本文介绍: 受到增强式检索方法的启发,作者提出了kNN-NER,通过检索训练集中k个邻居的标签分布来提高模型命名实体识别分类的准确性。该框架能够通过充分利用训练信息来解决样本类别不平衡问题。本文提出的框架是在标签分类上进行处理,整体思想很简单,在训练集中选取相似词的标签情况来调整结果,怎么感觉有点作弊一样?作者也提到,能提升模型的性能是因为“开卷考试比闭卷要简单”!而且通过实验可以看到作者选取的K并不小,也意味着计算量大的问题。
介绍
受到增强式检索方法的启发,作者提出了kNN-NER,通过检索训练集中k个邻居的标签分布来提高模型命名实体识别分类的准确性。该框架能够通过充分利用训练信息来解决样本类别不平衡问题。
方法
整个模型的框架如下图所示,作者提出的框架在训练阶段不需要进行额外的操作,可以适配于多样的序列标注模型:

给定一个长为n的句子,序列标注任务就是为句子中的每个单词
分配一个标签
,有N个样本的训练集表示为:
![]()
具体的,使用一个encoder(文中使用的是Bert和RoBert)来得到每个词的向量表示,然后通过一个MLP得到每个词属于每个类别的分数:



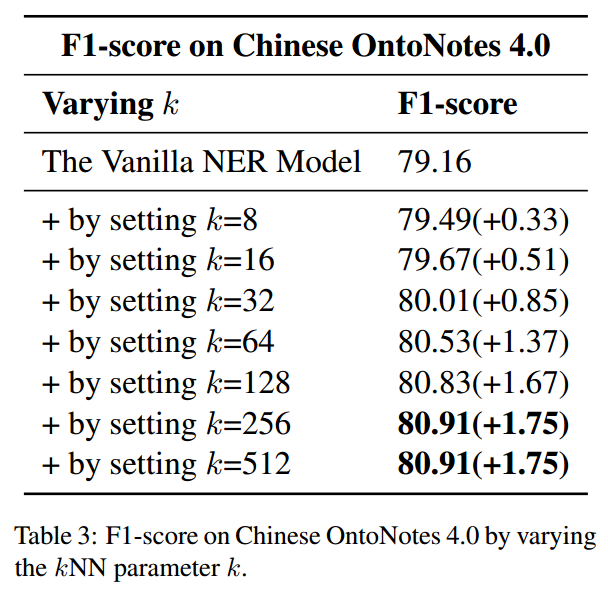
实验




总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。






