前序文章请看:
从裸机启动开始运行一个C++程序(十二)
从裸机启动开始运行一个C++程序(十一)
从裸机启动开始运行一个C++程序(十)
从裸机启动开始运行一个C++程序(九)
从裸机启动开始运行一个C++程序(八)
从裸机启动开始运行一个C++程序(七)
从裸机启动开始运行一个C++程序(六)
从裸机启动开始运行一个C++程序(五)
从裸机启动开始运行一个C++程序(四)
从裸机启动开始运行一个C++程序(三)
从裸机启动开始运行一个C++程序(二)
从裸机启动开始运行一个C++程序(一)
图形模式
我们前面章节所有的指令,都是在显卡的文字模式下运行的,通过给显存中直写字符的方式来输出文字。
照理说,保持着文字模式我们也可以进入IA-32e模式并执行64位指令,但我们最终的目标是运行C++程序,为了可以更好地发挥C++的作用,笔者打算后续用C++实现一套简单的UI绘制API,因此,咱们需要使用图形模式。
回到MBR
我们在MBR中首先有这么一段指令:
; 调用0x10号BIOS中断,清屏
mov al, 0x03
mov ah, 0x00
int 0x10
当时笔者一直将它解释位清屏,其实0x10中断的威力远不如此,al中配置的0x03其实是让显卡进入文字模式。由于我们发起此终端是让显卡重新进入了一次文字模式,因此显存会被重新初始化,进而达到的清屏的目的。
那么我们此时还可以调用这个中断,让显卡进入图形模式。当然,图形模式中有不同的分辨率、色域等等,这些需要显卡的支持。但它们有一套VGA标准模式,是所有显卡都会支持的,我们这里选择通用模式中配置最高模式,这个模式下支持320×200分辨率,256色。开启此模式的方法很简单,只需要让al为0x13,然后调用0x10中断即可开启。我们把MBR最前面的清屏指令改成下面这样:
; 开启320*200分辨率256色图形模式(此时显存0xa0000~0xaf9ff)
mov al, 0x13
mov ah, 0x00
int 0x10
由于此模式下,显存也发生了改变,所以我们把GDT中,显存对应的2号段也做对应的更改:
; 2号段
; 基址0xa0000,上限0xaf9ff,覆盖所有显存
mov [es:0x10], word 0xf9ff ; Limit=0x00f9ff,这是低16位
mov [es:0x12], word 0x0000 ; Base=0x0a0000,这是低16位
mov [es:0x14], byte 0x0a ; 这是Base的高8位
mov [es:0x15], byte 1_00_1_001_0b ; P=1, DPL=0, S=1, Type=001b, A=0
mov [es:0x16], byte 0_1_00_0000b ; G=0, D/B=1, AVL=00, Limit的高4位是0000
mov [es:0x17], byte 0 ; 这是Base的高8位
图形模式的像素点阵
当然,在此模式下,显存不再被解释为ASCII了,而是每个字节表示一个像素点的颜色。既然是一个字节,自然也就支持一共256种颜色。这256种颜色理论上可以自行通过调色盘来进行更改的,但我们为了简化问题,就使用默认的这256种颜色。
这256种颜色如下:

上图是按16×16来排布的,因此用十六进制很好找,比如说0x46就是上图中第五行的第七个颜色(0起始)。
当进入了图形模式后,原本我们写的一些g_cursor_info之类的东西肯定是都不适用了,而且也没办法直接输出文字。不过在此之前,我们还是先来验证一下是否正常启用了图形模式,咱们在主函数中设置一些像素点的颜色看看效果:
void Entry() {
for (int i = 0; i < 200; i++) {
for (int j = 0; j < 320; j++) {
int offset = i * 320 + j;
SetVMem(offset, j & 0x0f); // 纵向条纹
}
}
}

虽然看着有点晕,但至少说明我们图形模式是OK了。趁热打铁,咱们写一些工具,用于在图形模式上绘制点和矩形:
#include <stdint.h>
extern void SetVMem(long addr, uint8_t data);
// 设置画布(背景色)
void SetBackground(uint8_t color) {
for (int i = 0; i < 320 * 200; i++) {
SetVMem(i, color);
}
}
// 画一个点
void DrawPoint(int x, int y, uint8_t color) {
SetVMem(y * 320 + x, color);
}
// 画一个矩形
void DrawRect(int x, int y, int width, int length, uint8_t color) {
for (int i = 0; i < width; i++) {
for (int j = 0; j < length; j++) {
DrawPoint(x + i, y + j, color);
}
}
}
void Entry() {
// 背景设置为白色
SetBackground(0x0f);
// 画两个矩形
DrawRect(50, 30, 40, 40, 0x28); // 红色正方形
DrawRect(85, 20, 10, 30, 0x30); // 绿色条状
}
运行效果如下:
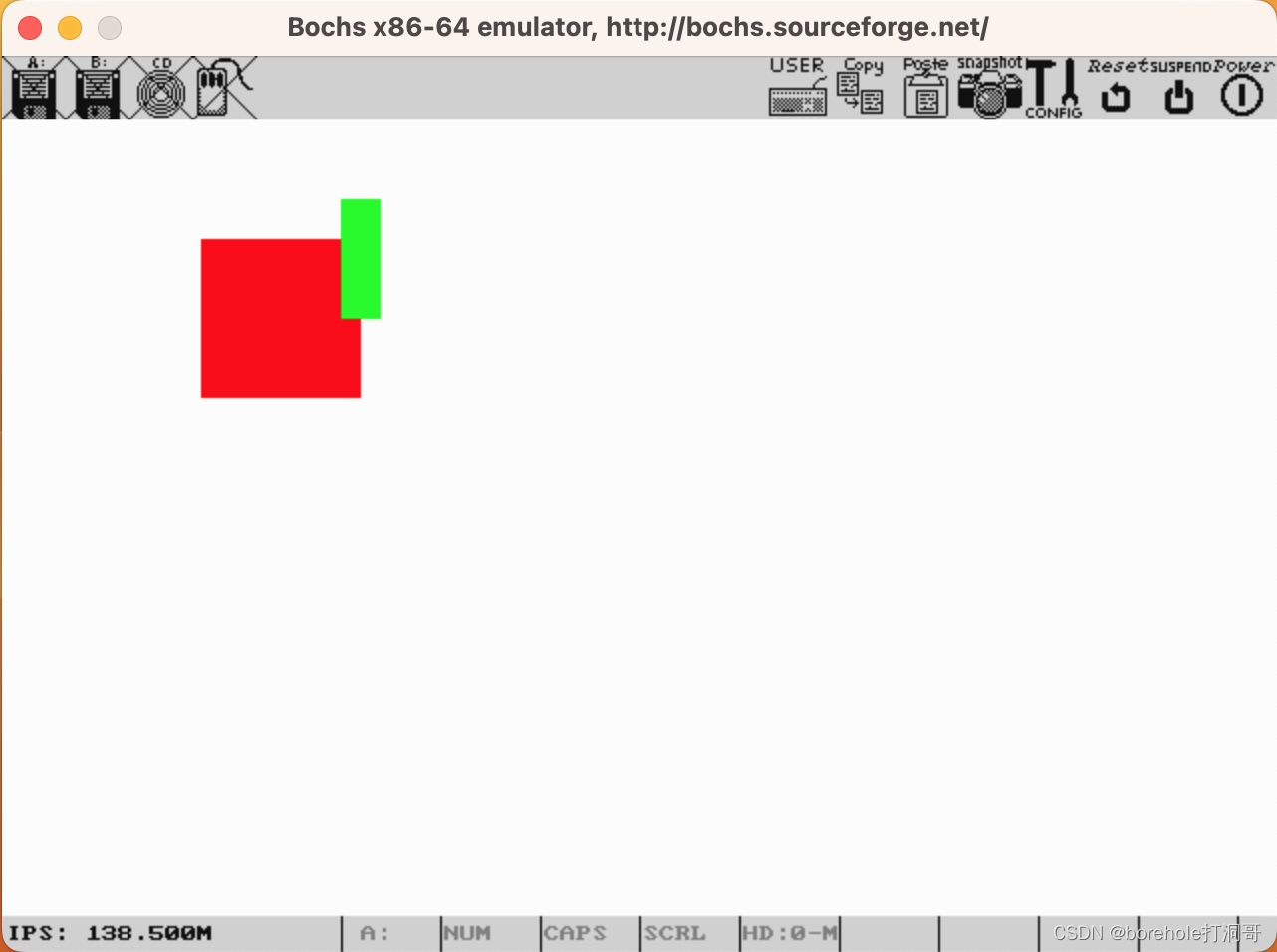
可以看到,图形之间的遮盖关系也是符合我们预期的,绿色的会覆盖红色的部分,因为它的代码更靠后。
字体文件
那么,图形模式下我们要想输出文字该怎么办?这时候就需要将文字转换为点阵集,也就是绘制字体。
举例来说,对于'A'字符,我们可以绘制一个8×16的点阵:
{
0b00000000,
0b00011000,
0b00011000,
0b00011000,
0b00011000,
0b00100100,
0b00100100,
0b00100100,
0b00100100,
0b01111110,
0b01000010,
0b01000010,
0b01000010,
0b11100111,
0b00000000,
0b00000000,
}
上面字体配置中,按照二进制位来表示当前这个像素要不要渲染。比如我们可以尝试一下:
// 绘制字符
void DrawCharacter(int x, int y, char ch, uint8_t color) {
// 目前无视ch,只绘制'A'
(void)ch;
uint8_t font[] = {
0b00000000,
0b00011000,
0b00011000,
0b00011000,
0b00011000,
0b00100100,
0b00100100,
0b00100100,
0b00100100,
0b01111110,
0b01000010,
0b01000010,
0b01000010,
0b11100111,
0b00000000,
0b00000000,
};
// 开始绘制
for (int i = 0; i < 16; i++) {
for (int j = 0; j < 8; j++) {
// 如果当前位置是否需要渲染,则设置颜色
if (font[i] & (1 << (7 - j))) {
SetVMem(x + j + (y + i) * 320, color);
}
}
}
}
void Entry() {
// 背景设置为白色
SetBackground(0x0f);
// 写个字符
DrawCharacter(50, 50, 'A', 0x30); // 绿色的A
}
运行结果如下:
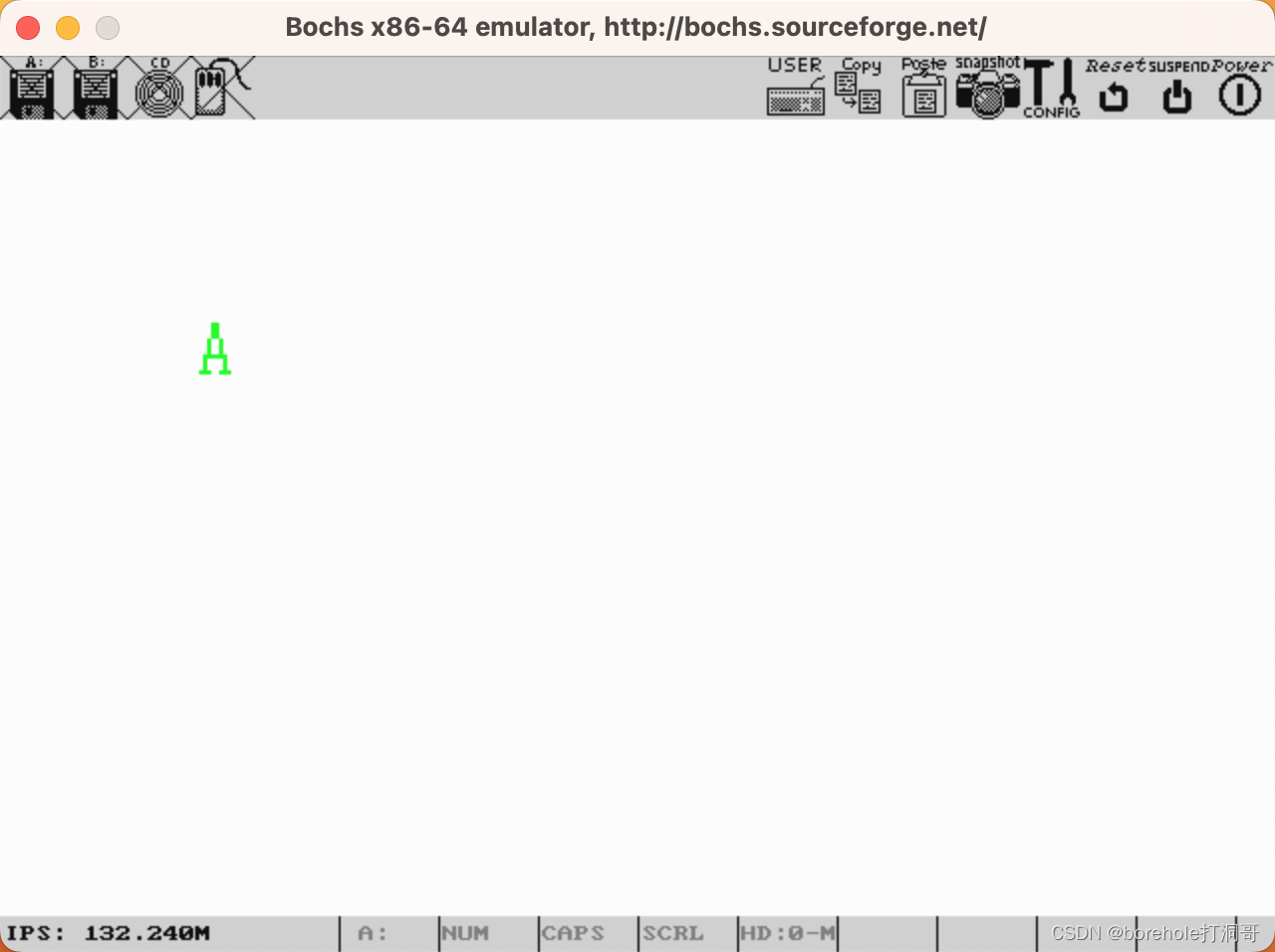
因此,如法炮制,我们只需要设置其他的字符的字体即可。这里采用这样的方法,我们在工程中添加font.c,专门用于保存所有ASCII对应的绘制字体,然后再根据此方法去改造putchar函数,即可实现在图形模式中输出文本。
这里的相关代码会放在附件中(13-1),读者可以自行取用,正文中则不再赘述。不过这里需要注意,因为字体文件比较大,所以读盘的时候要多读几个扇区,否则字体文件装载不全,已经在附件中呈现,读者请自行检验。下面是运行效果:
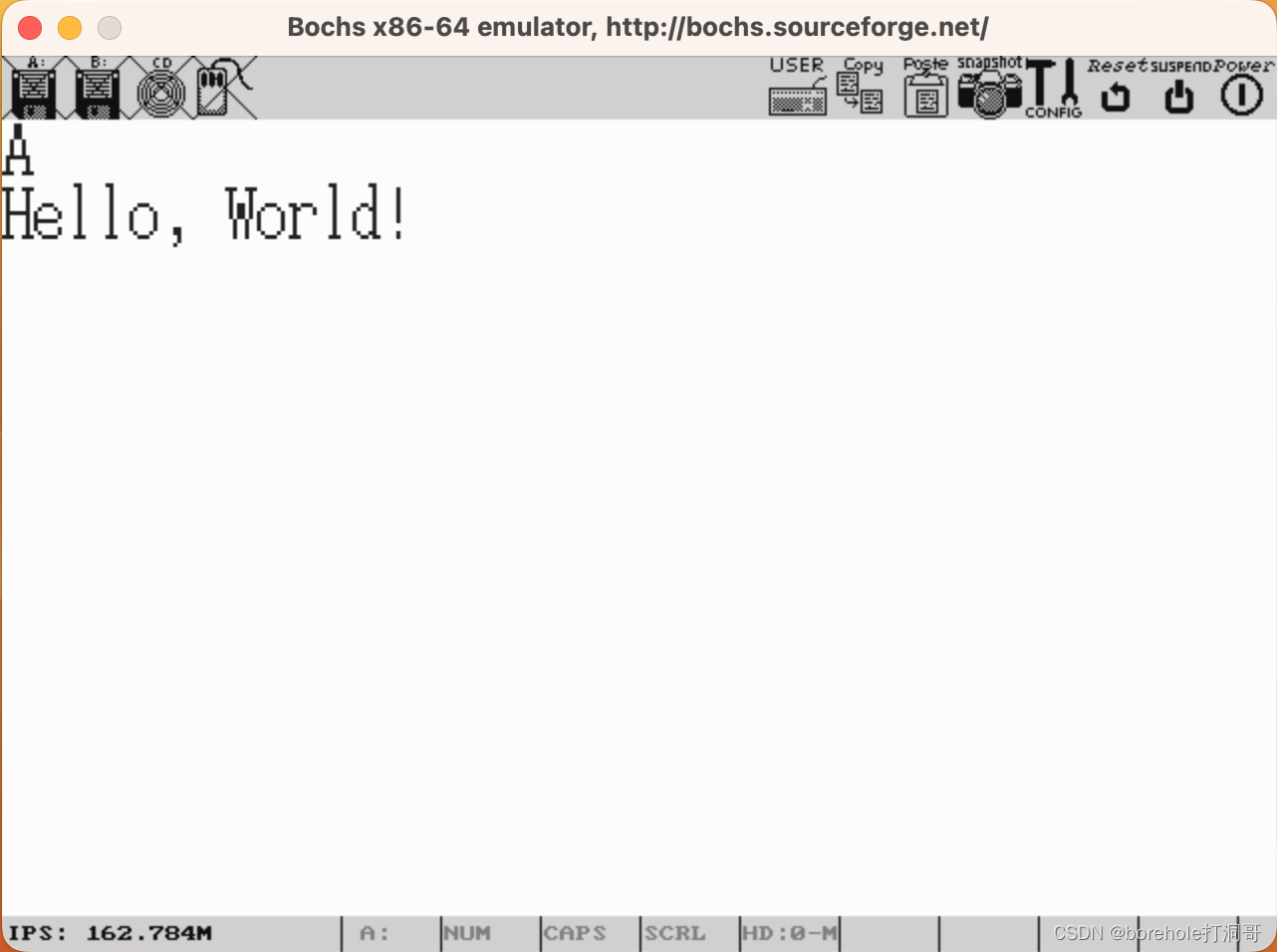
分页机制
由于咱们现在一直都是在内核态上运行程序的,并没有任何用户态进程的存在,所以可能大家并没有这种体会。但是,我们设想一下,假如我们真的写了一个成熟的操作系统,这个操作系统不可能说把自己加载完了就hlt在那里了。我们肯定是要去操作它,让它执行其他的应用程序。
但只要你去执行一个应用程序,那么就要给这个应用程序去分配必要的内存。应用程序只能访问它这一片空间,而不能够越界。我们能想到最简单的办法就是给每一个进程分一个段,等它结束时再回收这个段,以便用于以后继续分配。
但这样一来有一个问题,随着越来越多的进程运行然后释放,我们的内存可能就被划分为了许多碎片,而段的分配是连续的,假如说明明此时可用空间是够的,但是连续的可用空间不足,那就没办法分段。
所以为了解决这个问题,386引入了「页机制」,简单来说,就是让程序使用「虚拟地址」,由对应的页地址部件将其转化为物理地址后再读入内存。而这种访问方式的最小单位是4KB,被称为「页」。换句话说,物理内存中只有4KB内是连续的,页之间可能是不连续的,但在用户程序看来,却是完全连续的,因为用户程序看到的是虚拟地址。
不过研究分页机制会跟本文的主题偏离,因此我们在这里不做过于详细的展开,读者只需要知道这一机制引入的原因,以及配置方法即可,我们的目的是进入IA-32e模式,然后执行64位的指令而已,还没必要大动干戈去调度用户程序。因此这里只会简单配置一个页表,然后让程序正常运行即可。
一个页是4KB,而且要求必须是4KB对其的,也就是说页的起始位置不可以是任意的,而必须是4KB的整数倍,也就是说地址的低12位都是0。而且,既然我们要管理这些页,内核至少要知道,当前分配了哪些页,他们的物理地址在哪里,一些内部配置是什么样的。这就需要我们来维护一张「页表」。
页表
页表中应当包含页的物理地址,以及一些其他的配置项。在IA-32模式中,一个页表项占4字节,详情如下:
| 二进制位 | 符号 | 意义 |
|---|---|---|
| 0 | P | 存在位 |
| 1 | RW | 只读or可写 |
| 2 | US | 权限级别 |
| 3 | PWT | 通写 |
| 4 | PCD | 高速缓存禁止 |
| 5 | A | 访问 |
| 6 | D | 脏页 |
| 7 | PS | 页尺寸 |
| 8 | G | 全局 |
| 9-11 | AVL | 保留位 |
| 12-31 | Base(12-31) | 页首地址的12-31位 |
由于页地址要求低12位必须为0,所以页表项中也只需要记录高20位即可,剩下的那12位留给了页的配置。由于我们不涉及内核调度的问题,因此很多配置项我们都可以忽略,只需要关注P和RW即可,其它项暂且都置0就好了。
但是这里有另一个问题,32位寻址空间最多有4GB,一个页是4KB,也就是说最多我们可以有1048576个页,而每个页表项占4字节,那么光是页表都要有4194304字节,也就是4MB的空间。
而实际情况是,计算机的物理内存可能根本没有这么大,很多页是虚拟的,在不用的时候可能被操作系统写入了硬盘中,等需要时再做换页,但它的页表项却是必须在内存中的,这就活活占用了4MB的死空间。在386那个年代可能物理内存也就几MB吧,这显然是不能接受的。
于是乎,我们想了一个办法,就是把页表进行分层,首先,我只占用4KB的大小,先做一个页目录,然后页目录项在指向一个子页表,页表中再去配置实际的页。这样一来有两个好处,第一,如果我只用到一少部分的页配置,我就不用占用太多空间,因为我可以选择只配置其中一部分页表。第二,页表本身也可以作为活跃的页,跟硬盘进行交换,所以内存中只有页目录这4KB的死空间被占用而已,这个大小是比较能接受的。
另一个问题就是,一但CPU开启分页模式后,通过段寄存器和偏移地址计算出的线性地址就不再是物理地址,而是要通过页的转换成为物理地址。但咱们现在内核已经加载进去了,开启分页模式之后,我们得保证后续指令能够正常运行,就得让这时的线性地址正好等于物理地址才行,否则经过转换后地址飞了,就不能正常执行后续指令了。因此,我们至少得把低1MB的空间都分好页,并且保证这些页是连续的,正好映射到物理内存中。而1MB的空间按照每页4KB来算的话,咱们得配256个页。
页配置
接下来,我们将在kernel.nas中配置页表,至于页表的位置无所谓,你选一个没有被占用的就好了,这里我们以0x20000为例。
不过既然要在0x20000这个位置写东西,咱们就得有个段来支持才行,索性我们就配一个0x0地址起始的辅助段,方便我们操作这部分空间。在MBR中添加:
; 4号段-辅助段
; 基址0x0000,上限0xfffff
mov [es:0x20], word 0x00ff ; Limit=0x00ff,这是低16位
mov [es:0x22], word 0x0000 ; Base=0x0a0000,这是低16位
mov [es:0x24], byte 0x00 ; 这是Base的高8位
mov [es:0x25], byte 1_00_1_001_0b ; P=1, DPL=0, S=1, Type=001b, A=0
mov [es:0x26], byte 1_1_00_0000b ; G=1, D/B=1, AVL=00, Limit的高4位是0000
mov [es:0x27], byte 0 ; 这是Base的高8位
同时记得修改GDT的长度:
; 下面是gdt信息的配置(暂且放在0x07f00的位置)
mov ax, 0x07f0
mov es, ax
mov [es:0x00], word 39 ; 因为目前配了5个段,长度为40,所以limit为39
mov [es:0x02], dword 0x7e00 ; GDT配置表的首地址
回到kernel.nas,按照之前的规划,0x20000~0x20fff的位置就是我们的页目录。由于咱们只需要配256个页,所以只需要用一张页表即可覆盖,那我们就选0x21000~0x21fff作为这个页表。
那么我们在页目录的起始配一个指向0x21000位置页表的页目录项,代码如下:
; 选取0x20000作为页目录的地址
; 从0x20000开始的4096字节都是页目录
; 页目录的第一项指向一个页表
; 页表范围是0x21_000~0x21_fff
mov [es:0x20000], word 00100001_000_0_0_0_0_0_0_0_1_1b ; P=1, RW=1, US=0, PWT=0, PCD=0, A=0, D=0, G=0, PAT=0, AVL=000, Base=0x00021_000(取前20位)
然后我们再来配置这张页表,由于要分256个页,所以我们通过一个循环来计算页首地址以及写入页表项,每次循环时,页的基址应该加4KB,配置项保持不变。让低1MB的内存空间正好映射到前256个页表项中,也就是把0x0~0xfff分给0号页,0x1000~0x1fff分给1号页,以此类推。代码如下:
; 接下来要把0x21000~0x213ff范围里的256个页表项进行配置(正好对应低1MB)
mov ecx, 256
mov ebx, 0x21000 ; 页表项地址
mov edx, 0x00000_003 ; 页表配置项值,从0地址开始
.l1:
mov [es:ebx], edx
add ebx, 4
add edx, 0x0001_000 ; 相当于页物理地址+4KB
loop .l1
配置好页表项后,还需要告诉CPU我们的页目录配置在哪里了,IA-32架构的CR3寄存器就是做这件事的,它用来保存页目录首地址。
; 将页目录首地址写入CR3寄存器中
mov eax, 00100000_00000000_0_0_00b ; PCD=0, PWT=0, BASE=0x00020_000
mov cr3, eax
做好一切准备后,我们就可以开启分页模式了,开启分页模式的方法是更改CR0的第31位(也就是最高位),将其置1,然后CPU就会立即进入分页模式。
; 开启CR0的第31位(最高位)以开启分页机制
mov eax, cr0
or eax, 0x80000000
mov cr0, eax
我们保持后续所有流程不变,如果还能正常看到输出,证明我们的分页是没问题的。
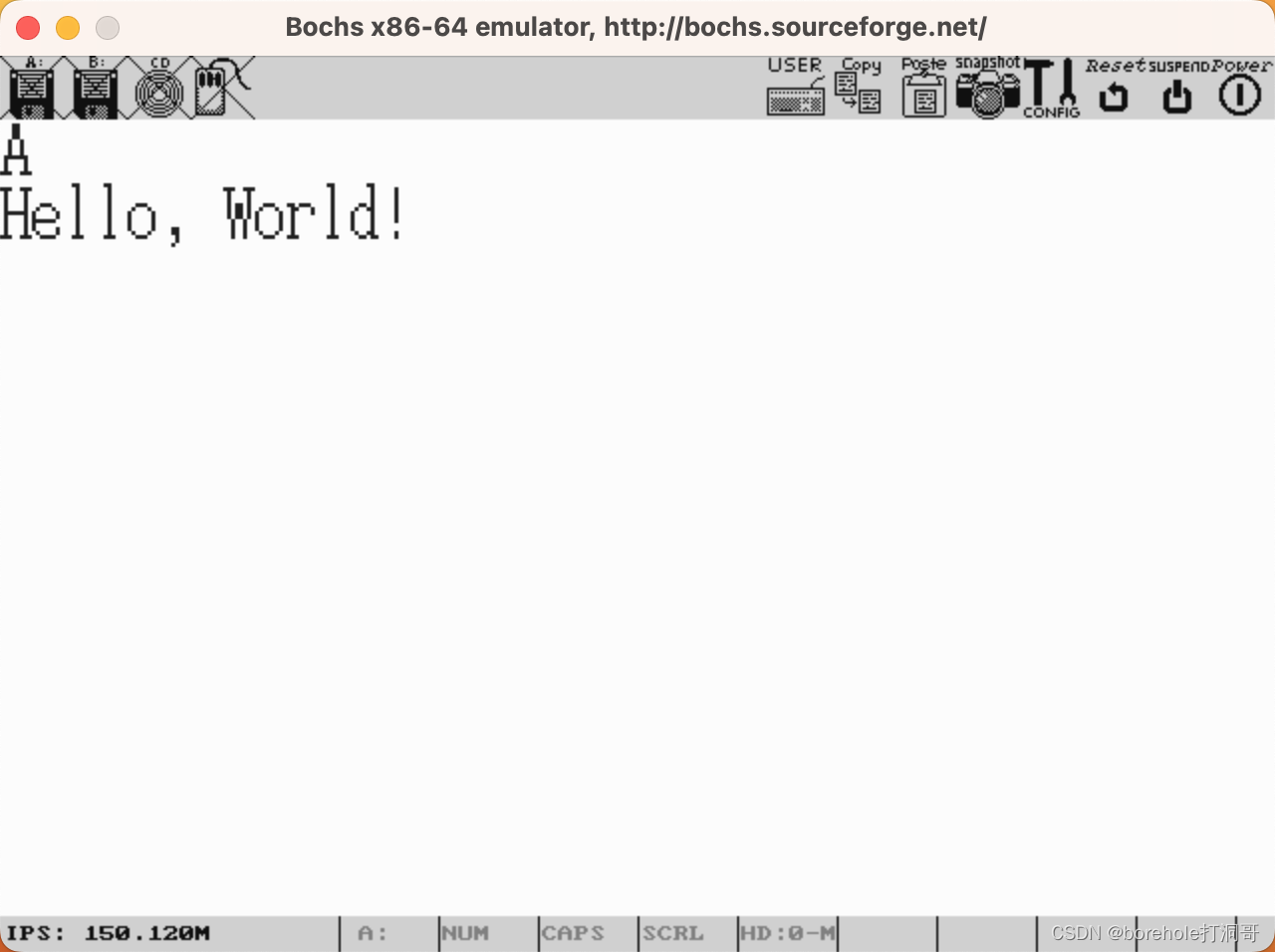
到此步为止的实例代码,笔者会放在附件中(13-2),读者可自行参考。
AMD64模式
目前咱们已经做好了万全的准备,接下来我们就是要进军64位了。在此之前我们来介绍一下相关背景知识。
IA-32e架构
笔者在前面章节曾经介绍过IA-64和AMD64的爱恨情仇,AMD64架构是由AMD最先提出,在IA-32架构的基础上进行扩展的64位指令集,向下兼容IA-32模式,但IA-64并不兼容IA-32。由于它是由IA-32模式扩展来的,并且兼容IA-32,因此这种工作模式也被称作IA-32e(IA-32 Extension)模式,或IA-32扩展模式。
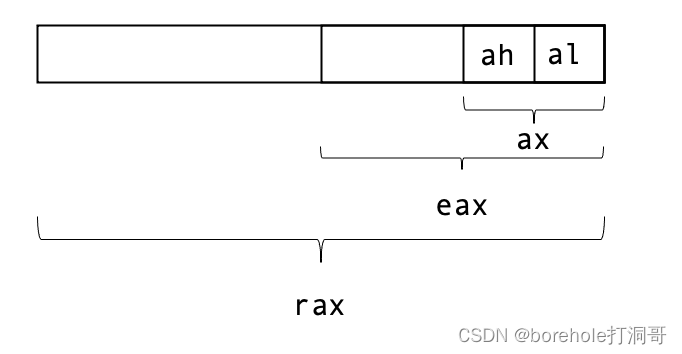
首先是硬件扩充,原本的一些寄存器被重新扩展至64位,并以r开头(re-extend,再次扩展的意思),例如rax,它的低32位就是eax。除此之外,该架构还额外提供了8个通用寄存器,分别命名为r8~r15。它们也可以拆出32位寄存器来用,例如r8的低32位是r8d,低16位是r8w,低8位是r8b。
rax,rbx,rcx,rdx寄存器结构示意图如下:
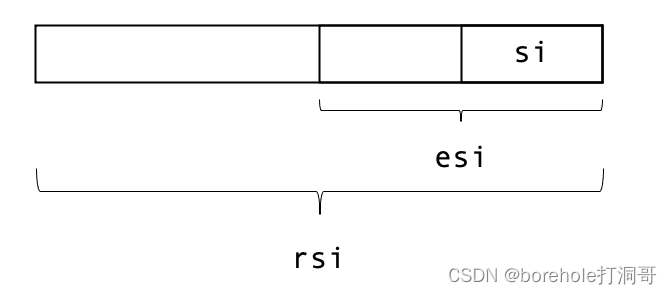
r8~r15寄存器结构示意图如下:
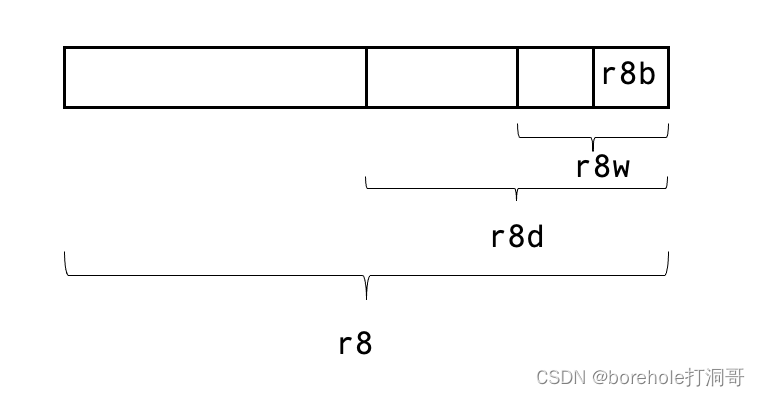
相信大家用起来都不会太陌生。与此同时,ip也扩展位rip,用于加载64位指令。
接下来的问题就是,如何使CPU进入IA-32e模式,并执行64位指令?这里还有一段路程要走,大家稍安勿躁。
4层分页
我们知道IA-32e模式是要支持64位指令的,同时也拥有理论64位的寻址空间,最大支持16EB的内存空间。倘若说这玩意我们还是按4KB来分页,页表又要炸掉了。由于要支持64位地址,因此这时的页表项也被扩充到8字节,低12位的含义不变,只是向上多扩展了32位用于表示页地址的。也正因如此,现在一个页表里最多只能配512个页了,页表更加得炸。
所以,之前的2层分页就不满足要求了,IA-32e模式提供了4层分页的方式,顾名思义就是从最初的页目录到最后的页表最多有4级。这4层分别被叫做PML4,PDPT,PDT,PT。
刚才我用了「最多」这个词,也就是说,我们不一定真的分4层,也可以在2层或者3层就截止,再哪层截止决定了页的大小。
这里的逻辑是,假如我们真的配置到了PT层,那么它指向的页就是4KB的,正常来说PDT层的项应当指向一个PT层表才对,但如果这时我们不让他再继续分级,而是直接指向页的话,这个页的大小就是2MB(相当于这2MB不再细分成512个4KB的页了,而是直接作为一个页)。
同理,如果我们直接在PDT层就直接指向页的话,那么这一个页就是1GB,相当于1GB不再细分成512个2MB的页。
那么如何表示当前页表项是指向实际页呢,还是指向下一个层级的页表呢?这就用到了PS位,当PS为1时,表示它指向下一级页表,为0时表示直接指向页。
由于我们当前就利用前1MB的空间就够了,所以,咱们就选择按2MB大小分页,这样只需要分1个页就够用了,所以,我们配置页表只到PDT层,并且这一层里只需要配一个页表项,让它的物理地址是0x0起始的就够了。代码如下:
; IA-32e模式下使用4级分页,PML4-PDPT-PDT-PT
; 这种模式下的页目录项、页表项都是8字节,高52位是物理地址
; 如果在PDPT上就设PS=1的话,实际上只分2层,每页1GB
; 如果在PDT上就设PS=1的话,实际上只分3层,每页2MB
; 到了PT上PS必须设为1(因为此模式最多支持4层),每页4KB
; 这里就将0x00000~0x1FFFFF这2MB的空间放到首个页结构项中
; PML4
mov [es:0x20000], dword 0x21003 ; P=1, RW=1, PS=0(表示有下级页表), Base=0x21_000
mov [es:0x20004], dword 0
; PDPT
mov [es:0x21000], dword 0x22003 ; P=1, RW=1, PS=0(表示有下级页表), Base=0x22_000
mov [es:0x21004], dword 0
; PDT
mov [es:0x22000], dword 0x83 ; P=1, RW=1, PS=1(不再有下级页表,所以直接按2MB分页), Base=0x0,大小2MB
mov [es:0x22004], dword 0
; 将页目录首地址写入CR3寄存器中
mov eax, 00100000_00000000_0_0_00b ; PCD=0, PWT=0, BASE=0x00020_000
mov cr3, eax
与此同时,我们现在的页表项是按8字节一项来配置的,这件事得让CPU知道,不然它还是按4字节作为一项来解析的话就麻烦了。这时我们需要将CR4的第5位置1,表示「开启64位地址扩展的分页模式」,代码如下:
; 开启CR4的第5位,开启64位地址扩展的分页模式
mov eax, cr4
or eax, 0x20
mov cr4, eax
进入IA-32e模式
在操作CR0开启分页模式之前,我们还需要通知CPU开启IA-32e模式,毕竟咱们刚才配置的这种4层分页模式在i386模式下是不支持的,所以开启分页模式之前,还要先开启IA-32e模式的标记位,这样CPU才能知道,开启分页模式的同时,改用IA-32e模式。
在IA-32e架构下,有一些扩展的寄存器,它们并没有像CR0这样直接集成到指令集中(这就是它区别于IA-64的地方,虽然扩充到了64位,但仍旧保持对IA-32的高度兼容),而是通过独立编址的方式,利用特殊的指令来操作,这些寄存器称为MSR(Modelspecific Register, 模式指定寄存器)。我们现在要操作的寄存器叫做EFER(Extended FeatureEnable Register, 扩展功能开启寄存器),它的第8位表示开启长模式(long mode,大家姑且认为这个跟IA-32e模式等价)。代码如下:
; 读取EFER(Extended FeatureEnable Register)
mov ecx, 0xc0000080 ; rdmsr指令要求将需要读取的寄存器地址放在ecx中
rdmsr ; 读取结果会放在eax中
or eax, 0x100 ; 设置第8位,LME(Long Mode Enable)
wrmsr ; 将eax的值写入ecx对应地址的寄存器
准备工作做完以后,我们就可以操作CR0来开启分页模式了,与此同时,CPU也会进入IA-32e模式:
; 开启CR0的第31位(最高位)以开启分页机制
mov eax, cr0
or eax, 0x80000000
mov cr0, eax
; 此时也会进入IA-32e模式
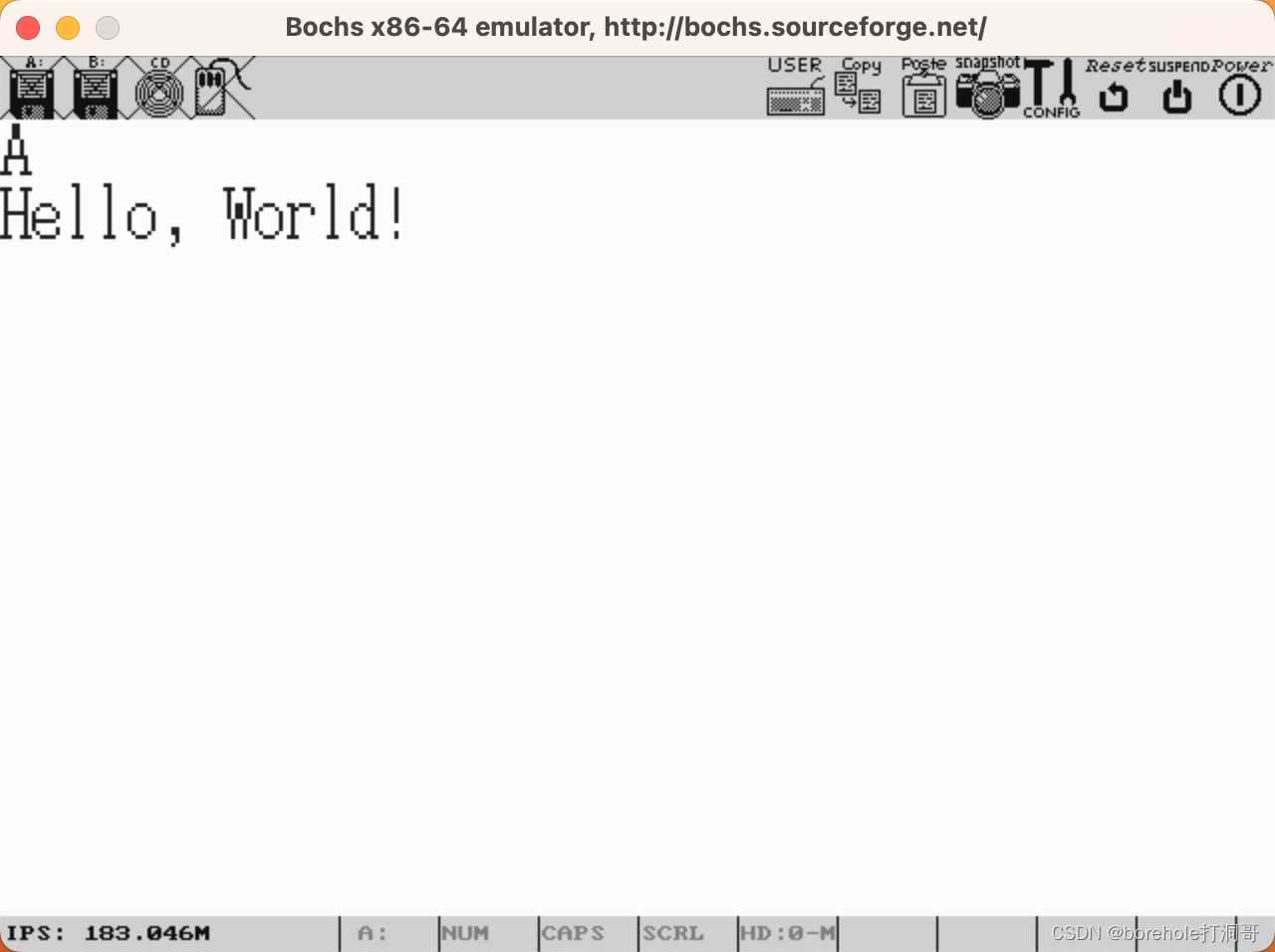
没有问题!我们成功在IA-32e模式中配置了页表,并运行了内核程序。
等等……为什么这里能运行成功呢?进入IA-32e模式后难道不应该切换到64位指令集吗?为什么我们32位的Kernel还能正常运行?不知道读者到这里会不会有这样的疑问。
这就是IA-32e模式的伟大之处了,因为它可以完全兼容原本的IA-32指令,所以即使我们已经进入了IA-32e模式,它也能正常执行后续所有的IA-32指令。
那究竟如何真正地运行64位指令呢?这是我们下一章要研究的内容。
小结
本篇我们为进入64位模式做足了前战准备。首先讲解了进入图形模式的方法并在这个模式下输出图像和文字;之后讲解了分页的概念和配置方法,并针对IA-32e模式的4层分页方式做了讲解;最后成功进入了IA-32e模式,同时也体验了在IA-32e模式下无感知运行IA-32架构的指令。
本篇所有的项目源码将会通过附件的方式(demo_code_13)上传,供读者参考。
下一篇,我们会介绍IA-32e架构的独有64位指令,和执行指令的方法,还会把之前写的C语言代码改用64位方式编译,并与内核进行适配。
原文地址:https://blog.csdn.net/fl2011sx/article/details/134504842
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_3188.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!