方便抽样查询。
3.HQL的执行
Hive在执行一条HQL语句时,会经过以下步骤:
- 语法解析:Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree;
- 语义解析:遍历AST Tree,抽象出查询的基本组成单元QueryBlock;
- 生成逻辑执行计划:遍历QueryBlock,翻译为执行操作树OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行OperatorTree变换,合并不必要的ReduceSinkOperator,减少shuffle数据量;
- 生成物理执行计划:遍历OperatorTree,翻译为MapReduce任务;
- 优化物理执行计划:物理层优化器进行MapReduce任务的变换,生成最终的执行计划。
参考:
https://datawhalechina.github.io/juicy-bigdata/#/ch07-Hive?id=_702-%e6%95%b0%e6%8d%ae%e4%bb%93%e5%ba%93%e6%a6%82%e5%bf%b5
原文地址:https://blog.csdn.net/qq_43814415/article/details/134629063
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_14721.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!







