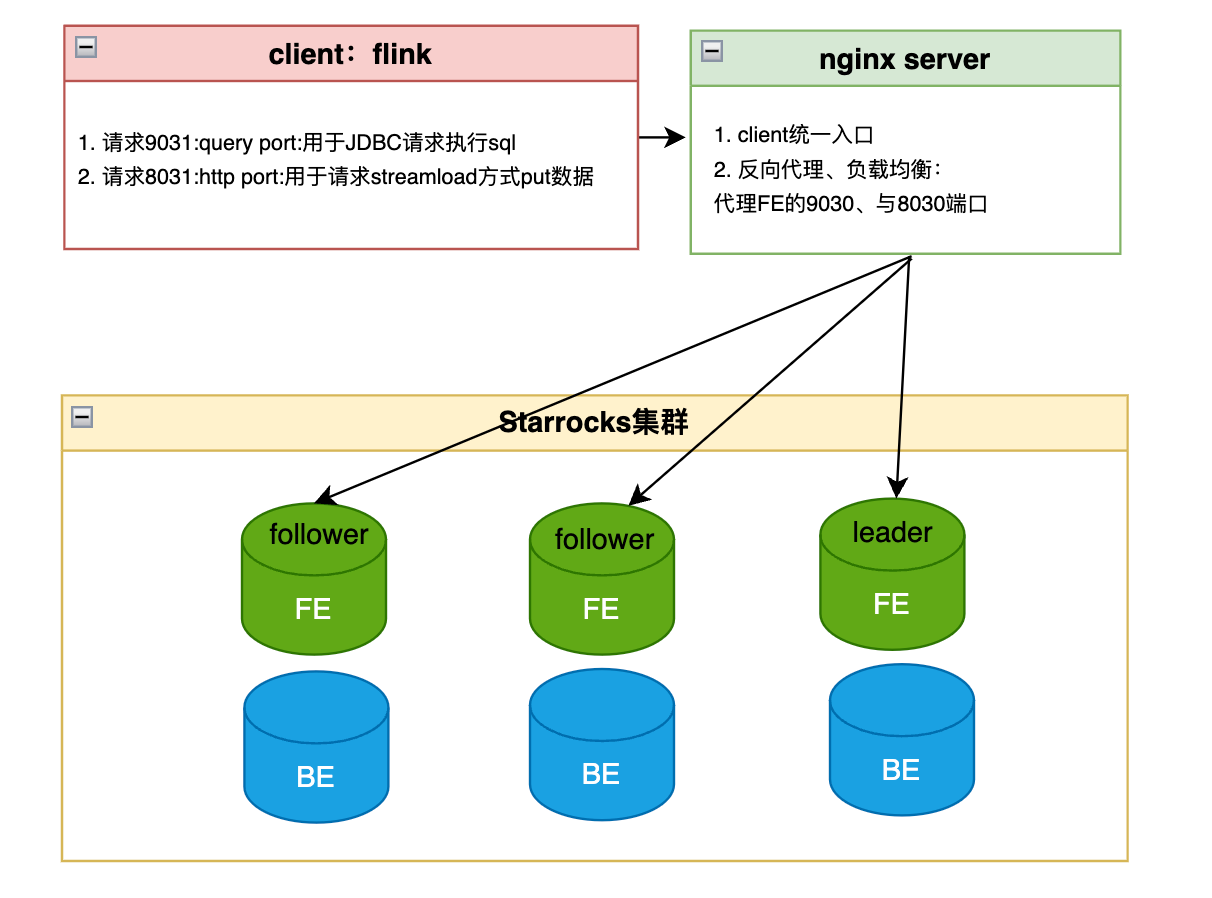
Flink 物理分区算子(Physical Partitioning)
在Flink中,常见的物理分区策略有:随机分配(Random)、轮询分配(Round-Robin)、重缩放(Rescale)和广播(Broadcast)。
接下来,我们通过源码和Demo分别了解每种物理分区算子的作用和区别。
(1) 随机分区(shuffle)
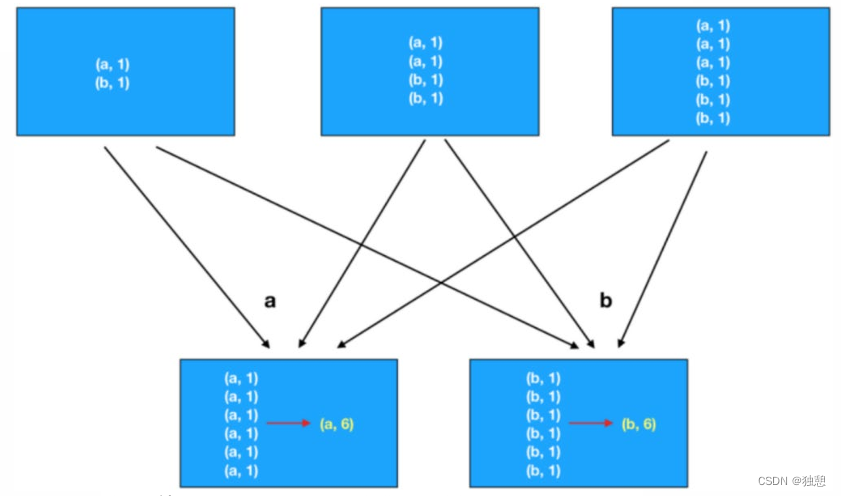
最简单的重分区方式就是直接“洗牌”。通过调用 DataStream 的.shuffle()方法,将数据随机地分配到下游算子的并行任务中去。
随机分区服从均匀分布(uniform distribution),所以可以把流中的数据随机打乱,均匀地传递到下游任务分区。因为是完全随机的,所以对于同样的输入数据, 每次执行得到的结果也不会相同。
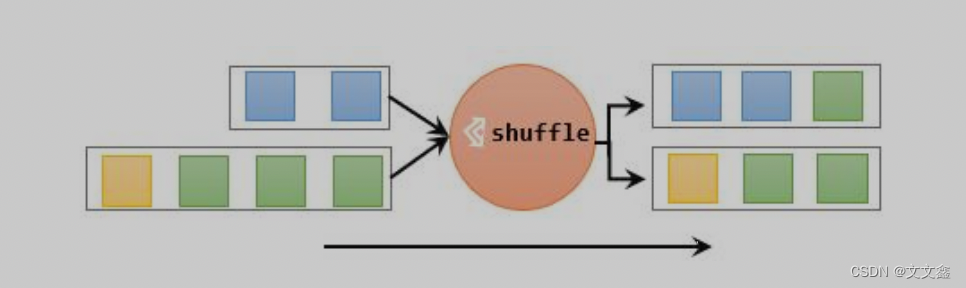

经过随机分区之后,得到的依然是一个 DataStream。
我们可以做个简单测试:将数据读入之后直接打印到控制台,将输出的并行度设置为 2,
中间经历一次 shuffle。执行多次,观察结果是否相同。
package com.flink.DataStream.PhysicalPartitioning;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* flink 常用物理分区算子-shuffle:随机分区-洗牌
*/
public class flinkShuffle {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment
.getExecutionEnvironment();
streamExecutionEnvironment.setParallelism(2);
DataStreamSource<String> socketDataStreamSource = streamExecutionEnvironment.socketTextStream("localhost", 8888);
// TODO 随机分区
socketDataStreamSource.shuffle().print();
// TODO 轮询分区
//socketDataStreamSource.rebalance().print();
// TODO 重缩放分区
//socketDataStreamSource.rescale().print();
// TODO 广播
//socketDataStreamSource.broadcast().print();
// TODO 全局分区
//socketDataStreamSource.global().print();
streamExecutionEnvironment.execute();
}
}
2> 1
2> 2
1> 3
1> 1
1> 2
2> 3
在上述实验中,我们设置全局env的并行度为2,尝试执行2次job,发现2次执行的结果不一致,因为shuffle的完全随机性,将输入流分配到不同的分区中,且每次分配可能不一样。
(2) 轮询分区(Round-Robin)
轮询,简单来说就是“发牌”,按照先后顺序将数据做依次分发。通过调用 DataStream的.rebalance()方法,就可以实现轮询重分区。
rebalance 使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去。
stream.reblance()
设置全局env的并行度为2,尝试执行3次job,发现3次执行的结果一致
1> 1
2> 2
1> 1
2> 2
1> 1
2> 2
1> 1
2> 2
(3) 重缩放分区(rescale)
重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin 算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中。
rescale 的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌。
stream.rescale()
设置全局env的并行度为2,尝试执行3次job,发现3次执行的结果一致
1> 1
2> 2
1> 1
2> 2
1> 1
2> 2
1> 1
2> 2
(4) 广播(broadcast)
这种方式其实不应该叫做“重分区”,因为经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。
可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去。
stream.broadcast()
将输入数据复制并发送到下游算子的所有并行任务中去
2> 1
1> 1
2> 2
1> 2
(5) 全局分区(global)
全局分区也是一种特殊的分区方式。这种做法非常极端,通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。
这就相当于强行让下游任务并行度变成了1,所以使用这个操作需要非常谨慎,可能对程序造成很大的压力。
stream.global()
将所有的输入流数据都发送到下游算子的第一个并行子任务中去
强行让下游任务并行度变成了1,即使你并行度设置为了2
1> 1
1> 2
1> 1
1> 2
1> 1
1> 2
原文地址:https://blog.csdn.net/dgssd/article/details/134599274
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_1625.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!