部分深度学习网络默认是多卡并行训练的,由于某些原因,有时需要指定在某单卡上训练,最近遇到一个,这里总结如下。
一、多卡训练
1.1 修改配置文件
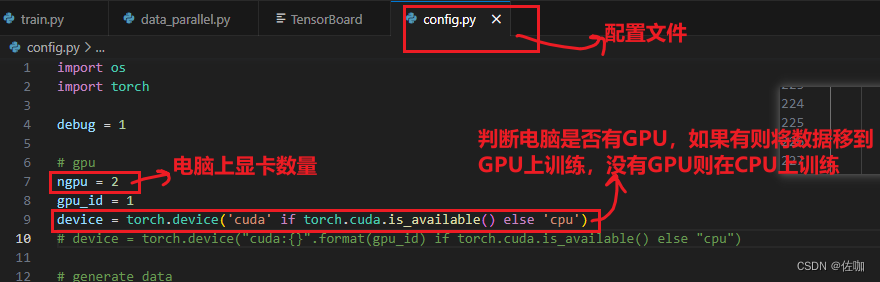
1.2 修改主训练文件
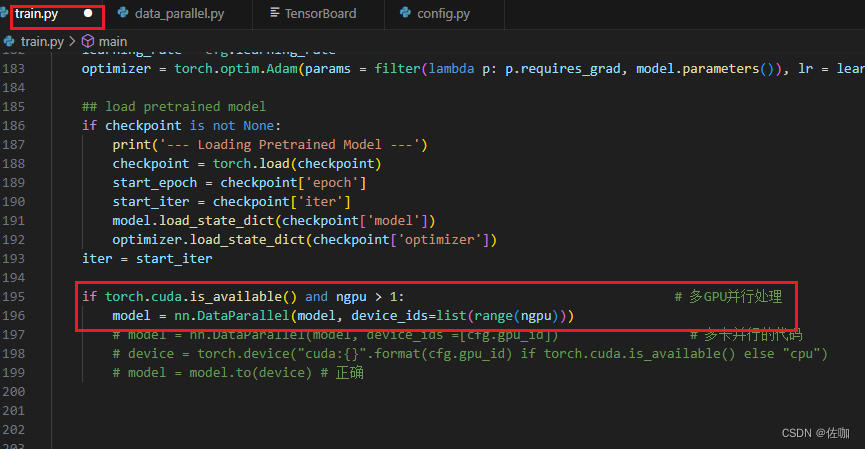
model = nn.DataParallel(model, device_ids=list(range(ngpu))):
此行代码创建了一个 DataParallel包装器,用于在多个GPU上并行处理神经网络模型。DataParallel 是 PyTorch 中的一个模块,它可以将输入数据分割并发送到不同的GPU进行处理,然后汇总结果。
1.3 显卡使用情况
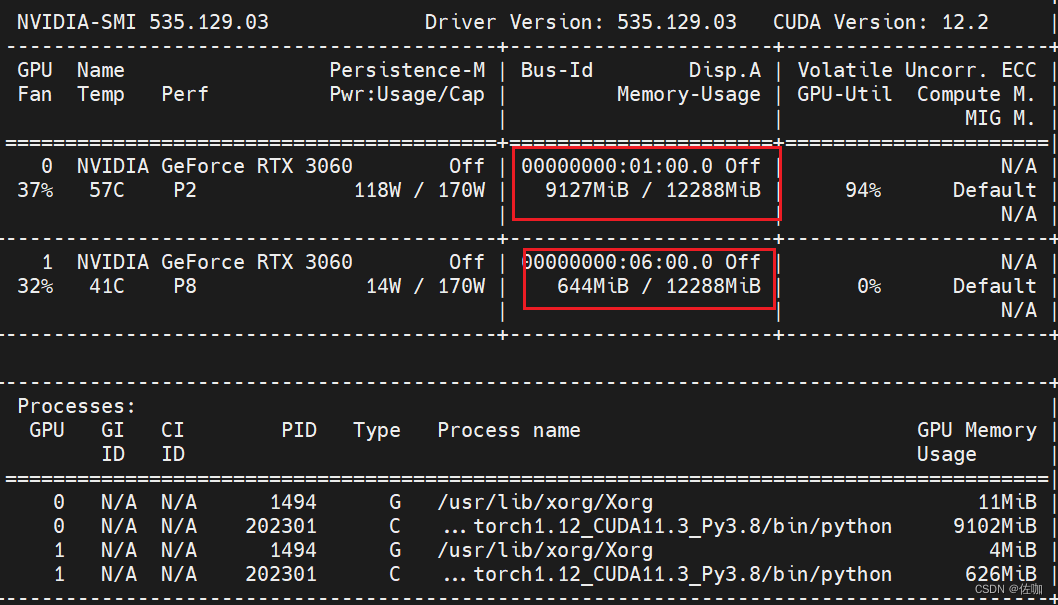
二、单卡训练
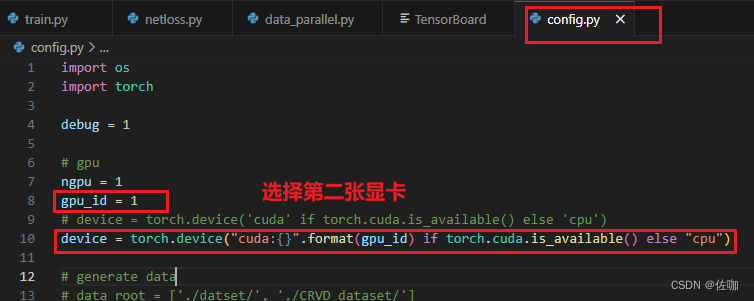
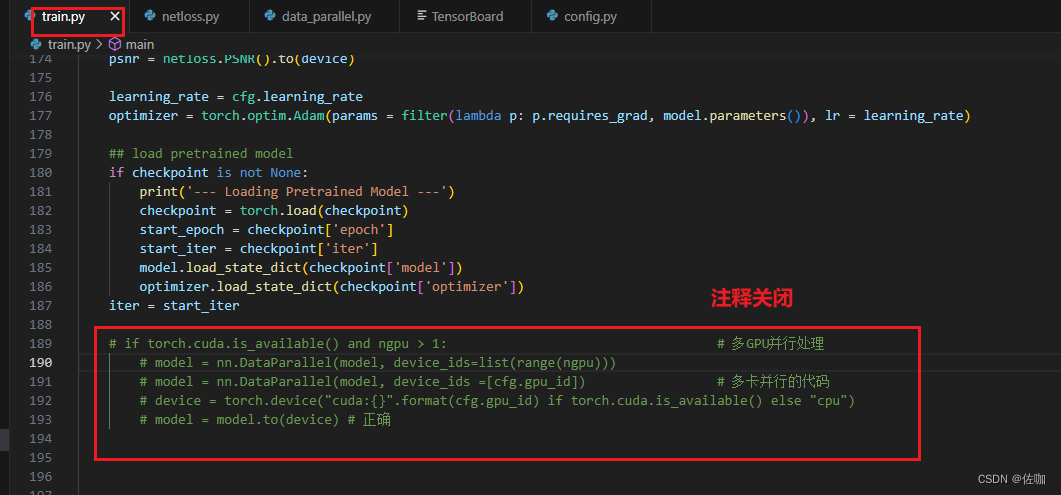
2.1 修改配置文件
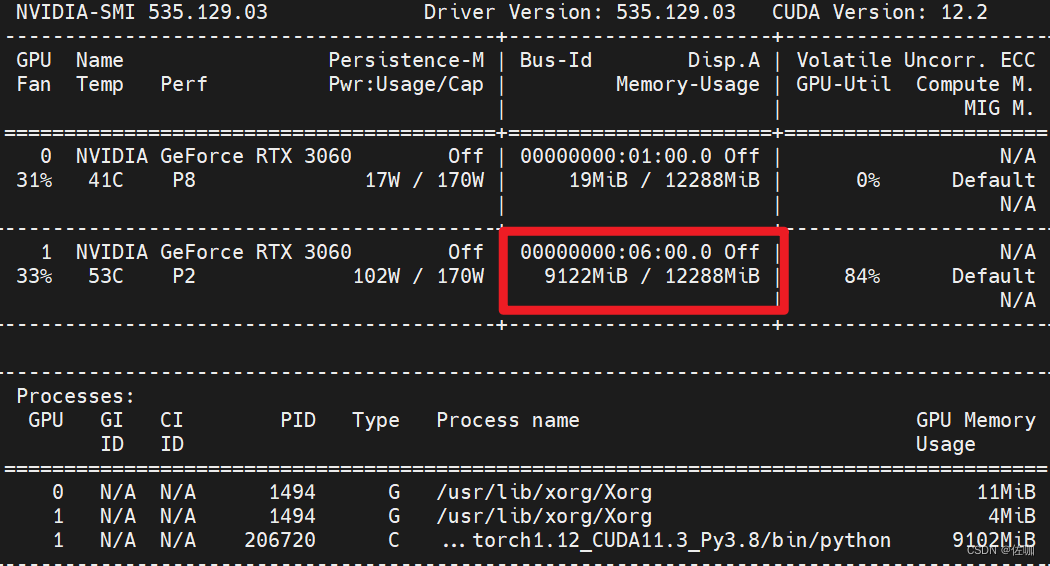
2.2 显卡使用情况
三、总结
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。