1. Kafka 架构深入了解
1.1 Kafka 工作流程及文件存储机制
Kafka 中消息是以 topic 进行分类的,生产者生产消息,消费者消费消息,都是面向 topic 的。
topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 producer 生产的数据。Producer 生产的数据会被不断追加到该 log 文件末端,且每条数据都有自己的 offset。 消费者组中的每个消费者,都会实时记录自己消费到了哪个 offset,以便出错恢复时,从上次的位置继续消费。
由于生产者生产的消息会不断追加到 log 文件末尾,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制,将每个 partition 分为多个 segment。每个 segment 对应两个文件:“.index” 文件和 “.log” 文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,test 这个 topic 有三个分区, 则其对应的文件夹为 test-0、test-1、test-2。
index 和 log 文件以当前 segment 的第一条消息的 offset 命名。
“.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数据文件中 message 的物理偏移地址。
1.2 数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后, 都需要向 producer 发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
1.3 数据一致性问题
LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,所有副本中最小的 LEO。
(1)follower 故障
follower 发生故障后会被临时踢出 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合),待该 follower 恢复后,follower 会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
(2)leader 故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader, 之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。
注:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
1.4 ack 应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡选择。
当 producer 向 leader 发送数据时,可以通过 request.required.acks 参数来设置数据可靠性的级别:
●0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。当broker故障时有可能丢失数据。
●1(默认配置):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果在follower同步成功之前leader故障,那么将会丢失数据。
●-1(或者是all):producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是如果在 follower 同步完成后,broker 发送ack 之前,leader 发生故障,那么会造成数据重复。
三种机制性能依次递减,数据可靠性依次递增。
注:在 0.11 版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。在 0.11 及以后版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据, Server 端都只会持久化一条。2. Filebeat+Kafka+ELK 的部署
ELFK架构
服务器类型 系统 IP 地址 需要安装的组件 硬件方面
Apache节点 CentOS7.4(64 位) 192.168.73.107 Logstash、Apache,filebeat 2核4G
node01节点 CentOS7.4(64 位) 192.168.73.105 Elasticsearch 、Kibana 2核4G
node02节点 CentOS7.4(64 位) 192.168.73.106 Elasticsearch, 2核4G
zookeeper+kafka
主机 操作系统 IP地址 服务的版本号
sever1 centos7.4 192.168.73.109/24 zookeeper-3.5.7
sever2 centos7.4 192.168.73.110/24 zookeeper-3.5.7
sever3 centos7.4 192.168.73.111/24 zookeeper-3.5.7
实验步骤
在前面的两篇文章中,分别部署了kafka和ELFK,本次实验承接上次实验的基础,进行
ELFK+Kafka的配置
cd /usr/local/filebeat
cp filebeat.yml filebeat.yml.bak
vim filebeat.yml
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/httpd/access_log
tags: ["access"]
- type: log
enabled: true
paths:
- /var/log/httpd/error_log
tags: ["error"]
......
#添加输出到 Kafka 的配置
output.kafka:
enabled: true
hosts: ["192.168.73.109:9092","192.168.73.110:9092","192.168.73.111:9092"] #指定 Kafka 集群配置
topic: "httpd" #指定 Kafka 的 topic
#启动 filebeat
./filebeat -e -c filebeat.yml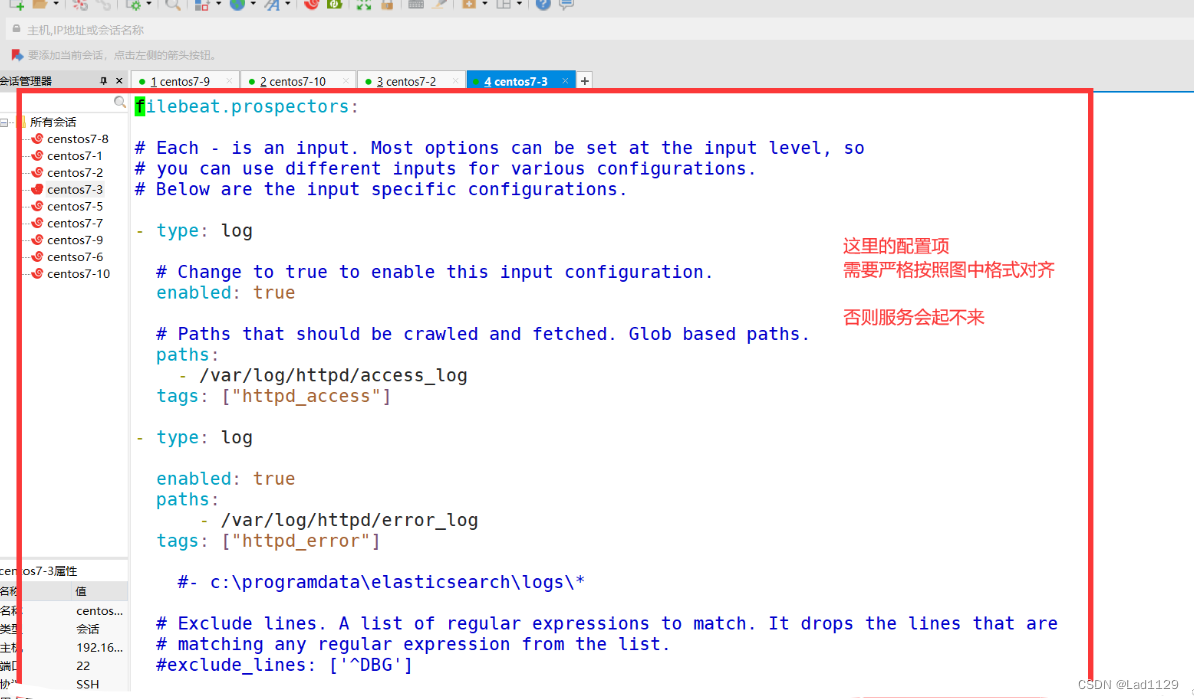
步骤二:部署 ELK,在 Logstash 组件所在节点上新建一个 Logstash 配置文件
注意:若logstash中缺少 logstash–filter–multiline,也会导致无法运行
bin/logstash-plugin install logstash-filter-multiline
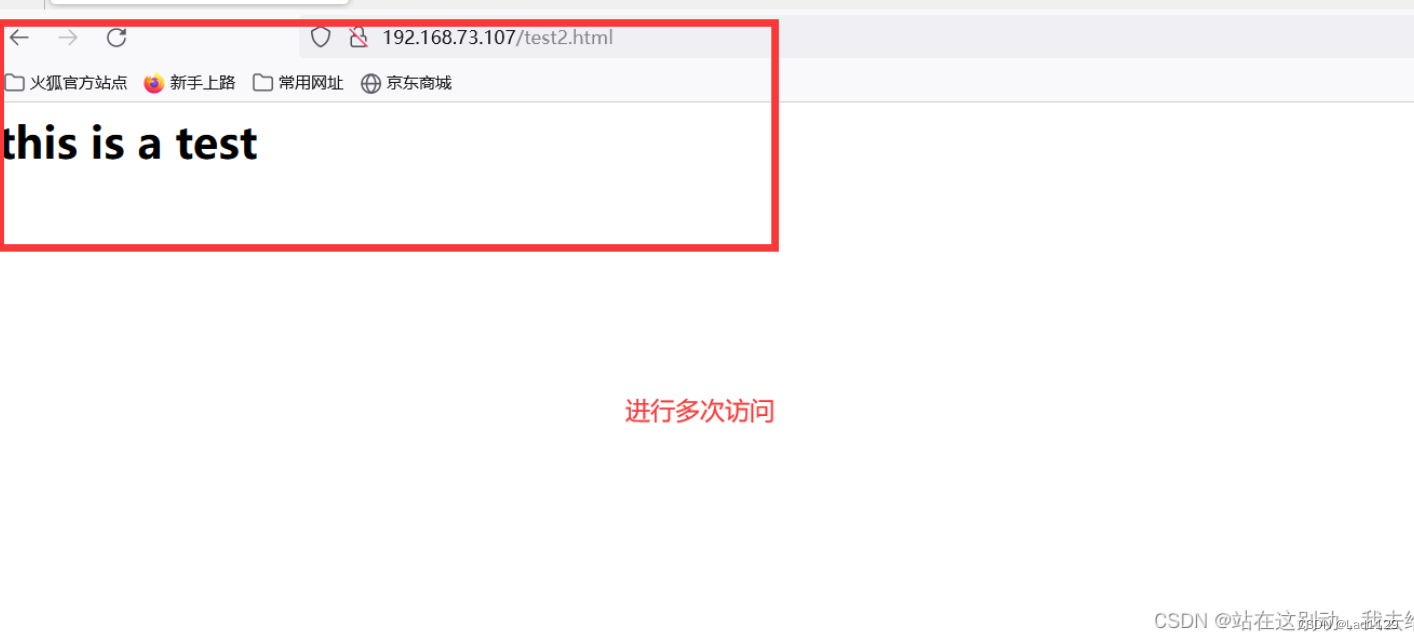
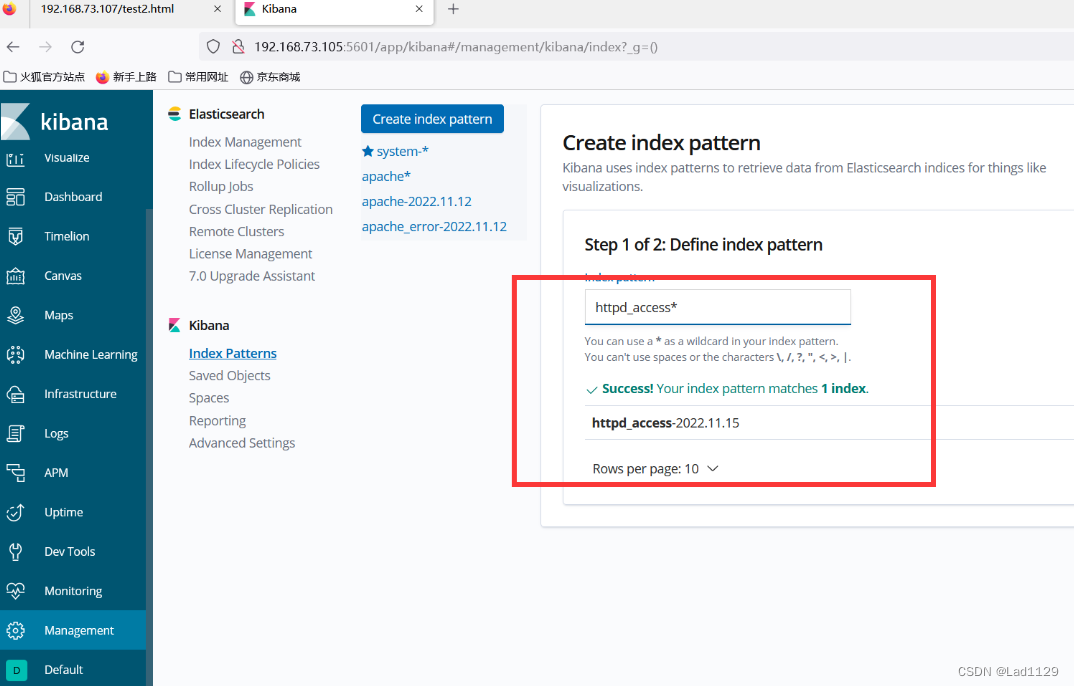
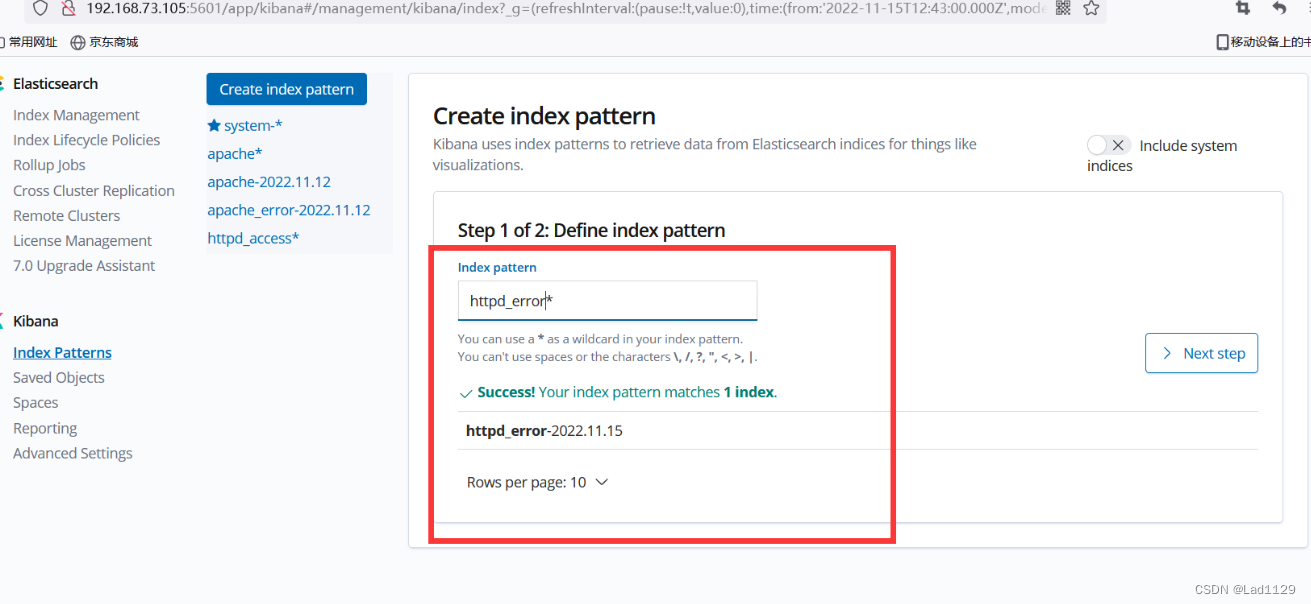
进行访问测试

原文地址:https://blog.csdn.net/qq_61843057/article/details/134720813
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_18045.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!