本文中redis版本6.2.8,其中展现的为一些常见的配置项。
redis.conf中文翻译版本我已经发到另一篇博文山了:Redis6.2.8配置文件redis.conf中文翻译版本_mr__bai的博客-CSDN博客
一、Units单位
开头定义了一些基本的度量单位,只支持bytes,不支持bit

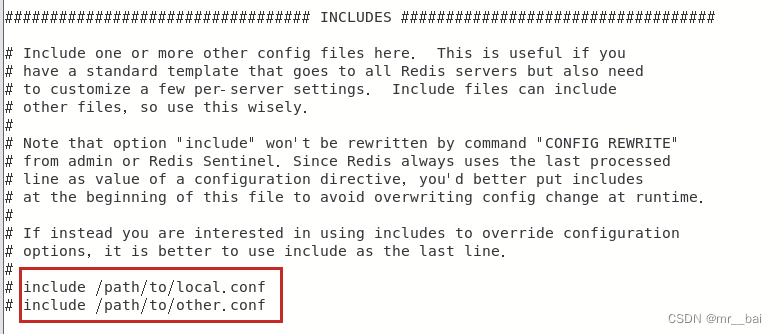
二、INCLUDES(包含配置)
Redis只有一个配置文件,如果多个人进行开发维护,那么就需要多个这样的配置文件,这时候多个配置文件就可以在此通过 include /path/to/local.conf 配置进来,而原本的 redis.conf 配置文件就作为一个总闸。
环境中使用的 redis.conf 可以包含其他的 redis.conf。解开红框处的注释,被引入的配置文件会整合成一个配置文件来使用。另外需要注意的时,如果将此配置写在redis.conf 文件的开头,那么后面的配置会覆盖引入文件的配置,如果想以引入文件的配置为主,那么需要将 include 配置写在 redis.conf 文件的末尾。
在使用redis主从复制,搭建集群的时候,这个配置通常都会使用到。也就是说多个redis实例的时候是可以把公共的配置文件提取出来然后再用include来进行引入的。
三、NETWORK(网络配置)
这里大体分为4项配置,其实注释里描述的挺清楚,好奇的可以自行百度翻译,或者查看我的中文翻译版本。Redis6.2.8配置文件redis.conf中文翻译版本_mr__bai的博客-CSDN博客
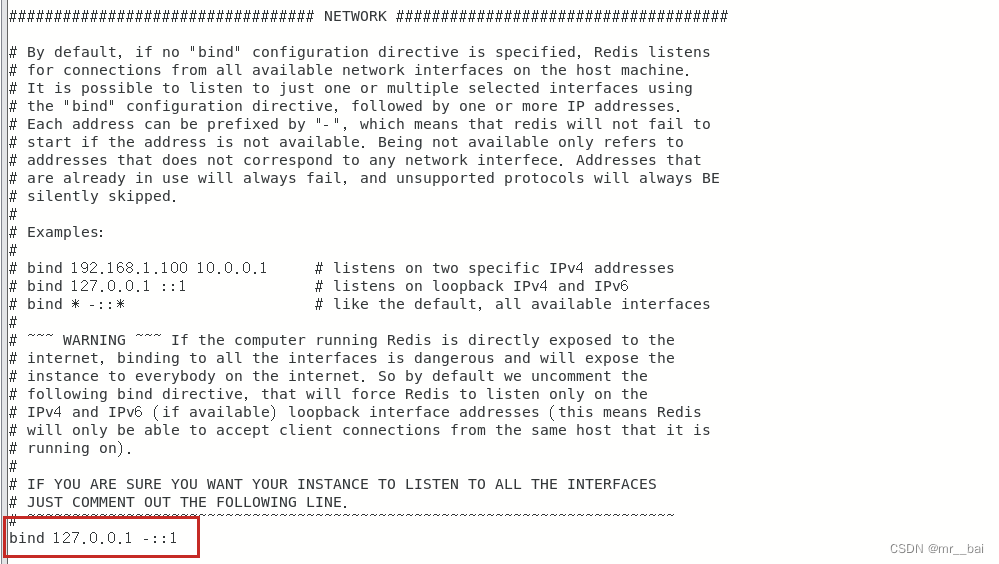 bind:这项配置绑定的IP并不是远程访问的客户端的IP地址,而是本机的IP地址,默认127.0.0.1,即本地回环地址。这样的话,访问redis服务只能通过本机的客户端连接,而无法通过远程连接。如果bind选项为空的话,那会接受所有来自于可用网络接口的连接。
bind:这项配置绑定的IP并不是远程访问的客户端的IP地址,而是本机的IP地址,默认127.0.0.1,即本地回环地址。这样的话,访问redis服务只能通过本机的客户端连接,而无法通过远程连接。如果bind选项为空的话,那会接受所有来自于可用网络接口的连接。
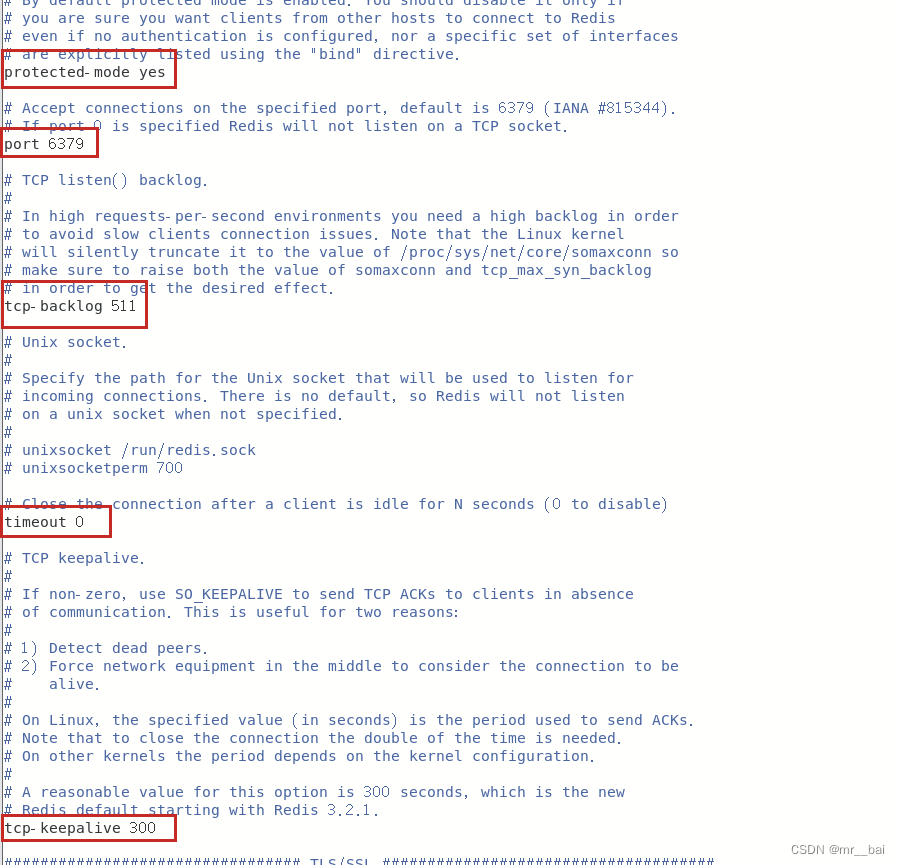 protected–mode:在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应。只有当您确定希望来自其他主机的客户端连接到Redis时,才应该禁用它。
protected–mode:在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的响应。只有当您确定希望来自其他主机的客户端连接到Redis时,才应该禁用它。
port:指定redis运行的端口,默认是6379。由于Redis是单线程模型,因此单机开多个Redis进程的时候会修改端口。如果指定端口0,Redis将不会侦听TCP套接字。
tcp–backlog:设置tcp的backlog,backlog其实是一个连接队列,backlog队列总和=未完成三次握手队列 + 已经完成三次握手队列。在高并发环境下你需要一个高backlog值来避免慢客户端连接问题。注意Linux内核会将这个值减小到/proc/sys/net/core/somaxconn的值(128),所以需要确认增大/proc/sys/net/core/somaxconn和/proc/sys/net/ipv4/tcp_max_syn_backlog(128)两个值来达到想要的效果。
timeout:设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接。默认值为0,表示永不关闭。
tcp–keepalive:对访问客户端的一种心跳检测,每隔n秒检测一次,避免服务器一直阻塞,官方给出的建议值是300s,如果设置为0,则不会周期性的检测。建议设置为60。
四、GENERAL(总则)
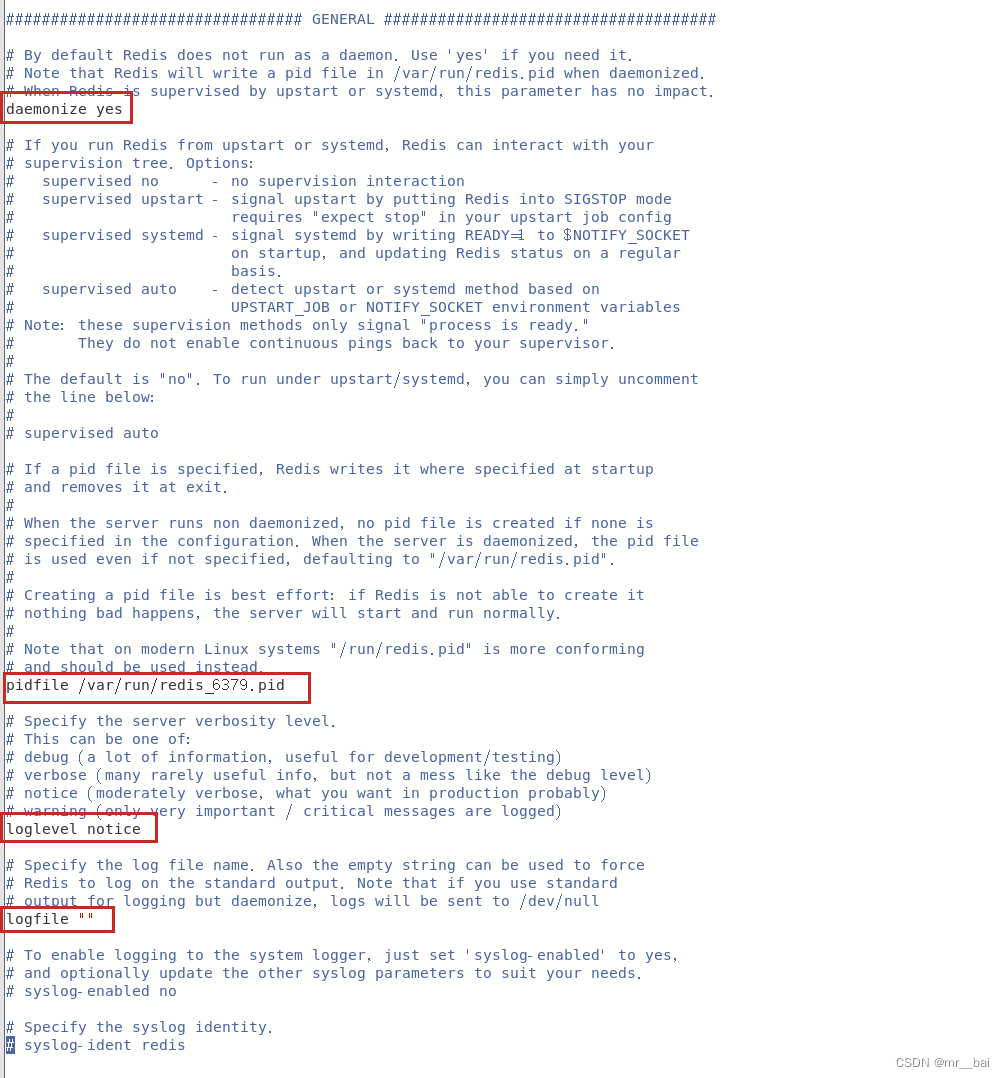
daemonize:设置为yes,表示指定Redis以守护进程的方式启动(后台启动)。默认值为 no
pidfile:配置PID文件路径,当redis作为守护进程运行的时候,它会把 pid 默认写到 /var/redis/run/redis_6379.pid 文件里面。每个实例会产生一个不同的pid文件
loglevel:定义日志级别。默认值为notice,有如下4种取值:
logfile:配置log文件地址,默认打印在命令行终端的窗口上。
databases:设置数据库的数目,默认16。默认的数据库是DB 0 ,可以在每个连接上使用select <dbid> 命令选择一个不同的数据库,dbid是一个介于0到databases-1 之间的数值。默认值是 16,也就是说默认Redis有16个数据库,dbid介于0-15。
五、SNAPSHOTTING(拍摄快照)
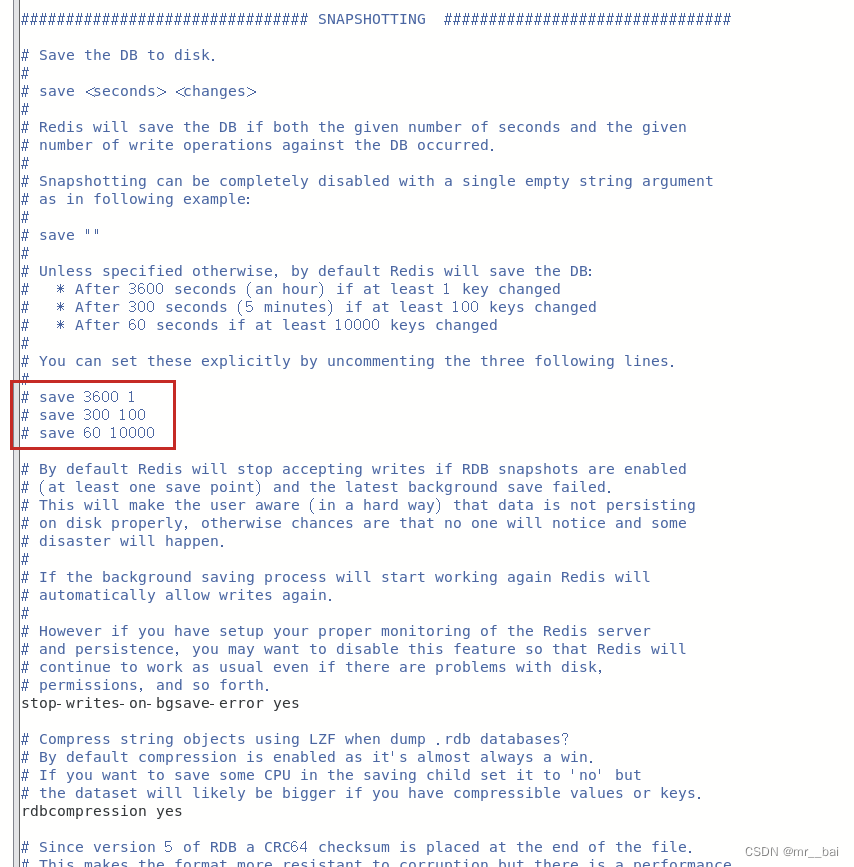
sava:这里是用来配置触发 Redis的持久化条件,也就是什么时候将内存中的数据保存到硬盘。默认如下配置:
save 3600 1 # 表示3600 秒内如果至少有 1 个 key 的值变化,则保存
save 300 100 # 表示300 秒内如果至少有 100 个 key 的值变化,则保存
save 60 10000 # 表示60 秒内如果至少有 10000 个 key 的值变化,则保存stop–writes-on-bgsave–error:默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。
rdbcompression:默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
rdbchecksum:默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
dbfilename:设置快照的文件名,默认是 dump.rdb
dir:设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。使用上面的 dbfilename 作为保存的文件名。
六、REPLICATION(复制)
slave–serve-stale-data:默认值为yes。当一个 slave 与 master 失去联系,或者复制正在进行的时候,slave 可能会有两种表现:
yes :slave 仍然会应答客户端请求,但返回的数据可能是过时,或者数据可能是空的在第一次同步的时候。
no :在你执行除了 info he salveof 之外的其他命令时,slave 都将返回一个 “SYNC with master in progress” 的错误。
slave–read–only:配置Redis的Slave实例是否接受写操作,即Slave是否为只读Redis。默认值为yes。
repl-diskless–sync:主从数据复制是否使用无硬盘复制功能。默认值为no。
repl-diskless–sync–delay:当启用无硬盘备份,服务器等待一段时间后才会通过套接字向从站传送RDB文件,这个等待时间是可配置的。 这一点很重要,因为一旦传送开始,就不可能再为一个新到达的从站服务。从站则要排队等待下一次RDB传送。因此服务器等待一段 时间以期更多的从站到达。延迟时间以秒为单位,默认为5秒。要关掉这一功能,只需将它设置为0秒,传送会立即启动。默认值为5。
repl-disable–tcp–nodelay:同步之后是否禁用从站上的TCP_NODELAY 如果你选择yes,redis会使用较少量的TCP包和带宽向从站发送数据。但这会导致在从站增加一点数据的延时。 Linux内核默认配置情况下最多40毫秒的延时。如果选择no,从站的数据延时不会那么多,但备份需要的带宽相对较多。默认情况下我们将潜在因素优化,但在高负载情况下或者在主从站都跳的情况下,把它切换为yes是个好主意。默认值为no。
警告:RDB无盘加载是实验性的。由于在这种设置中,从库不会立即将RDB存储在磁盘上,因此在故障切换期间可能会导致数据丢失。RDB无盘加载+不处理I/O读取的Redis模块也可能导致Redis在与主机的初始同步阶段发生I/O错误时中止。只有当你知道自己在做什么时才使用。
七、SECURITY(安全)

也可以在命令中设置密码,只是临时的。重启redis服务器,密码就还原了。
config get requirepass
config set requirepass "123456"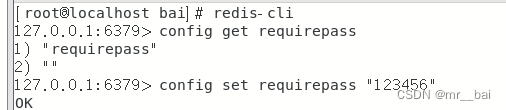
八、CLIENTS(客户端)

maxclients:设置客户端最大并发连接数,默认无限制(注释未放开),Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件。如果设置 maxclients为0 ,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息。
九、MEMORY MANAGEMENT(存储器管理)
将内存使用限制设置为指定的字节数。建议必须设置,否则,将内存占满,造成服务器宕机。

maxmemory:设置Redis的最大内存,如果设置为0 ,表示不作限制。通常是配合maxmemory–policy参数一起使用。
maxmemory–policy:当内存使用达到maxmemory设置的最大值时,redis使用的内存清除策略。如何选择要删除的内容,可以从以下行为中选择一种:
volatile-lru: 使用LRU算法移除key,只对设置了过期时间的键;(最近最少使用)
allkeys-lru: 在所有集合key中,使用LRU算法移除key
volatile-random: 在过期集合中移除随机的key,只对设置了过期时间的键
allkeys–random:在所有集合key中,移除随机的key
volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
noeviction noeviction: 不进行移除。针对写操作,只是返回错误信息。默认选项。
maxmemory–samples:设置样本数量。LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小,redis默认会检查这么多个key并选择其中LRU的那个。一般设置3到7的数字,数值越小样本越不准确,但性能消耗越小。
十、APPEND ONLY MODE(仅追加模式)
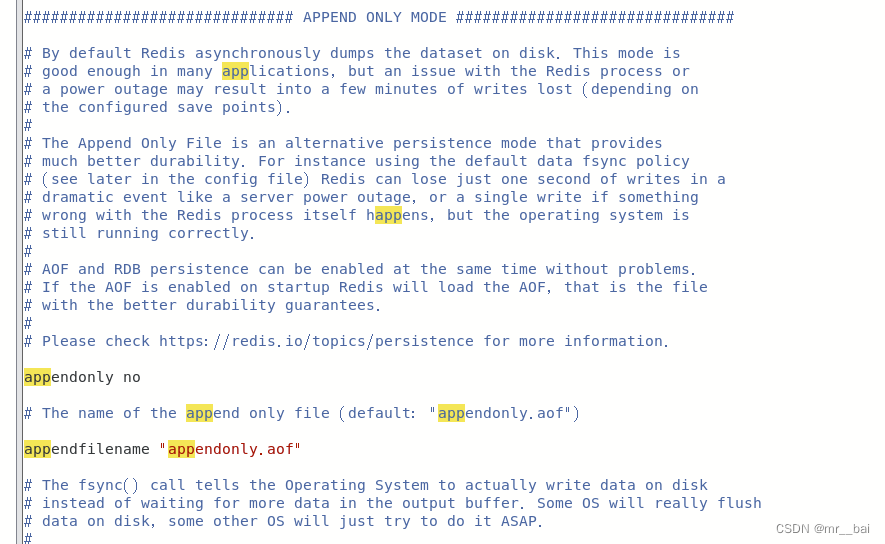
appendonly:默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式, 可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入appendonly.aof文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。默认值为no。
appendfilename :aof文件名,默认是”appendonly.aof”
appendfsync:aof持久化策略的配置;no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快;always表示每次写入都执行fsync,以保证数据同步到磁盘;everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
no-appendfsync-on-rewrite:在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,默认为no,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。
auto-aof-rewrite–percentage:默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。
auto-aof-rewrite–min–size:64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
aof-load–truncated:aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,出现这种现象 redis宕机或者异常终止不会造成尾部不完整现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-check-aof修复AOF文件才可以。默认值为 yes。
十一、LUA SCRIPTING(脚本)
lua–time–limit:一个lua脚本执行的最大时间,单位为ms。默认值为5000。如果达到了最长执行时间,Redis将记录脚本在最长允许时间后仍在执行,并将开始回复带有错误的查询。
十二、REDIS CLUSTER(REDIS集群)
正常的Redis实例不能是Redis集群的一部分;只有作为群集节点启动的节点才能。
cluster–enabled:集群开关,默认是不开启集群模式。
cluster–config–file:集群配置文件的名称,每个节点都有一个集群相关的配置文件,持久化保存集群的信息。 这个文件并不需要手动配置,这个配置文件有Redis生成并更新,每个Redis集群节点需要一个单独的配置文件。请确保与实例运行的系统中配置文件名称不冲突。默认配置为nodes-6379.conf。
cluster–node–timeout :可以配置值为15000。节点互连超时的阀值,集群节点超时毫秒数
cluster–slave–validity-factor :可以配置值为10。在进行故障转移的时候,全部slave都会请求申请为master,但是有些slave可能与master断开连接一段时间了, 导致数据过于陈旧,这样的slave不应该被提升为master。该参数就是用来判断slave节点与master断线的时间是否过长。判断方法是:比较slave断开连接的时间和(node–timeout * slave-validity-factor) + repl-ping-slave-period 如果节点超时时间为三十秒, 并且slave-validity-factor为10,假设默认的repl-ping-slave-period是10秒,即如果超过310秒slave将不会尝试进行故障转移
cluster–migration-barrier :可以配置值为1。master的slave数量大于该值,slave才能迁移到其他孤立master上,如这个参数若被设为2,那么只有当一个主节点拥有2 个可工作的从节点时,它的一个从节点会尝试迁移。
cluster–require–full–coverage:默认情况下,集群全部的slot有节点负责,集群状态才为ok,才能提供服务。 设置为no,可以在slot没有全部分配的时候提供服务。不建议打开该配置,这样会造成分区的时候,小分区的master一直在接受写请求,而造成很长时间数据不一致。
原文地址:https://blog.csdn.net/mr__bai/article/details/128661246
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。
如若转载,请注明出处:http://www.7code.cn/show_35104.html
如若内容造成侵权/违法违规/事实不符,请联系代码007邮箱:suwngjj01@126.com进行投诉反馈,一经查实,立即删除!






